HDFS对象存储服务:Ozone的元数据管理
前言
HDFS作为一套成熟的分布式存储系统,它能够存储TB甚至,PB规模级别的数据。依托于如此强大的存储能力,目前越来越多的公司、企业已经开始将越来越多的数据往HDFS上迁移。但是当数据量达到一定规模,HDFS不见得能承受的了。可能有人有疑问了,刚刚不是说HDFS能支撑PB规模级别的数据吗,这不是自相矛盾的说法了?其实笔者在这里想说的是元数据管理会受到瓶颈,HDFS面对如此巨大的元数据信息,凭借单单一个NameNode,是肯定撑不住。目前NameNode对于存储在HDFS内的所有文件、目录信息都存在于它的内存中。很显然,这是一个瓶颈点,当里面的文件数量越来越多的时候,NameNode所在节点的内存迟早会被撑爆的。笔者曾经在工作中发现这样一组有趣的数据:当集群内大约有1.5亿个Block块时的时候,NameNode使用的内存达到了64GB,启动的时间竟然达到10分钟以上(加载fsimage+apply editlog)。所以在这种情况下,NameNode是很容易被触发GC操作的。所以HDFS的小文件问题是很多人比较头疼的问题。往往我们再使用HDFS作数据存储时,不会特意关注其中的细节,有的时候程序写了一堆小文件进去,我们都不知道。久而久之,NameNode会维护一堆这样无效的文件信息在内存里。当然笔者本文不是讨论什么HDFS小文件问题解决方案的,而是打算介绍HDFS目前在做的一个对象存储服务Ozone的元数据管理机制。可以这么说,Ozone的原型设计在一定程度上吸取了NameNode元数据管理上的一些教训,而且它就是用来方便用户存储各式各样的小文件数据的。因为笔者最近一段时间在帮社区做Ozone方面的工作,所以这两天系统地梳理了一下,相信下面的阐述会对大家有所收获。Ozone的概念
这里还是得先介绍一下Ozone的概念。Ozone是什么?用来做什么的?与现有的HDFS有什么区别?
首先Ozone的定义从它的JIRA(HDFS-7240)名称就可以知道了:Object store in HDFS.笔者用最简单的一句话来概括Ozone的用途:在HDFS内部做了一个类似AWS的S3对象存储服务,内部定义的API基本也是类似的。但是有一点需要注意,Ozone功能不是在现有的NameNode-DataNode体系中做的,而是独立搞的一套,只是共用了DataNode服务。具体的架构体系笔者之前介绍过,这里内容就略去了,可见文章:HDFS对象存储--Ozone架构设计。
Ozone存储概念定义
在Ozone体系内,提供存储单元的是容器(Container)的概念,这些Container是在DataNode中被划分出来的,每个Container有size大小,如果一个DataNode没有空间了,也就分配不出Container了。这些Container同样拥有副本的概念,也会形成Pipeline。所以从这个层面上讲,Ozone体系下的Container完全类似于以前HDFS下的Block概念。然后这些DataNode中的容器会被一个叫做SCM(StorageContainerManager)的服务所管理。下面为相关的结构图
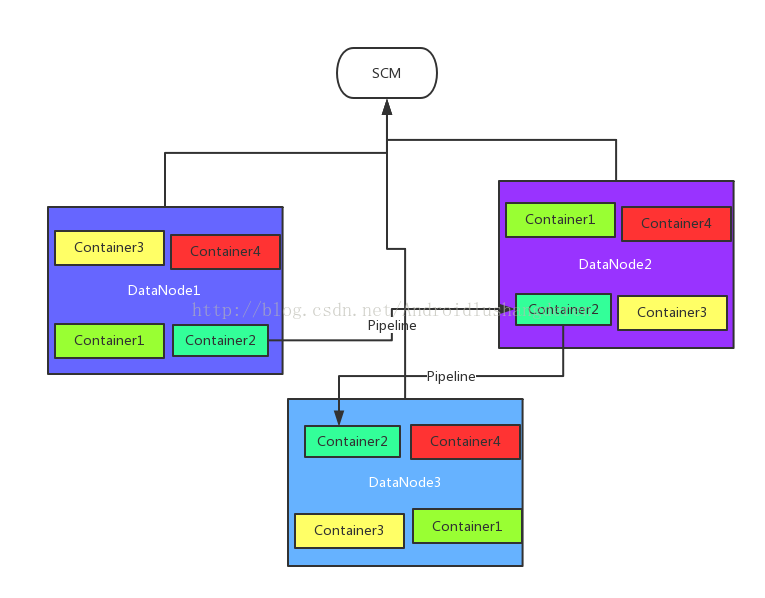
可能有人比较好奇,这里Container如何存储数据呢?我们继续往下看。
在真正进行数据写入时,在Container内部会分配出Block,一个Block对应一个Key。这个Key就是对象存储中,putKey操作中的key。也就是说,在一个Container中会被Block所划分,如下图。
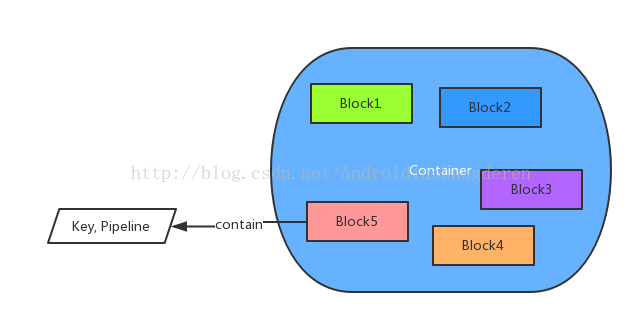
Block也是一个逻辑上的概念,它是反馈给外部的一个对象,使得调用方对于Container是完全透明的。在Block中,包含了2个关键信息,存储的key值与存储此Block的所有Container的位置信息。
其实从这里我们可以看到,这里有一些元信息需要被关联:
1.Key--->Container的信息。通过key找到对应的Container。
2.Container--->Pipeline。通过Container名称找到Pipeline信息,方便后续的数据写入。
2.集群内有效的Container信息。
很显然这些信息是要被SCM所持有和管理的。按照往常的逻辑,可能我们不禁会联想SCM难道也是一次性load到内存?如果分配的Block足够多,这样的信息也会挺大的,这样会重蹈NameNode的覆辙?答案在后面揭晓。
Ozone的元数据信息管理
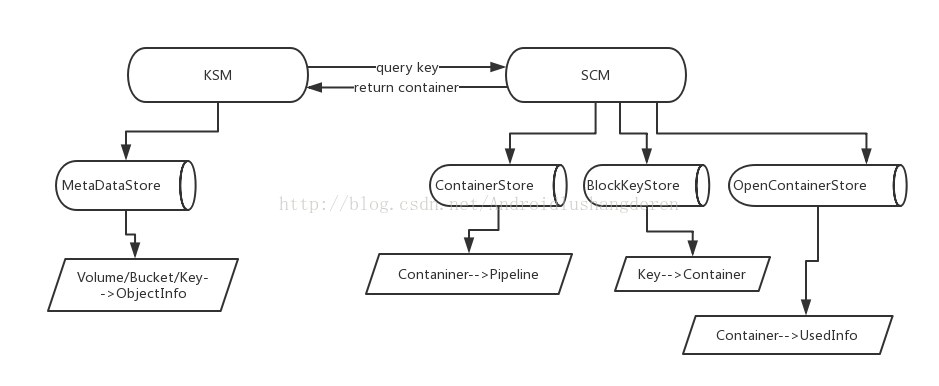
这里终于到了我们非常关心的Ozone元数据信息管理方面的内容了。在Ozone体系内,里面的元信息主要为所有的Volume,Bucket和Key的信息,这些信息被一个叫做KSM(KeySpaceManager,类似于现有HDFS中的NameNode的角色)的服务所管理。这些信息的数量将会是很庞大的,尤其是最下层的key信息,因为一个Key对应的就是一个文件。在Ozone文档设计中,是明确说明能够支持存储10亿数量级别的Key的存储的。我们这么设想,如果10亿个文件存在NameNode里,Block数至少10亿吧,NameNode节点有256G内存估计都不管用。所以在这里,我们可以大胆猜测,Ozone绝对不会一次性将数据全落在内存里,应该采用了外部一些存储DB。笔者要揭晓最终答案了,答案就是LevelDB。我们知道LevelDB是把数据存在文件里的,它很好的一点是会将近期活跃的数据hold在内存里,不活跃的数据就会写出到磁盘上去了。LevelDB的数据存储格式是K-V存储的,所以Ozone存入内容的格式如下:
Volume/Bucket/Key---->PBObjectInfo
也就是说,它存入的对象是键值+PB对象,取出的时候做相应的反解析。所以KSM这里也会有一个LevelDB做存储。
所以总的来看,KSM用到1个LevelDB store,SCM是3个,总共就是4个。层级结构如下图所示。
当然在未来,可能会有比LevelDB性能更好的K-V存储框架,在Ozone中完全也可以进行替换,同时保证元数据的接口层不变即可。从这里我们可以看出,Ozone在设计的时候,考虑了自身系统的特点,很好的借用了外部的存储系统,来辅助系统数据的管理。
Ozone未来的展望
笔者个人觉得Ozone的设计实现是具有重要意义的,它在DataNode内抽象出了Container的概念。而Ozone对象存储,只是其中的一个服务应用,也就是说在未来,我们完全可以基于此提供其它类似服务,比如说目前还有CBlock的服务(这块笔者还没深入看过,也在HDFS-7240内开发)。如下图:
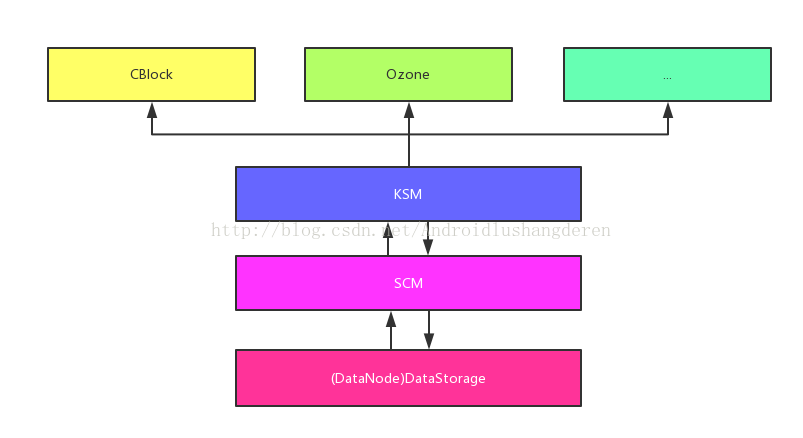
Ozone的设计吸取了HDFS NameNode服务太重的教训,做了很多的拆分剥离,KSM,SCM的出现就是典型的例子。最后希望大家能够多多关注HDFS Ozone,关注HDFS-7240,这个功能在未来几个月内很快就要问世了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号