YARN Container的NUMA感知支持
前言
在现有YARN的Container运行过程中,还没有考虑到计算机内存的访问模式。更进一步地来说,针对CPU处理器对于计算机内存的访问模式,YANR的Container执行在这方面还可以进一步优化。比如在多处理器情况下的计算机内存访问模式NUMA模式下,尽量减少跨内存区域的访问将会加速执行的速度。在早期的实现中,YARN并没有考虑到这些情况的。所以今天笔者带领大家了解一下NUMA架构体系以及YARN Container对于NUMA的感知执行。
NUMA架构体系
在阐述本文正文之前,可能有部分同学不了解什么是NUMA,所以这里做个简单地介绍。
NUMA,全称是Non-uniform memory access,用中文翻译为非一致性内存访问。现在的问题来了,NUMA架构是怎样的一种结构呢?它主要用来解决什么问题的呢?
下面笔者进行简单的解释。
其实在NUMA架构之前,内存是被处理器所共享的,然后通过总线方式进行数据的传输。随着处理器的增多,这里面处理器对于总线的竞争就会加剧。所以NUMA在这方面就做了改进,通过将内存分成多个小内存Node区域,每个小Node区域再被一部分处理器所共享。当然,这些处理器也可以访问别的Node区域的内存,只是说跨区域内存访问会慢于本地内存访问的速度。下面是NUMA架构体系。
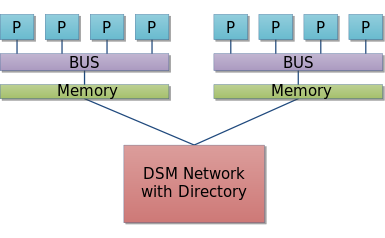
P代表的是处理器。上图显示的左边为一个Node区域,一块内存被5个处理器所共享,右边同理。
通过NUMA的命令行工具,我们能直观地得到这些信息,如下命令:
$ numactl –hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
node 0 size: 65133 MB
node 0 free: 17786 MB
node 1 cpus: 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
node 1 size: 65536 MB
node 1 free: 28880 MB
node distances:
node 0 1
0: 10 21
1: 21 10
上面命令是笔者在真实服务器上执行得到的结果,我们可以得出的信息有,总共2个node区域,每个node 64GB内存,32个核一个node,机器总内存128GB,64核。其中node0剩余内存17GB左右,node1则还有28GB左右内存的剩余空间。
YARN Container的NUMA感知优化
优化核心方向
在NUMA架构下的内存访问模式下,我们的一个核心优化方向其实很简单:
尽可能地让处理器访问本地的内存,减少远程内存的访问。
因为本地内存的访问速度是快于远程的,这个优化在YANR层面的解释就是:
尽可能地分配同个node区域的核和内存给Container执行。
Container NUMA感知执行的实现细节
社区在YARN-5764中对这个功能进行实现了,这里主要概括其实现的要点,具体代码就不展开阐述了。
主要有以下几点实现要点:
- 1.新增配置功能来控制YARN Container NUMA感知的功能。
- 2.系统NUMA信息可以通过获取系统信息或是由用户手动配置传入。
- 3.YARN内对NUMA信息进行解析,并转化为Node资源实例对象保存在内存中。
- 4.针对每个Container分配的时候,从NUMA获取的Node信息里,进行核数,内存资源的,注意,采用轮询的方式从每个Node里进行资源的划分。如果出现单个Node资源不足的情况下,再分配多个Node资源进行Container的分配。
- 5.每个Container在申请自己对应的Node id标号后,在启动的时候带上numa绑定CPU,内存的命令启动即可,绑定命令类似如下,此命令的作用就是让Container执行在指定node区域的内存和处理器上了。
numactl –membind=[node] –cpunodebind=[node]
今天分享的内容就是以上,大家只要理解实现思路以及YARN对于NUMA结合的这一块就可以了,感兴趣的同学可以阅读相关代码进行进一步地学习。
引用
[1].https://en.wikipedia.org/wiki/Non-uniform_memory_access
[2].https://issues.apache.org/jira/browse/YARN-5764. NUMA awareness support for launching containers

 浙公网安备 33010602011771号
浙公网安备 33010602011771号