流计算过程中对于窗口的处理方式
前言
与传统批处理作业方式不同,实时流的计算处理过程是连续的。所以当我们在流式作业中要做传统的阶段统计工作(求和,取均值计算)的时候,需要在逻辑上对这些数据进行分片,然后再处理。本文我们来聊聊流计算过程中按照时间的处理方式。
Window的概念
在传统批处理的作业执行方式里,我们可以一次性读取入所有的输入数据,然后经过计算,再输出结果。对于原始数据,我们可以做任意我们想做的预处理工作,包括数据项的排序等等操作。但是在实时流计算引擎下,很多东西就不会这么直接,简单了。至少,我们需要明白一个点:在连续不断的流数据中,我们如何对其进行逻辑意义上的拆分,这个拆分线我们到底怎么来划分。
按照最最常考虑到的2大维度,大小和时间。这2大维度,按照自由组合,我们可以组合出以下3种窗口类型:
- Fixed-Sized Window,固定长度窗口。
- Time Window,时间窗口。
- Fixed-Sized and Time Window,滑动窗口。
固定大小窗口和滑动窗口的效果图如下图所示。
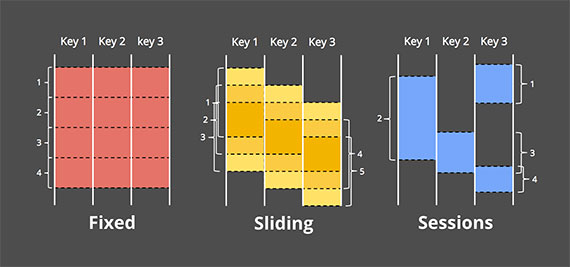
在现实的场景中,我们用时间窗口会比较多一些,比如分时段内的数理统计需求等等。于是这里会衍生出另一个话题:按照窗口的时间计算,这个“时间”要依据的是哪个呢?
窗口时间计算类型
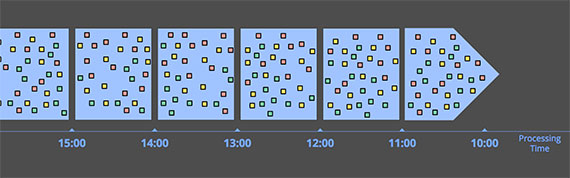
假设是完全理想的情况,我们默认的时间当然指的是任务当前的处理时间为窗口目前依据的时间。如下图所示。
但是在现实的环境中,有很多影响会导致数据的真正时间不完全等于其处理时间,直接地来说,就是数据被处理的时间距离它的原始生成是有延时的。这里的延时原因至少包括以下2点:
- 数据网络传输延时。
- 任务计算处理耗时。
而且以上延时会导致数据出现乱序的问题,比如后一个时间点的窗口内突然到来了一个“迟到”的数据点。那么这个时候这个迟到的数据要怎么被处理呢?总不能算到当前的窗口周期内吧。
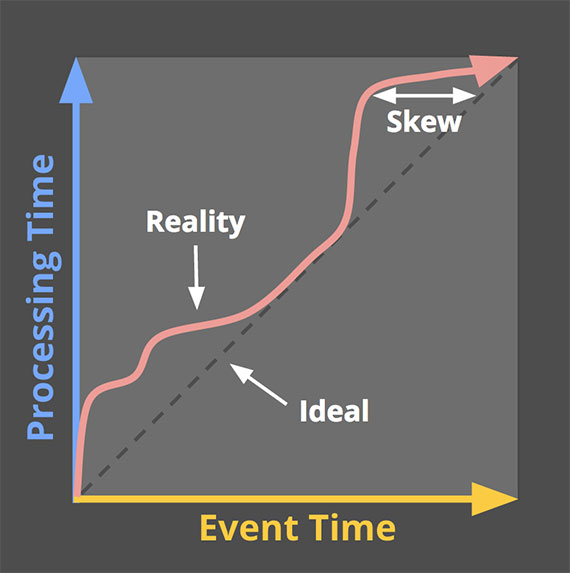
这里我们用event time来表示数据的本身时间,用process time来代表其被处理的时间。绝对理想状况下,二者是完全想到的,但是实际场景中,event time和process time总是会存在略微偏差,如下图。
基于Watermark的Event Time Window计算
鉴于真实场景中,数据的当前处理并不等于其产生时间,所以更多的时候我们会选用数据的时间,也就是Event Time来做窗口计算。
网络数据在传输过程中,有很多不稳定的因素,导致存在乱序的情况,比如这个时刻点接收到了上上个时刻点的数据。那么这个时候,我们怎么处理呢?
这里有以下几种办法。
第一种,完全丢弃这样的数据。这里我们基于的一个假设是,这样的异常延时的数据不会太多,将不会影响到整体的数据。更简单地来说,这是一种不增加系统处理复杂性的前提下,保证整体准确性的做法,是一种近似准确性的方法。
第二种,允许一定容忍度内的“乱序”数据。当一个窗口时间过去之后,下一个新的窗口开始计算的时候,此时我们不会立即关闭上一个窗口,等上一段时间,来确保晚到的本属于上个窗口的“最晚”时刻的数据被处理掉。然后再关闭上个窗口。所以这里要引入一个能够表示event time进度的概念,我们这里叫watermark。一个数据的watermark可以由其event time时间转化计算得来,一种常用的转化公式如下:
watermark=event time - allowMaxLatency
上述公式的意思是:如果我们处理到当前数据的watermark时间(其event time减去最大允许延时时间)已经超过窗口区间的闭区间时间,则表明此窗口的数据都已完全到达。
其实从这里我们可以看出,窗口数据的真实生命周期是被拉长了一部分,会同时存在前后多个窗口存在的情况,因为数据是允许一定latency到达的。当然,我们也不会一直死等那个“落单”的数据。在watermark的运用下,窗口数据的准确性能得到保证。
引用
[1].https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101

 浙公网安备 33010602011771号
浙公网安备 33010602011771号