聊聊HDFS的权限访问控制
前言
我们都知道HDFS文件系统的访问控制由其内部目录,文件的权限所控制,和Linux文件系统一致。但是当出现HDFS和别的组件进行关联使用时,我们是否还能做到预期的控制效果呢?比如Hive和HDFS的使用,Hive也有它自己独立一套的用户权限体系。本文笔者来简单聊聊HDFS的权限访问控制,我们不聊最简单的情况,只聊那些在生产中实际可能会遇到的场景。
典型场景:权限信息不一致情况
文件系统信息在使用过程中是有可能出现新老数据文件的权限不一致问题,而此时访问的用户也可能是老用户或者是全新的一个用户。那么这里就有可能会出现权限访问的问题。举个笔者在实际工作中遇到的一个问题:
在早期阶段,涉及到数据开发的应用都用账号data来跑,自然的,此账号所建的文件及目录的owner都是data。但实际上它的真实用户就是一个应用层面的项目账号。用公共账号看似方便了数据读写流程控制,但是它有权限过大的风险,而且很容易发生越权操作行为。A用户以data账号身份操作执行了B用户以data账号写出的数据文件。因为都是data账户执行,操作不会被拒绝。
所以后续地,我们就会想到账户拆分,然实际用户传进来,然后创建其owner属于自身的数据文件目录。那么这个时候,就会出现,新老数据以及新老用户共存的情况,如下所示:
old files: /user/data/A_files owner:data
new files: /user/A/A_files owner:A
当然我们说,拆分出来的用户A访问它自身新产生的数据是完全没有问题。但是如果它想对历史数据做写动作时就会出现问题。
人工介入修改方案
这里介绍一种不介入外部系统的方法来做权限的兼容性修正。大致思路如下:
获取所有项目账号和目录的映射关系,然后对相应目录更改owner属性。而获取项目账号和目录的关系可能就涉及到其它外部系统的元数据查询动作了,比如Hive 的metastore。
外部权限管理框架:Sentry和Ranger
对于上面提到的权限信息的不一致问题,有没有更加系统的,完整的解决办法呢?这里笔者介绍2个业界流行的解决方案:Sentry和Ranger。
Sentry的插件式权限同步控制
这里以HDFS和Hive的元数据权限信息同步统一为例。它的一个核心操作是在数据系统程序中加载入对应的plugin插件程序,然后plugin程序来和Sentry Sever主程序做信息交互。这个权限信息的同步过程,对于用户来讲是完全透明的。Sentry的架构如下,
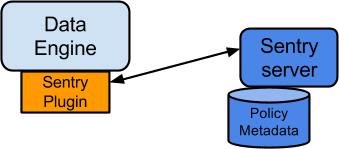
上面的DataEngine指的是具体的应用进程服务,如HDFS,Hive等等。
以HDFS和Hive之间的权限同步为例,其过程如下图所示:
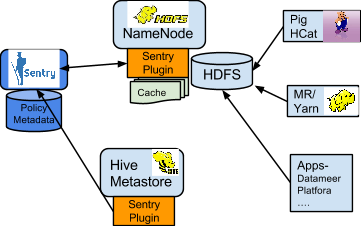
Ranger的覆盖式权限访问控制
相比于Sentry的权限控制方式,另外一套体系Ranger采用的是一种优先覆盖式的权限访问控制。还是以HDFS为例,首先一步,用户需要完全覆盖HDFS默认的那套ACL控制方法,然后加载入Ranger的相应类方法,也就是说更新下面类的值:
<property>
<name>dfs.namenode.inode.attributes.provider.class</name>
<value></value>
<description>
Name of class to use for delegating HDFS authorization.
</description>
</property>
然后后面所有的用户对HDFS文件的权限检测都会由对应的Ranger提供类内部来做,也就是我们提供的Ranger内部实现的提供类。而在这个加载类里,Ranger为我们提供了灵活的策略控制,用户可以自由配置访问控制策略,然后插件类会从持久化信息中来拉取策略类。过程如下图所示:
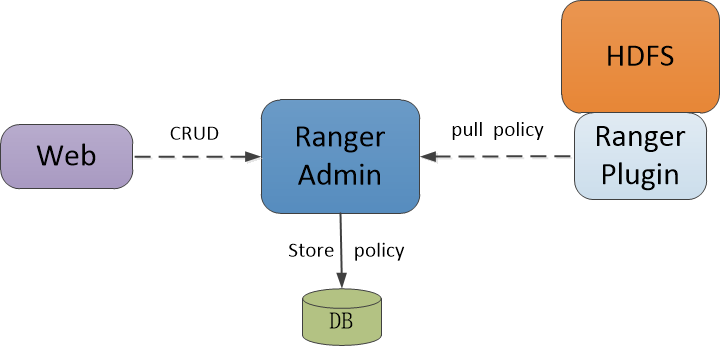
从这里我们可以看出,2个框架的思路基本一致:通过载入额外定义的插件程序来将系统默认的权限访问控制过程更新为自身系统定义的权限访问控制策略。
引用
[1].https://cwiki.apache.org/confluence/display/SENTRY/Sentry+Tutorial
[2].https://www.cnblogs.com/qiuyuesu/p/6774520.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号