
Flink FileSystem的connector分析
文章目录
前言
从目前最新的Flink代码来看,现在它能够支持越来越多的connector类型了,不仅仅说包括于前面的Source的连接,还有后面Sink的选择。但是Flink的连接器不是简简单单的说做一个外部数据源系统的连接就OK的,而是要有一定的Exactly Once的恢复能力。因为Flink应用在做checkpoint的时候,要从前面的源到后续的Sink都得到完整的恢复。今天本文来讲述其中的基于文件系统的连接器实现,笔者主要阐述它在checkpoint模式下,如何做Exactly Once的恢复的。
FileSystem的RollingSink
在Flink的FileSystem连接器实现中,实现的一个很重要的特点是RollingSink。因为对于上游连续不断的数据传来,我们肯定不能永远让它写到一个恒定的文件或目录当中。所以这里会有一个rolling滚动的概念。那这个滚动规则如何呢?
一种简单的做法,按照小时时间级别的滚动,相当于我们人为地将1天分为了24个Bucket的概念。然后在这个目录下,我们再来按照文件大小阈值做文件的rolling。每个文件数据都是这个Bucket下内容的一部分。
当然啦,Flink也支持外部自定义Bucket的实现。
FileSystem连接器的Exactly Once恢复语义
因为Flink应用任务存在checkpoint语义恢复的情况,所以这里的文件系统连接器的文件状态在设计上不会只有一种情况了。下面我们从FileSystem Sink的文件状态讲起。
FileSystem Sink的文件状态转换
Flink社区在实现这个逻辑时,以checkpoint为关键时间点,将文件状态划分为了以下3种状态:
- In-progress,正在写的文件,写好后,将被移动到Pending状态文件中。
- Pending,已写好,等待移动到finalized状态,由新的checkpoint完成所触发。
- Finalized,最终确认状态文件。
Flink引入了Pending中间态,使得系统对于文件的控制不会直接依赖于从正在写直接到最终状态文件中。这种引入中间过渡文件状态的处理方式也是比较常见的,比如MR JobHistory的job文件的处理方式,它的内部也有一个immediately目录,专门存放临时目录,然后被额外线程move到最终确定目录下。当有大批数量的结果文件产生时,引入中间状态文件能够很好的解决它到最终态文件的转化问题。而且如果由系统导致的文件数据异常问题,也可以在中间态阶段进行解决。
FileSystem Sink的状态文件转化关系如下图:

下面我们结合上面提到的按照时间的Rolling Sink属性,基于FileSystem的Sink过程如下图所示(ck是checkpoint的缩写):
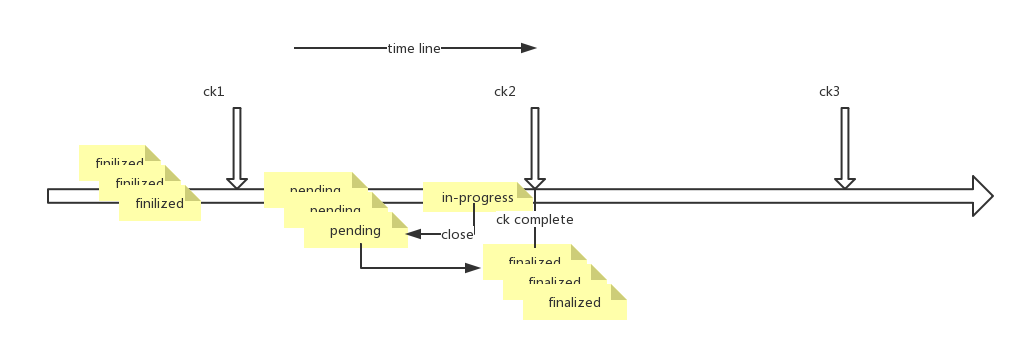
Checkpoint下的Exactly Once恢复
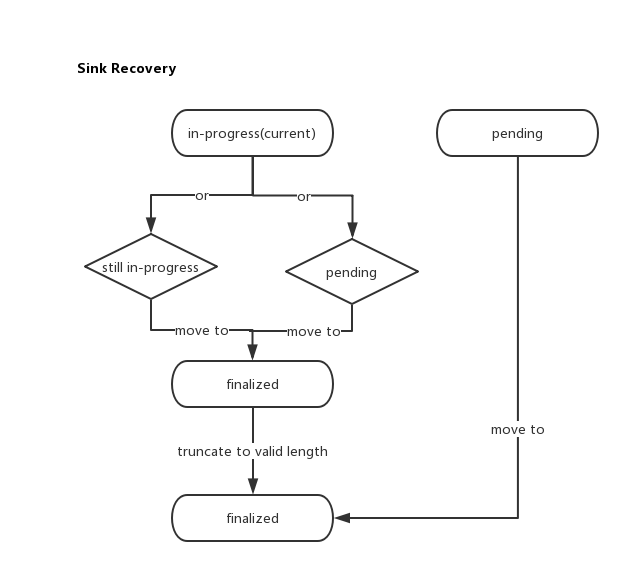
下面我们来看FileSystem Sink的Exactly Once恢复。这里的恢复主要为以下两类文件的恢复
- 第一,in-progress的文件恢复,要必须保证的一点是,它不能有脏数据的写入。
- 第二,pending文件状态的处理。
对于第一类文件,它在系统恢复时,会存在2种情况,一种还是In-progress状态,一种是已经被move到pending状态了,我们无从知晓了。如果是第二种情况,很简单归入第二类的处理方式即可。对于第一种情况,我们直接将其从in-progress移到到finalized确认态。但是在完成后,要做一次truncate操作,防止多于数据的写入,这个truncate的截断长度由Sink Snapshot时保存到State状态信息里面的值所决定。
而对于pending状态文件来说,因为checkpoint失败,使得系统得不到checkpoint complete事件通知,但是数据还是正常的,这里的处理方式是直接move到finalized态就OK啦。
恢复过程如下图所示:
本文介绍的原理内容来自于flink-connector-filesystem模块的源码实现,详细过程有兴趣的同学可阅读具体源码实现过程。

