
YARN的Log Aggregation原理
前言
在大数据的时代,我们想从数据中去分析提炼出有价值的东西,背后有时是成百上千个任务的运算结果。在一些比较大的数据平台的规模下,出一份第二天的详尽的数据报表信息,需要前一天跑上数十万级别的任务数。更直接地来说,我们的计算平台单日内需要调度并执行完这几十万个任务。这么多任务需要跑完,难免中间会有一些任务有失败的情况,那么这个时候我们一般会怎么做呢?为了保证这些任务的顺利执行,用户一般会添加自己的日志来帮助做潜在问题的trouble shooting。但是问题来了,如此海量的任务下必然也会产生大量的日志数据,还得附带上系统里打出的记录,那简直就更多了。这个时候从一个成熟分布式计算平台的角度来解决这个问题,有什么好的处理办法呢,去尽可能存我们希望的“足够多”的日志数据。本文,笔者结合YARN的log aggregation来聊聊这个话题。
Log Aggregation
在分布式计算平台内,每个独立的应用都有其自己的执行日志。这些日志之间是完全独立的。为了保持日志写出的快速性,这些日志一般会直接写出到当时所在节点的本地磁盘上,也就是我们所说的local log。如果我们的任务出现问题了,就跑到那个应用当时所跑的节点下,去看日志。这种root cause的方式想必大家都不会陌生。但是这种日志完全独立分散的存储是很难做到集中管理的。随着时间的推移,日志只会越来越多,那么这个时候必须要清理一些日志出去了。为了能够更好的管理这些日志,我们需要有一个Log Aggreation的操作。Log Aggregation操作语义不仅仅只是将日志汇聚到一个地方。确切地来说,汇聚到一起只是这个大步骤里的一部分。
下面,我们一一来看Log Aggregation里的细节过程。
日志的汇聚
上小节已经提到过,分布式应用的日志在落到本地情况下是极不好管理的,这个时候我们需要有aggregation的动作。Aggregation的目标位置可以是一个remote store,这个remote store我们当然希望它是高可靠的,足够稳定的存储系统。于是在YARN里,这个aggregation地址就是HDFS了。
于是在Log Aggregation的第一步,将会是如下过程:
- 分布式应用任务写log到本地
- 任务运行结束,系统读取本地日志文件,将其写到远程存储中。此过程即为日志上传过程,上传日志到远程存储过程可以进一步对原始数据做包装处理,比如压缩,归并日志等操作来减少存储空间。
- 系统上传完毕,删除任务本地日志数据
上述步骤2中所说的归并,指的是日志文件级别的归并,比如某应用按照日志类型写了3类日志,error,info,out。但是在写出到远程存储后,可以将3个文件写到一个文件里,并通过日志类型标记位进行区分。这样可以减少日志的存储数量,做到1个应用只存储1个文件。
日志的retain策略
日志是汇聚到了更加稳定的远程存储中了,但我们还是需要有一个retain策略来限制一定量的日志数据。一个简单的方案是按照时间expiration的条件来,比如1周为一个期限,然后我们需要有一个log deletion service的来定期做这个事情。
Log Aggregation的查询
日志被aggregation之后,对于用户的日志查阅来说,其实就转变为了远程存储系统的数据读取操作了,也就不用再登录到机器上去看日志这种比较麻烦的方式了。
Log Aggregation流程图
针对以上过程,Log Aggregation的流程图如下所(数字编号即步骤先后顺序):
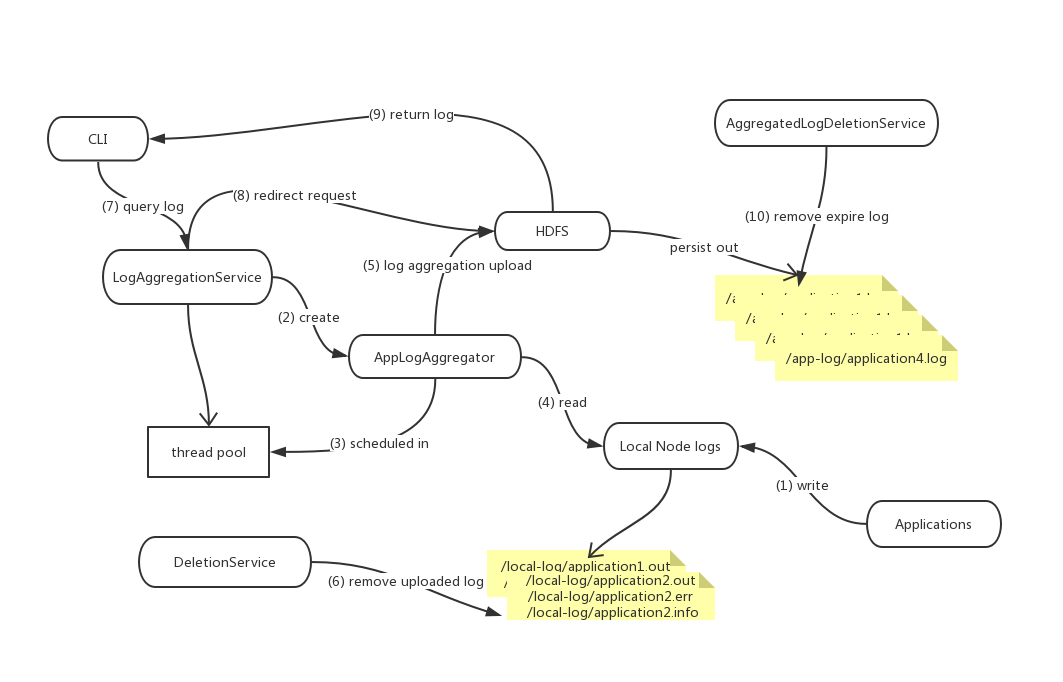
相信YARN的这套应用Log Aggregation处理方式在分布式计算平台内都或多或少有许多借鉴之处。

