HDFS Segment Block Report方案设计
前言
在上文HDFS全量块汇报(FBR)的限流机制中,笔者提到了对于目前HDFS FBR处理新的一个思路方向。大意是指将DataNode的块汇报粒度控制在NameNode这边来决定,而不是在DataNode这边。毕竟block report才是真正负责处理的角色。另一方面,单纯在DataNode端以per storage的方式进行block report拆分还不够灵活,随着实际存储密度性能的不断提升,每个storage所包含的block也将会不断的提升。基于这几点,社区曾经提出过讲block进一步进行逻辑上的拆分,拆成一个个小的segment段,然后在segment级别进行块的汇报。本文笔者来阐述的主题就是HDFS的基于Segment的Block Report设计。
Block的Segment划分
在这里Segment的意思是“片段”的意思,而对于FBR(Full Block Report)来说,我们的目标就是将一整块FBR拆成若干个小的Segment Block Report。因此这里需要做的一个事情是
将现有Block进行Segment划分。一种比较自然联想到的做法是根据Block Id进行区间划分,而社区的方案正是采用了这种方法的。
在每个Segment段内,代表的其实是一个range范围,从SegmentStart到SegmentEnd。 SegmentEnd-SegmentStart的值代表的是每个Segment所能包含的Block数。然后划分根据每个Block的Block Id进行Segment计算,然后进行划分,划分算法为block id减去最小id值然后除以每个Segment的最大允许存储块数n,公式如下:
2^30 + floor((b- 2^30) / n) * n)
segmentEnd = segmentStart + n - 1
划分后的结果如下图所示:
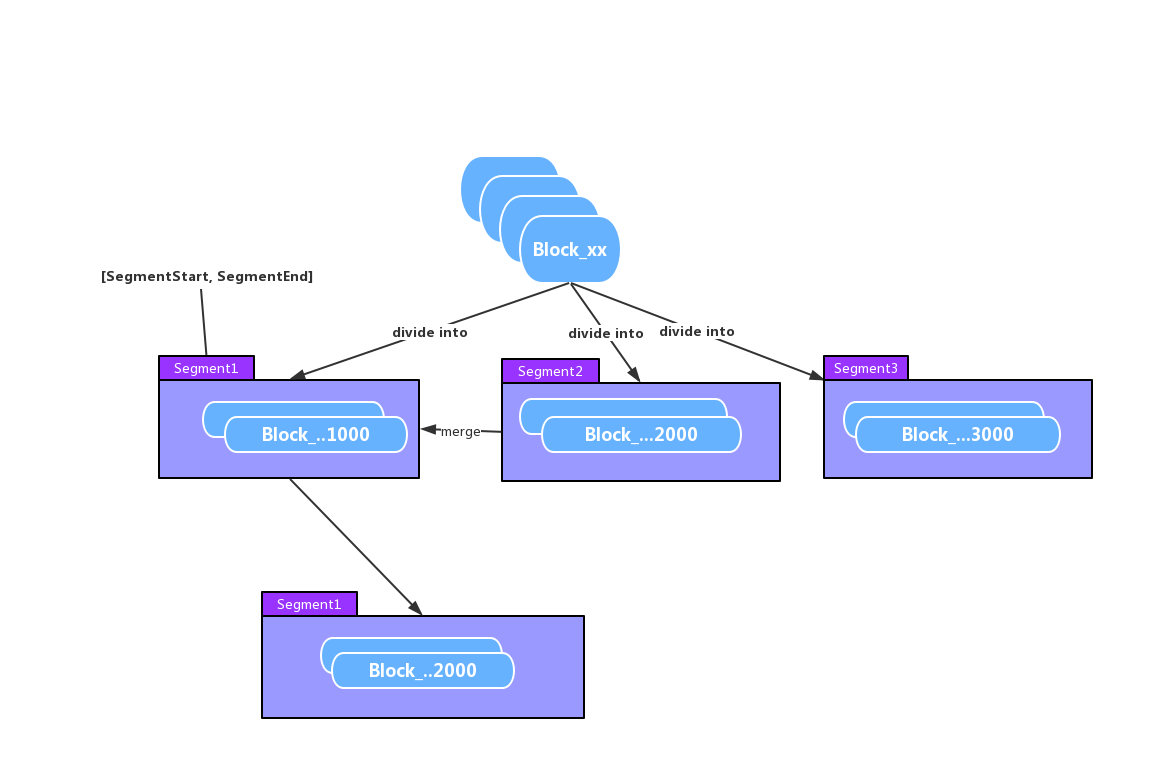
上图显示的Segment的Block块的最大允许值为1000。当我们在为现有Block进行Segment划分好后,发现部分相邻的Segment实际划分Block块数比较稀少的时候,会进行一次merge操作。上图中为Segment2合入Segment1内。
Block的Segment划分只是逻辑层面的划分,它并需要被持久化出去,在每次NameNode重启时进行一次计算划分即可。当Segment划分好了,NameNode将会在内存中多维护一层[Segment, List<Block>]的映射信息了。这个映射信息将会在后面DataNode的Block Report中发挥作用。
DataNode的Segment块上报
相比较于原先的FBR,此时DataNode需要根据的是Segment进行块的汇报。这里的Segment指的是此DataNode上的块按照Segment划分进行上报。而具体汇报Segment的先后顺序由于NN决定,并通过heartbeat进行通信。这块逻辑是可以完全复用上文提到的Blokc Report Lease机制。
DataNode Segment Block Report上报流程图如下:

上面意思为NN要求DN1汇报Segment1的BR,DN2汇报Segment3的BR以及DN3汇报Segment2的BR。
引用
[1].https://issues.apache.org/jira/browse/HDFS-11313 . Segmented Block Reports

 浙公网安备 33010602011771号
浙公网安备 33010602011771号