

HDFS RPC处理性能提升之IBR(增量块汇报)的延时批处理
文章目录
前言
众所周知,HDFS NameNode内部的单一锁设计,使得这个锁显得极为的“重“。这里的重不仅仅说它很重要,而是说持有这个锁需要付出的代价很高。每个请求需要拿到这个锁,然后让NN 去处理这个请求,这里面就包含了很激烈的锁竞争。因此一旦说NN的这个锁被一个大的写操作(比如大目录的删除)持有很长时间的话,其它用户的任务将会马上收到影响。当然删大目录这样的行为并不是经常会发生的,这里笔者想表达的意思是我们应该尽量减少不必要的高密集的写锁持有操作,来减轻其对用户请求正常处理的影响。本文笔者将要阐述的这样的操作是HDFS内部增量块(IBR)的处理操作,现有IBR行为到底会对系统产生多大的影响呢?我们有什么办法可以优化其行为方式呢?
HDFS DataNode高频度增量块汇报行为
HDFS增量块汇报行为实质等同于我们平时所说的HDFS的块汇报行为,那这里我们为什么多加增量两个字呢?那是因为在HDFS内部,还有另外一种块汇报行为叫做全量块汇报,Full Block Report,简称FBR。FBR行为由于要汇报所有的块,代价太高,一般间隔时间比较久才汇报一次。因此为了让NN能够第一时间知道DN上写的块的情况,DN就有了增量块汇报(Incremental Block Report)的方式。
增量块汇报主要汇报以下3类在正在DN节点发生的块情况:
- 刚刚被删除的块
- 正在被接收(写)的块
- 接收完毕(已被写完)的块
目前现有DN的IBR行为如下:
当DN上出现以上3类块情况发生时,之后DN的BP Thread将会在内部循环中立即将这些块进行上报。
以上处理方式的本意还比较好理解,为了让NN知道块的完成情况,然后结束文件的写操作行为。但是以上DN看似高效的行为,实际上却埋下了一个隐患。当DN不断的有块在被删除,块被添加读写时,这意味着DN会有源源不断的IBR行为。并不是说IBR行为变多会给DN带来多大的压力,这里的压力其实是在接收端NN这里,毕竟它要处理下面上百成千DN节点的增量块汇报。
NN每处理一次IBR是要获取写锁来更新其内部元数据的,因此DN高频IBR汇报势必会导致高频率的处理IBR操作,也就意味加剧了内部锁的竞争,间接影响到其它正常任务发来的RPC请求。当这些正常请求被block住的时候,从现象上来看则是call queue length的堆积。
DN的IBR汇报块行为如下图所示:
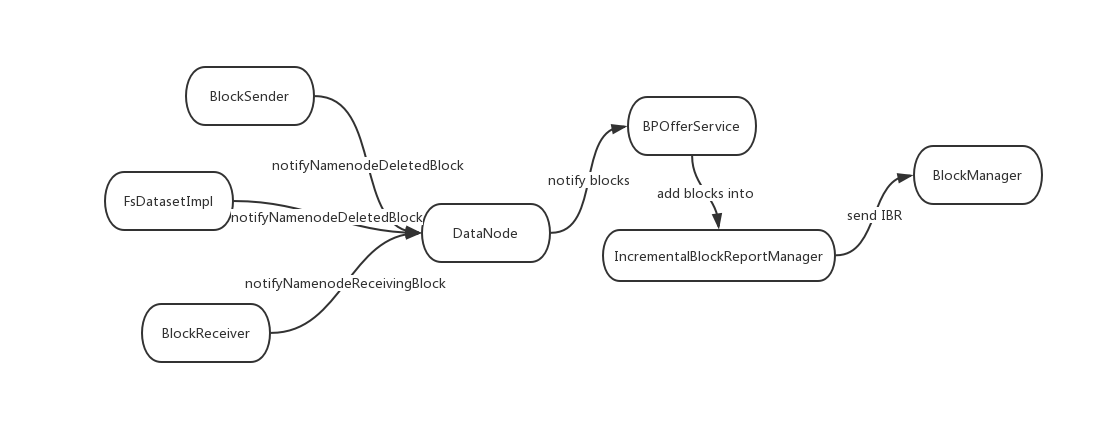
上图中BlockSender, BlcokReceiver和FSDatasetImpl为DN内部负责块读写的相关角色。
截止目前为止,HDFS DN节点高频度增量块汇报行为是一个影响HDFS RPC处理性能的一个因素。但其实这里还有另外一个因素。
HDFS NameNode同步IBR处理行为
另外一个影响HDFS RPC处理性能的一个因素在处理端,也就是NN这边。目前NN每收到一次IBR请求调用时,使用的都是同步处理的方式?同步的方式意味着我们必须要拿到锁,才能进行IBR的处理。那么问题来了,这里我们需要一定是强同步处理的模式吗?适当延时的集中处理是否可行?如果我们将IBR的高频请求调用进行汇总按批处理,毫无疑问,会大大减少写锁的竞争度。至于这里如何做到批处理的优化,在下文中我们再来细谈这方面的内容。
IBR处理行为优化:DN的IBR延时汇报和NN的IBR异步处理
针对上述分别在DN和NN节点中IBR的处理行为,在现有HDFS代码中都已对其进行了优化改进,而且最终效果显示确实能够提升HDFS RPC的处理性能。
DN的IBR延时汇报
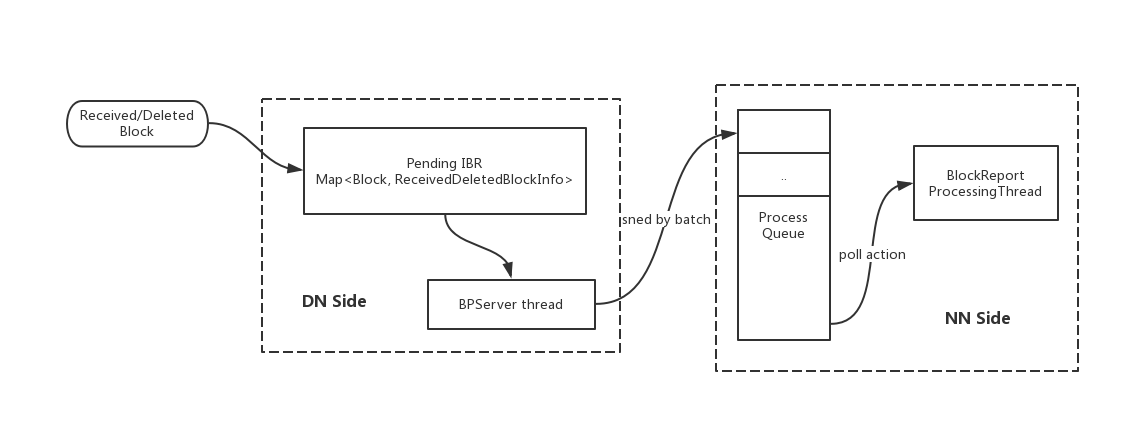
在上小节里,我们提到过DN现有的即使汇报IBR行为会导致潜在大量的RPC处理,因此我们自然可以联系到一种优化的手段:将准实时的IBR汇报行为进行一定时间的delay汇报,变成指定间隔时间内的汇报。
简单地来说,就是我们让DN将IBR间隔时间内的增量块数据信息进行积攒,然后到间隔时间点了,再一次性汇报给NN。这种方案有个不足之处在于,客户端在写完它们的数据文件后,会有稍延迟的时间等待。当时相对于大量IBR造成NN处理缓慢影响到用户行为操作,这样的客户端短暂延时其实是可接受的。
NN的IBR异步处理
NameNode端的IBR异步处理的关键点在于异步两字,说到异步,它首先会有个专门处理IBR的线程。这里我们将这个线程称为BlockReport Process Thread。上文也提到过,因为IBR在实际场景中可能会很多,我们的一个优化点是将其进行批处理化。因此在BP Process Thread内部,我们会维护一个暂存队列。这个队列一边在接收来自DN的IBR信息,另一边被BP Thread取出一批IBR的信息进行处理。
以上两点优化的处理模型图如下所示:
IBR优化处理代码相关实现
下面简单阐述上面优化方案的代码实现,帮助大家更加了解上面的优化改造设计。
DN端的IBR延时处理
首先是增量块的发现过程,这里以删除块为例,FSDatasetIml通知DN删除块信息,
public void invalidate(String bpid, ReplicaInfo block) {
// If a DFSClient has the replica in its cache of short-circuit file
// descriptors (and the client is using ShortCircuitShm), invalidate it.
datanode.getShortCircuitRegistry().processBlockInvalidation(
new ExtendedBlockId(block.getBlockId(), bpid));
// If the block is cached, start uncaching it.
cacheManager.uncacheBlock(bpid, block.getBlockId());
// FSdataset无效一个块时,告知DN准备通知此块到NN
datanode.notifyNamenodeDeletedBlock(new ExtendedBlock(bpid, block),
block.getStorageUuid());
}
···
···
private void notifyNamenodeBlock(ExtendedBlock block, BlockStatus status,
String delHint, String storageUuid, boolean isOnTransientStorage) {
checkBlock(block);
final ReceivedDeletedBlockInfo info = new ReceivedDeletedBlockInfo(
block.getLocalBlock(), status, delHint);
final DatanodeStorage storage = dn.getFSDataset().getStorage(storageUuid);
// 将IBR块信息加入到IBR manager中
for (BPServiceActor actor : bpServices) {
actor.getIbrManager().notifyNamenodeBlock(info, storage,
isOnTransientStorage);
}
}
进而这个增量块信息被加入到IBR Manager的pending IBR集合内,
synchronized void notifyNamenodeBlock(ReceivedDeletedBlockInfo rdbi,
DatanodeStorage storage, boolean isOnTransientStorage) {
// 1)将block信息加入到pending IBR map内
addRDBI(rdbi, storage);
final BlockStatus status = rdbi.getStatus();
// 设置readyToSend为true,意为DN可以进行下一次IBR的立即汇报了
if (status == BlockStatus.RECEIVING_BLOCK) {
// the report will be sent out in the next heartbeat.
readyToSend = true;
} else if (status == BlockStatus.RECEIVED_BLOCK) {
// the report is sent right away.
triggerIBR(isOnTransientStorage);
}
}
synchronized void addRDBI(ReceivedDeletedBlockInfo rdbi,
DatanodeStorage storage) {
// 2)如果已经有相同的块,则先进行移除
for (PerStorageIBR perStorage : pendingIBRs.values()) {
if (perStorage.remove(rdbi.getBlock()) != null) {
break;
}
}
// 3)添加IBR块信息到pendingIBRs集合内
getPerStorageIBR(storage).put(rdbi);
}
最后是IBR的发送行为逻辑,
while (shouldRun()) {
try {
DataNodeFaultInjector.get().startOfferService();
final long startTime = scheduler.monotonicNow();
//
// Every so often, send heartbeat or block-report
//
final boolean sendHeartbeat = scheduler.isHeartbeatDue(startTime);
HeartbeatResponse resp = null;
...
// 默认情况下,IBR 会被立即发送给NN
if (!dn.areIBRDisabledForTests() &&
(ibrManager.sendImmediately()|| sendHeartbeat)) {
ibrManager.sendIBRs(bpNamenode, bpRegistration,
bpos.getBlockPoolId(), getRpcMetricSuffix());
}
//...
// 等待下次IBR发送的时间间隔,如果我们制定了IBR interval时间的话
ibrManager.waitTillNextIBR(scheduler.getHeartbeatWaitTime());
} catch(RemoteException re) {
String reClass = re.getClassName();
if (UnregisteredNodeException.class.getName().equals(reClass) ||
DisallowedDatanodeException.class.getName().equals(reClass) ||
IncorrectVersionException.class.getName().equals(reClass)) {
LOG.warn(this + " is shutting down", re);
shouldServiceRun = false;
return;
}
LOG.warn("RemoteException in offerService", re);
sleepAfterException();
} catch (IOException e) {
LOG.warn("IOException in offerService", e);
sleepAfterException();
} finally {
DataNodeFaultInjector.get().endOfferService();
}
processQueueMessages();
}
其中关键sendImmediately方法如下:
/**
* 判断是否应该立即发送IBR:
* 1)默认interval time为0,一有增量块,则立即进行块的汇报
* 2)否则,等待IBR interval时间后再,再进行IBR的汇报
*/
boolean sendImmediately() {
return readyToSend && monotonicNow() - ibrInterval >= lastIBR;
}
NN端的IBR异步处理
下面我们来关注NN端的IBR异步处理部分。
首先是IBR请求的接收响应方法,
public void blockReceivedAndDeleted(final DatanodeRegistration nodeReg,
String poolId, StorageReceivedDeletedBlocks[] receivedAndDeletedBlocks)
throws IOException {
...
final BlockManager bm = namesystem.getBlockManager();
// 将IBR处理包装为一个runnable action,加入到BlockManager内部的process queue中
// 等待被处理,此queue存在同时添加,取出action的操作
for (final StorageReceivedDeletedBlocks r : receivedAndDeletedBlocks) {
bm.enqueueBlockOp(new Runnable() {
@Override
public void run() {
try {
namesystem.processIncrementalBlockReport(nodeReg, r);
} catch (Exception ex) {
// usually because the node is unregistered/dead. next heartbeat
// will correct the problem
blockStateChangeLog.error(
"*BLOCK* NameNode.blockReceivedAndDeleted: "
+ "failed from " + nodeReg + ": " + ex.getMessage());
}
}
});
}
}
然后进入上面的enqueueBlockOp操作方法,
// IBR处理action加入到BM内部的BP处理线程
public void enqueueBlockOp(final Runnable action) throws IOException {
try {
blockReportThread.enqueue(action);
} catch (InterruptedException ie) {
throw new IOException(ie);
}
}
我们提到的关键block report thread对象出现了,在block report thread内部,实现了基于队列的IBR分批处理,具体代码逻辑如下:
private class BlockReportProcessingThread extends Thread {
private static final long MAX_LOCK_HOLD_MS = 4;
private long lastFull = 0;
// action处理队列
private final BlockingQueue<Runnable> queue;
BlockReportProcessingThread(int size) {
super("Block report processor");
// 初始化指定capacity长度,有界队列,默认值1024
queue = new ArrayBlockingQueue<>(size);
setDaemon(true);
}
@Override
public void run() {
try {
// run方法执行处理队列操作
processQueue();
} catch (Throwable t) {
ExitUtil.terminate(1,
getName() + " encountered fatal exception: " + t);
}
}
private void processQueue() {
while (namesystem.isRunning()) {
NameNodeMetrics metrics = NameNode.getNameNodeMetrics();
try {
// 1)阻塞等待queue中有action加入
Runnable action = queue.take();
int processed = 0;
// 2)获取写锁,准备从queue中逐一取出action进行执行
namesystem.writeLock();
// 3)metric计数更新,预计此批处理queue.size()+1次IBR
metrics.setBlockOpsQueued(queue.size() + 1);
try {
long start = Time.monotonicNow();
do {
processed++;
// 4)IBR实际执行操作
action.run();
// 5)如果此批处理的IBR总耗时已经超过最大时长时间(目前4ms),则中断此批处理,
// 避免此批处理占用锁时间过长
if (Time.monotonicNow() - start > MAX_LOCK_HOLD_MS) {
break;
}
// 6)从queue中继续获取下一个执行IBR action,直到全部取完
action = queue.poll();
} while (action != null);
} finally {
// 7)当前队列执行完毕,释放写锁,允许其它RPC操作继续执行
namesystem.writeUnlock();
metrics.addBlockOpsBatched(processed - 1);
}
} catch (InterruptedException e) {
// ignore unless thread was specifically interrupted.
if (Thread.interrupted()) {
break;
}
}
}
queue.clear();
}
...
}
上述2种方法在原理本质上有共同之处,优化思路都为将同步即时处理方转变为了延时批处理的方式,以此带来系统性能上的提升。笔者在实际工作中对此2种方法进行了应用,效果提升显著,尤其在集群workload比较高的情况下,大家可以多多利用好这两个功能改进。
引用
[1].https://issues.apache.org/jira/browse/HDFS-9197 . Coalesce IBR processing in the NN
[2].https://issues.apache.org/jira/browse/HDFS-9710 . Change DN to send block receipt IBRs in batches

【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步