Ozone集群搭建以及基本使用
前言
笔者在近两年时间里一直在写Hadoop生态圈内的下一代对象存储系统Ozone的文章,不过都没有找到机会在实际的环境中跑一把。最近花了点时间,在一个测试环境中搭建了一个real cluster,通过这个real cluster,至少笔者了解它run起来到底是长什么样的。同时分享下搭建Ozone集群的操作步骤,毕竟目前与此相关的介绍文章不是很多。
Ozone的背景介绍
Ozone最早被提出是在HDFS-7240: Scaling HDFS这个JIRA里,当时的定义是在HDFS之上做Object Store,就是对象存储,以此解决HDFS的扩展性问题。后来这个功能越做越大,最后被分离出来作为独立项目发展了,就是今天我们看到的模式Ozone/HDDS。相比较于HDFS,Ozone能够支持更高规模级别的元数据,首先它的元数据不是基于完全内存式的存储,而是第三方KV高效存储db,比如RocksDb, LevelDb等等。另外Ozone的对象存储方式对于使用者来说比较友好,使用起来十分的简单。
Ozone集群环境搭建
在这里简单介绍下真实的Ozone集群的搭建过程,在不考虑HA搭建的模式下,整体过程并不麻烦。
笔者的测试环境搭建的节点情况如下:
- Master1节点(1个):SCM服务
- lyq-m1
- Master2节点(1个):OM服务
- lyq-m2
- Slave节点(4个):Datanode节点
- lyq-s1
- lyq-s2
- lyq-s3
- lyq-s4
前期执行步骤
在搭建环境之前,需要完成以下一些前期依赖工作:
1)安装JDK
2)从Ozone官网(https://hadoop.apache.org/ozone/downloads/)下载最新的ozone版本(目前都是alpha版本,不建议用生产),分发到待部署的所有节点中
3)把Ozone的Home地址配到环境变量里,方便我们执行ozone命令
4)将JAVA_HOME地址配到ozone安装包里的hadoop-env.sh文件
export JAVA_HOME={Path to JDK}
以上3步骤执行完毕后,我们可以执行第一个ozone命令,ozone version命令,打印当前使用的Ozone版本,命令执行如下:
[hdfs@lyq-m1 ~]$ ozone version
//////////////
////////////////////
//////// ////////////////
////// ////////////////
///// //////////////// /
///// //////// ///
//// //////// /////
///// ////////////////
///// //////////////// //
//// /////////////// /////
///// /////////////// ////
///// ////// /////
////// ////// /////
/////////// ////////
////// ////////////
/// //////////
/ 0.4.0-alpha(Badlands)
Source code repository https://github.com/apache/hadoop.git -r 4ea602c1ee7b5e1a5560c6cbd096de4b140f776b
Compiled by ajay.kumar on 2019-04-30T03:25Z
Compiled with protoc 2.5.0
From source with checksum 45e58ba9203a1b4470e183bf90281b20
Using HDDS 0.4.0-alpha
Source code repository https://github.com/apache/hadoop.git -r 4ea602c1ee7b5e1a5560c6cbd096de4b140f776b
Compiled by ajay.kumar on 2019-04-30T03:24Z
Compiled with protoc 2.5.0
From source with checksum 57412e0def0317aed91721fb7ef5
集群启动依赖配置项的设置
下面是集群启动依赖的配置项的设置,配置项如果设的不对,集群相关服务启动会出现一定的问题。在这里会涉及到3个服务角色,它们之间还有一定的依赖关系:
- SCM服务,不需要依赖其它服务,直接自身启动起来即可,为最底层服务。
- OM服务,需要依赖SCM服务,要配置SCM的通信地址。
- Datanode节点服务,需要依赖SCM,OM服务,二者通信地址都得配上。
除了上述3点的地址信息,这里还需要配置它们的元数据放置目录位置。综合前面所述,笔者配置了一个最简单的完整配置文件,内容如下:
<configuration>
<property>
<name>ozone.enabled</name>
<value>true</value>
</property>
<property>
<name>ozone.metadata.dirs</name>
<value>/home/hdfs/data/meta</value>
</property>
<property>
<name>ozone.om.address</name>
<value>lyq-m2:9862</value>
</property>
<property>
<name>ozone.scm.names</name>
<value>lyq-m1</value>
</property>
<property>
<name>ozone.scm.client.address</name>
<value>lyq-m1:9860</value>
</property>
<property>
<name>ozone.scm.datanode.id</name>
<value>/home/hdfs/data/meta/node/datanode.id</value>
</property>
</configuration>
然后按照官网介绍,依次启动服务,启动顺序如下:
1)ozone --daemon start scm
2)ozone --daemon start om
3)ozone --daemon start datanode
SCM和OM各自有独立的UI界面,但是非常类似,这里简单展示SCM服务的UI界面。
SCM首页
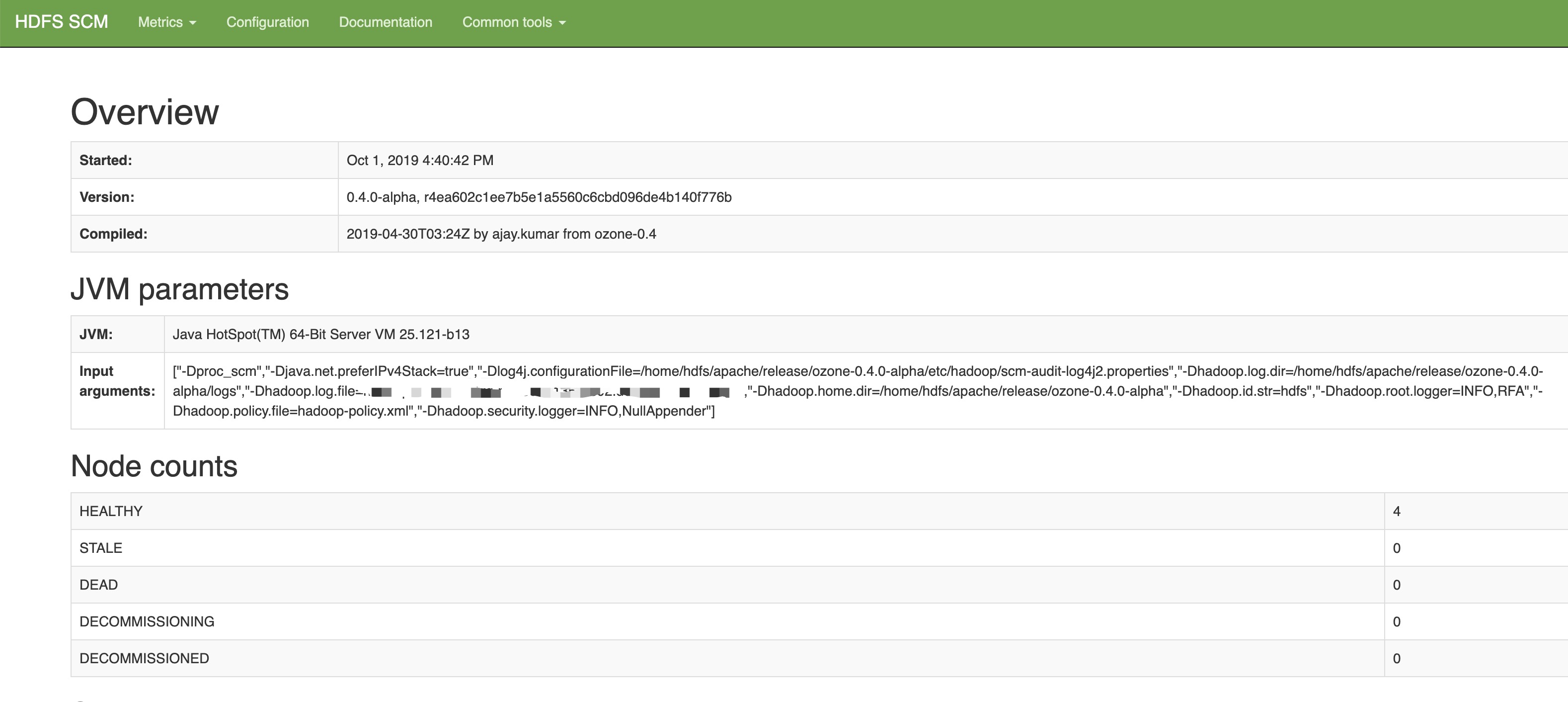
Metric页
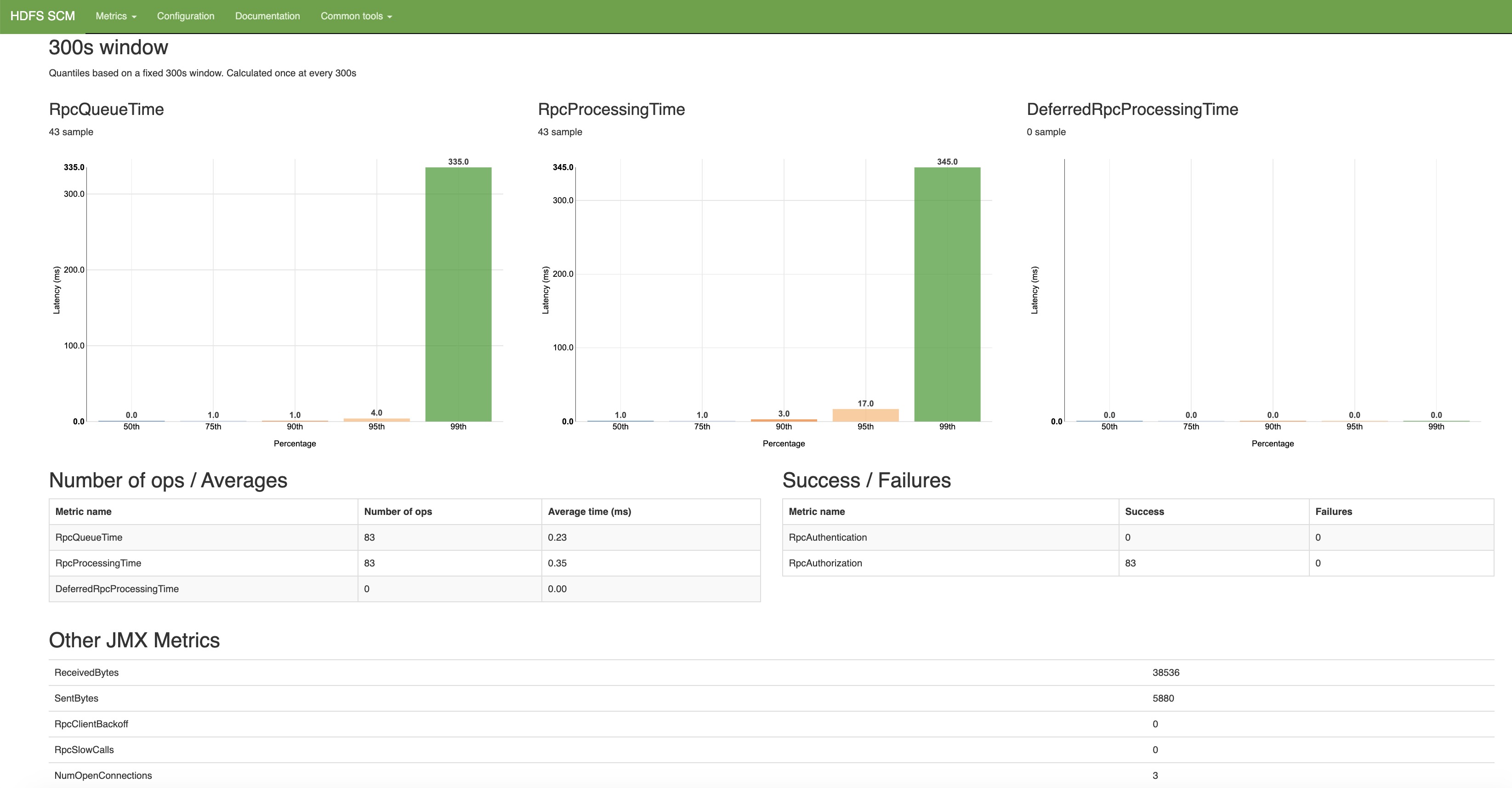
Config页

Tool栏
在界面中,有独立tab页显示配置信息还按照不同ta进行了区分,然后在tool栏多了个stack的功能。Metric信息展示的也比较友好。不过一直让笔者比较不解的是,这里为什么没有节点的详细信息?包括节点capacity,data used这类的信息?
至此Ozone集群的搭建过程宣告完成,下面我们来简单执行ozone命令完成一个小文件的put操作,来验证其对象存储功能。
小文件的对象存储测试
Ozone的对象存储使用方式和亚马逊的S3存储十分类似,也是基于Volume,Bucket,Key的存储模式。
所以在存储key文件对象前,我们需要建好Volume和Bucket。
首先是volume的创建
[hdfs@lyq-s4 ~]$ ozone sh volume create /testvolume1 -q=1GB
2019-09-30 21:22:24,408 [main] INFO - Creating Volume: testvolume1, with hdfs as owner and quota set to 1073741824 bytes.
[hdfs@lyq-s4 ~]$ ozone sh volume list
[ {
“owner” : {
“name” : “hdfs”
},
“quota” : {
“unit” : “GB”,
“size” : 1
},
“volumeName” : “testvolume1”,
“createdOn” : “Tue, 01 Oct 2019 04:22:24 GMT”,
“createdBy” : “hdfs”
} ]
然后是此volume下bucket的创建,
[hdfs@lyq-s4 ~]$ ozone sh bucket create /testvolume1/testbucket
2019-09-30 21:25:20,807 [main] INFO - Creating Bucket: testvolume1/testbucket, with Versioning false and Storage Type set to DISK and Encryption set to false
[hdfs@lyq-s4 ~]$ ozone sh bucket info /testvolume1/testbucket
{
“volumeName” : “testvolume1”,
“bucketName” : “testbucket”,
“createdOn” : “Tue, 01 Oct 2019 04:25:20 GMT”,
“acls” : [ {
“type” : “USER”,
“name” : “hdfs”,
“rights” : “READ_WRITE”
}, {
“type” : “GROUP”,
“name” : “hdfs”,
“rights” : “READ_WRITE”
} ],
“versioning” : “DISABLED”,
“storageType” : “DISK”,
“encryptionKeyName” : “N/A”
}
最后是key文件的上传,这里我们先在本地新建一个测试文件testfile,
[hdfs@lyq-s4 ~]$ ozone sh key put /testvolume1/testbucket/testfile testfile
[hdfs@lyq-s4 ~]$ ozone sh key info /testvolume1/testbucket/testfile
{
“version” : 0,
“md5hash” : null,
“createdOn” : “Tue, 01 Oct 2019 04:30:26 GMT”,
“modifiedOn” : “Tue, 01 Oct 2019 04:30:34 GMT”,
“size” : 12,
“keyName” : “testfile”,
“type” : null,
“keyLocations” : [ {
“containerID” : 1,
“localID” : 102885243413725184,
“length” : 12,
“offset” : 0
} ],
“fileEncryptionInfo” : null
}
然后get这个测试文件到本地,验证其输出内容
[hdfs@lyq-s4 ~]$ ozone sh key get /testvolume1/testbucket/testfile getfile
[hdfs@lyq-s4 ~]$ ls -l
-rw-r–r-- 1 hdfs hdfs 12 Sep 30 21:32 getfile
[hdfs@lyq-s4 ~]$ cat getfile
hello world
以上就是最最基本的文件对象的测试例子,当然了,里面包括了很多别的可选参数使用,比如ACL,replication设置等等这些更高级的用法。笔者在后面的文章中将会提到这些小参数的用法,本文只是一个开始。
引用
[1].https://hadoop.apache.org/ozone/docs/0.4.0-alpha
[2].https://issues.apache.org/jira/browse/HDFS-7240

 浙公网安备 33010602011771号
浙公网安备 33010602011771号