Deformable DETR讲解

2021年ICLR的一篇文章
一、Introduction
DETR的缺点:
1、模型很难收敛,训练困难。相比于现存的检测器,他需要更长的训练时间来收敛,在coco数据集上,他需要500轮来收敛,是faster r-cnn的10到20倍;
2、DETR在小物体检测上性能较差。现存的检测器通常带有多尺度的特征,小物体目标通常在高分辨率特征图上检测,而DETR没有采用多尺度特征来检测,主要是高分辨率的特征图会对DETR增加不可接受的计算复杂度。

基于此,提出了Deformable DETR模型,deformable detr结合了deformable conv的空间稀疏采样优势和transformer的元素间关系建模能力。detr的计算复杂性来自于其中的transformer结构在全局上下文中的注意力计算,而且作者注意到,尽管这种注意力是在全局上下文中计算的,但最终某一个视觉元素只会与很小一部分其他视觉元素通过权重建立起强的联系。
因此deformable detr不再采用全局的注意力计算,只计算reference point周围一小部分点的注意力,而不是计算全局的,这样可以减少计算量,加快收敛速度。
二、Model
(一)Multi-Scale Features & Scale-Level Embedding
DETR使用的是单尺度特征,作者参考以往模型也采用了多尺度的特征来增强检测效果,特别是小目标的检测效果。但并不采取FPN中的特征融合结构,因为deformable attention的方式可以自行的融合不同尺度的特征。

上图是作者对多尺度特征图的选取和处理过程,选择backbone中的C3 C4 C5三个特征层的输出,通过1*1卷积将通道数目都减少到256,另外C5还进行一次3 * 3卷积得到分辨率最低的特征图。右侧四个特征图后续会作为Input。
DETR仅用了单尺度特征,于是对于特征点位置信息的编码,使用的是三角函数,不同位置的特征点会对应不同的编码值。但deformable detr使用的是多尺度特征,位于不同特征层的特征点可能拥有相同的(w,h)坐标,原来的位置编码已经不足以表征多尺度特征图上元素的位置信息了。
对于此,作者提出了一个scale-level embedding,仅用于区分不同特征层,同一特征层中的所有特征点会对应相同的scale-level embedding。它不是利用固定公式算出来的编码,而是随机初始化后跟随网络一起训练的,是可学习的。
在实际使用时,这个 scale-level embedding 与基于三角函数公式计算的 position embedding 相加在一起作为位置信息的嵌入。
(二)Deformable Attention(& Multi-Scale)

上图是detr中使用的原版的nulti-head attention,omega_k代表key的集合,A是注意力图,M代表head集合,z是query的输入特征,x是key和value的输入特征。


这个是本文的deformable attention的公式,与multi-head attention的不同之处是后面的p_g和delta_p_mqk,p_g是reference point,而delta_p_mqk是采样点相对于reference point的偏移位置。
具体过程见下图(图是单尺度的图,公式是多尺度的公式):

(在self-attention中,根据输入特征 I 计算q(【N_q ×C】)、k(【N_k × C】)、v(【HW × C】),然后某一个q与所有的k结合,计算出attention,attention再与所有的v结合,计算得到output。其中k v的shape一般是一样的,因为我们计算完attention之后需要与k对应的v计算输出,而q与输出的shape有关,每个q负责采样k个位置,再与k个value结合得到q对应的那个输出。)
上图中,z【N_q×C】是query的输入特征,在encoder部分的attention模块中N_q=HW即特征图大小,z_q为第q个query所对应的向量,分别通过线性映射、线性映射+softmax,得到采样点偏移和注意力权重(这里的注意力权重不是由q和k计算得来的,而是直接由query的输入特征计算来的,之所以可以这么做,是因为这里的referece point是z_q本身的位置,采样点是reference point加上偏移,而偏移也是由z_q计算得来的,所以采样点的位置是与z_q相关联的,那么根据采样点位置采样插值出来的特征自然就能够和通过query经过线性变换得到的注意力权重对应起来了)。encoder部分,参考点就是z_q自己对应的位置;decoder部分,reference point是由预设的object query经过全连接层和sigmoid归一化得到的。x【HW×C】是value的输入特征,乘以转化矩阵wm'后得到value矩阵。
归一化后的参考点坐标与归一化后的采样点偏移相加,得到采样点的位置,根据采样点位置,使用双线性插值的方法(因为得到的采样点坐标不一定是整数值,所以采用双线性插值来采样)提取出value矩阵中对应的采样点value值,对其施加注意力权重,得到最终输出。

扩展到多尺度时,与上面过程是一样的,只是每个head需要处理来自四个特征层的采样点,上图是多尺度条件下的公式。
下图是各个量的shape:

下图是各个模块之间的关系,可以深入理解一下:
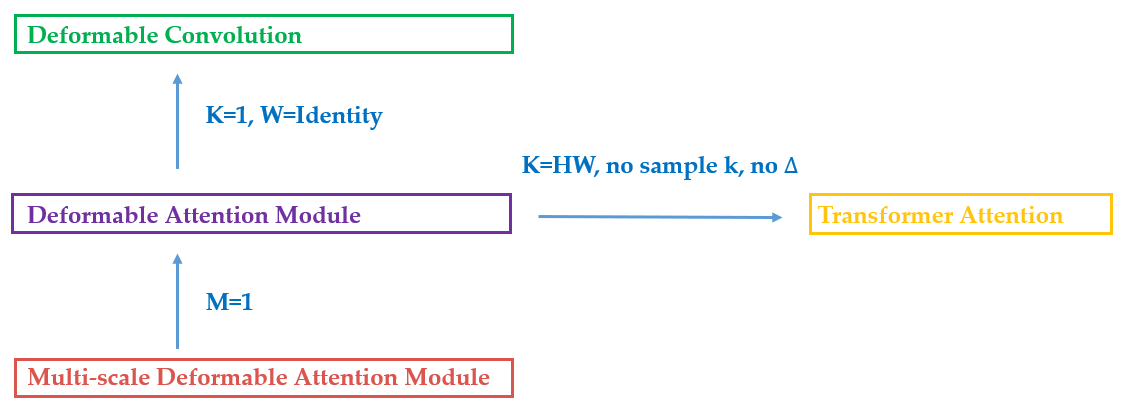
(三)总体的deformable detr结构
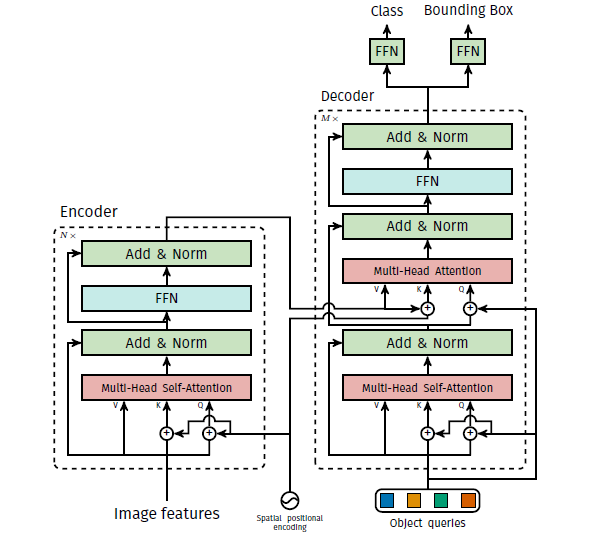
DETR

Encoder部分:将attention模块全部换成multi-scale deformable attention,encoder的输入输出均为多尺度的feature map,保持相同的分辨率;
Decoder部分:有cross-attention和self-attention两种模块,只把cross-attention替换为multi-scale deformable attention,self-attention保留不变。cross attention中的参考点,是由object query【300×C】经过线性映射+sigmoid得到的。
检测头部输出的是参考点的偏移量,文中说这样可以降低一些训练难度。
三、Experiments

Deformable detr大约只需要detr的1/10的epoch就可以收敛;
识别精度相较于detr来说也有比较明显的提高,尤其是在小目标上;
计算量上并没有明显提升;
推理时间有较明显提高。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端