Self-Supervised Learning
Self-Supervised Learning
参考知乎文章:https://zhuanlan.zhihu.com/p/108906502(Self-supervised Learning 再次入门)
自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。首先从大量的无标签数据中通过 pretext 来训练网络,得到预训练的模型,然后对于新的下游任务,和监督学习一样,迁移学习到的参数后微调即可。
自监督学习是一种表征学习。
自监督学习的方法主要可以分为 3 类:1. 基于上下文(Context based) 2. 基于时序(Temporal Based)3. 基于对比(Contrastive Based)
一、基于上下文(Context Based)
(一)Unsupervised Visual Representation Learning by Context Prediction【ICCV_2015】
利用预测图片不同部分的位置关系,这一基于上下文(context based)的辅助任务,来学习得到可以提取目标语义特征的网络。
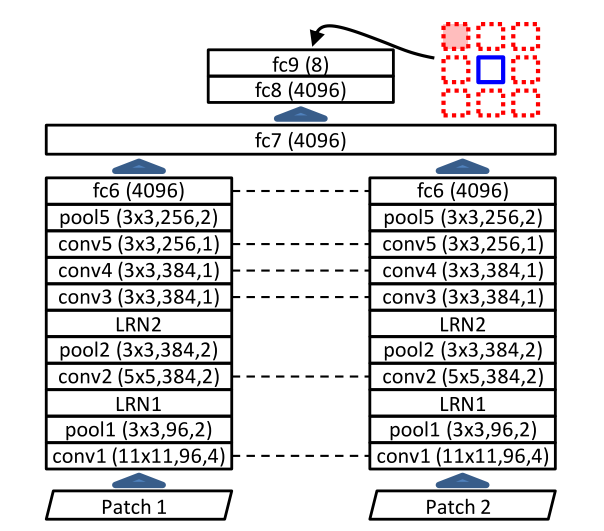
具体来说,首先把一张图片分割成几个patch,然后从中选择一对patch(相邻的两个),输入网络,输出为第二个patch相对于第一个patch的位置,如图中所示。网络如下面第二张图所示,我们的目的是获得关于输入图片的特征,而不是当前网络的预测结果(这只是一个辅助任务)训练完网络后,f6层就可以得到输入图片的语义特征,我们去除掉最后合并的层以及输出层,剩下的两个stack从中选择一个(两个是一样的),将它作为预训练模型,可以应用到图像分类、目标检测等许多的任务中。

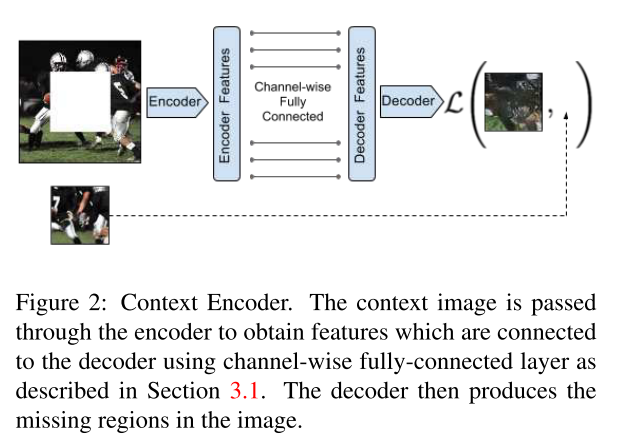
(二)Context Encoders: Feature Learning by Inpainting【CVPR 2016】
通常人们可以通过理解一整幅图像的语义并联系图像中图案的结构来补全一个诠释的图像,本文利用填充图片中缺失部分这一辅助任务来训练模型,旨在让模型理解图像的语义和结构,来获取能够提取图片特征的网络。

本文的模型结构上仿照了Autoencoder的结构,由encoder和decoder两部分,如下图所示。encoder部分输入一张有残缺的图片(残缺的方式有很多种,如下面第二幅图所示,论文中都有分别做尝试),通过encoder提取特征得到feature map,通过通道内部的全连接操作接入到decoder里面,预测输出残缺的部分图像。PS:文中用mask遮罩的方式来处理图片,区分是否是残缺部分。

二、基于时序(Temporal Based)
多在自然语言处理和视频领域使用。
三、基于对比(Contrastive Based)
(一)Momentum Contrast for Unsupervised Visual Representation Learning(CVPR 2020)
参考文章:https://zhuanlan.zhihu.com/p/364446773(何凯明新作MoCo V3!!!探讨一下它的前世与今生)
文章介绍了如何用对比学习去无监督地学习视觉的表征,并提出一种通用的基于对比学习的增量学习方法。
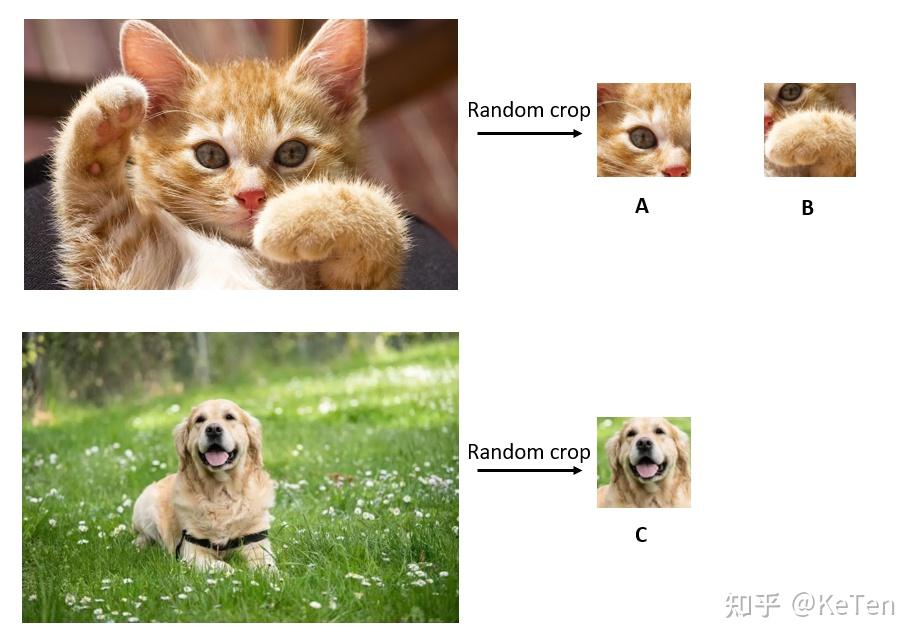
先考虑一个任务,现在有两个图片,图片1和图片2。先在图片1中随机截出两个patch,记作A,B,在图片2中截出一个patch记作C,现在把B和C放到样本库里面,样本库图片的位置随机打乱,然后以A作为查找的对象,让你从样本库中找到与A对应的图片。如下图所示。
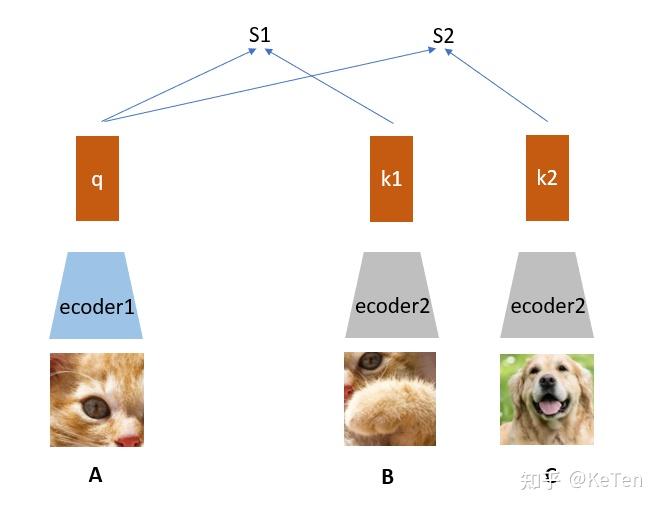
A通过encoder1编码为向量q,接着B、C经过encoder2编码为k1和k2,如下图所示。q和k1算相似度得到S1,q和k2算相似度得到S2。我们的目的是想要让机器学出来A和B是一类(关联性强),而其它不是(关联性弱)。
我们知道A和B是同一张图截出来的,而C不是,因此我们希望S1(A和B的相似度)尽可能高而S2(A和C的相似度)尽可能低。为了做到这一点我们需要把B打上是正类的标签,把C打上是负类的标签,概括性讲就是同一张图片截出来的patch彼此为正类,不同的图片截出来的记为负类。这种方式只需要设定一个规则,然后让机器自动去打上标签,然后基于这些自动打上的标签去学习,无需人工标注。简单来说这篇论文就是通过这种方式,不需要借助手工标注去学习视觉表征。
文中提到的MoCo是通过构建一个动态的负类队列来进行对比学习,依旧通过上面的例子来说,一般要学到好的表征需要比较多的负类样本,而不像是上面只有C一个负类样本,但是由于计算资源限制又不能加入太多的负类样本,并且我们也不希望负类样本是一成不变的,因此就有了“dynamic dictionary with a queue”。下面是论文中的结构示意图:
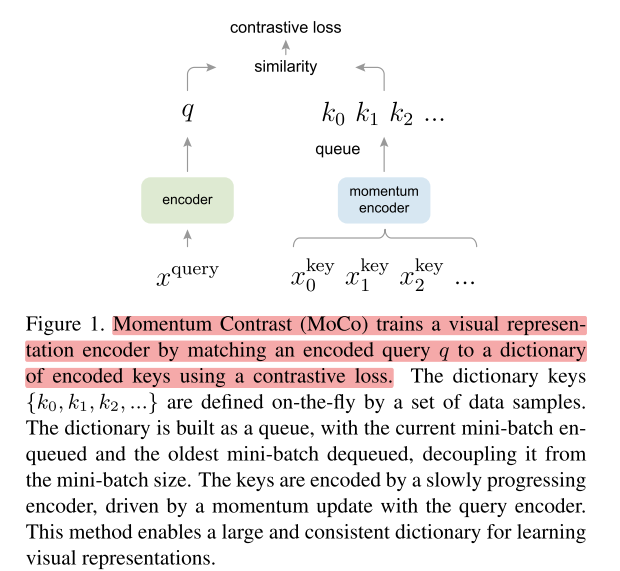
xquery就是要查询的对象。xkey是被查询的对象(包含正样本和负样本)。encoder是一个任意的神经网络,论文中使用的是ResNet,encoder部分的参数是通过反向传播来计算的。momentum encoder论文中提到可以与encoder完全相同、部分相同、不相同都可以,momentum encoder的参数更新是论文的一个创新点,不直接通过反向传播来训练的,而是动量更新,更新的表达式如下:
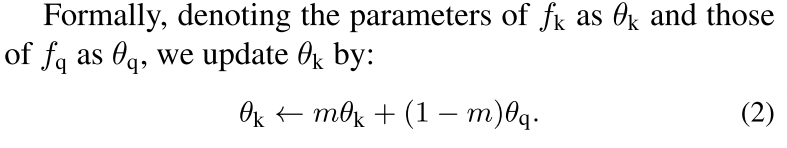
θk是右边encoder的参数,m默认设为0.999,θq是左边编码query的encoder,θq通过反向传播来更新,θk则是通过θq动量更新。为什么采用这样的方式来更新?论文给出的解释是θk直接通过反向传播来更新的效果并不好,因为θk快速的变化会导致key的表征不稳定,但是动量更新很好地解决了这个问题。
contrastive loss的计算有很多不同的形式,论文中的损失函数如下:

下面是整个的算法流程:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端