mask-rcnn notes
mask-rcnn知识总结
论文地址:https://arxiv.org/abs/1703.06870
比较好的论文解读文章:https://zhuanlan.zhihu.com/p/102331538(实例分割算法之Mask R-CNN论文解读)
https://zhuanlan.zhihu.com/p/37998710(令人拍案称奇的Mask RCNN)
b站上一个不错的解读视频:https://www.bilibili.com/video/BV1b441127cs?from=search&seid=1006590812775591497
tensorflow版代码地址:https://github.com/matterport/Mask_RCNN
https://zhuanlan.zhihu.com/p/40314107(tf版源码讲解文章)
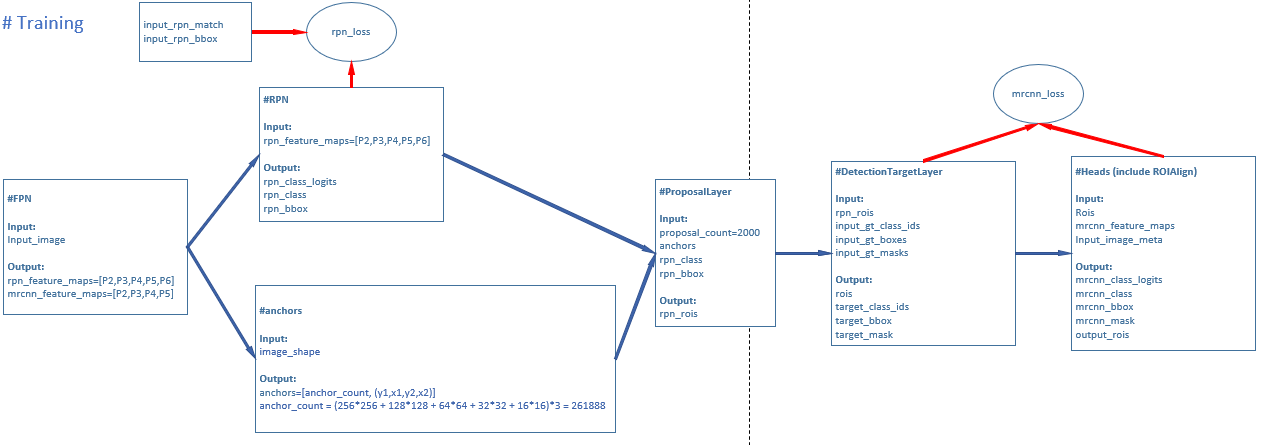
总体结构
mask-rcnn网络主要包括以下几个部分:
1、FPN网络
2、anchors生成部分
3、RPN网络
4、三个预测分支(class、box、mask)
一、FPN网络
特征金字塔,输入一张图片,通过FPN来提取图片的多层次特征(feature map)。论文中使用的是ResNet作为骨架,结构如下:
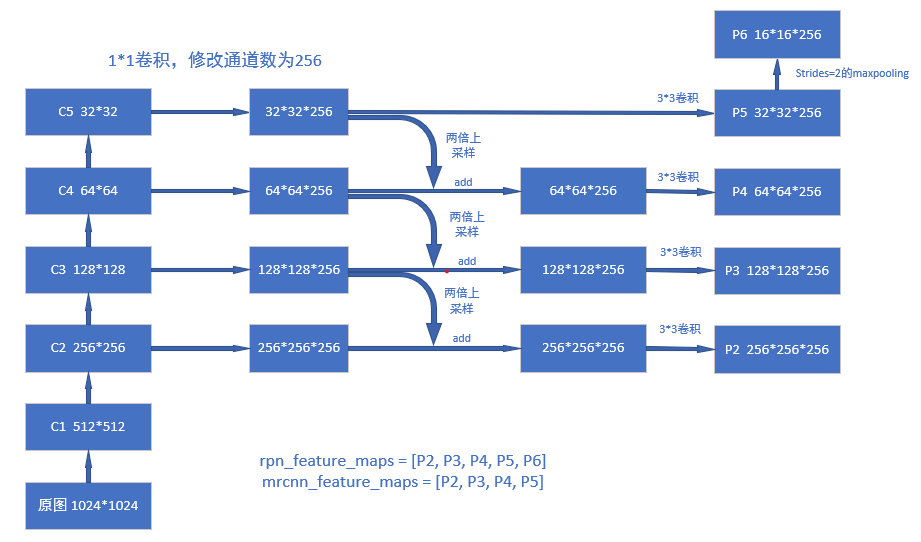
最后得到的P2-P6是图片特征,其中P2-P6用于RPN网路,P2-P5用于分支的训练或预测。
二、anchors生成部分
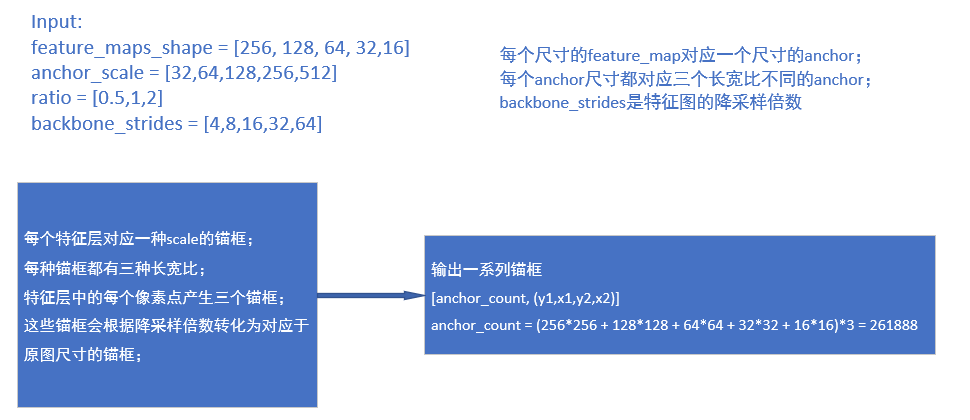
对应着rpn_feature_map中的五个特征层,每一个对应一种scale的锚框。每种锚框会设置三种长宽比,即上图中ratio中的三个比值。这样每个特征层中的每个像素点就对应产生三个锚框,最终输出261888个锚框。
三、RPN网络
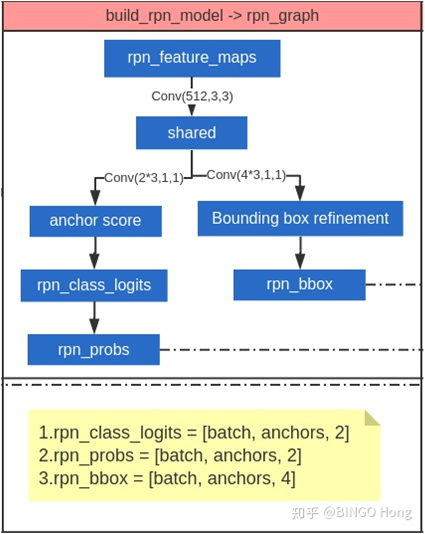
rpn_feature_maps输入到构建好的rpn_model中,会生成每个锚框(每个像素点对应三个)的分类结果,分类结果表征该像素点属于前景(即属于某个物体)或者属于背景,还会生成每个锚框的边界bbx。因为前面生成的261888个anchors太多了,所以下一步将根据这些数据来筛选anchors。
PS:这里可能有个疑问,rpn model为什么能计算出这些分类结果以及边界框。这属于rpn网络的训练部分,在训练阶段,整个mask-rcnn网络的输入除了图片之外还有图片对应的labels,在训练时rpn model的输出会与输入的label进行对比计算loss。整个rpn网路的作用,就是生成并精炼出一部分anchors以及对应的标签,以供后面分支网络进行预测。在训练阶段训练这种能力才可以在预测阶段,在没有label只有image的情况下进行anchors的生成和精炼。
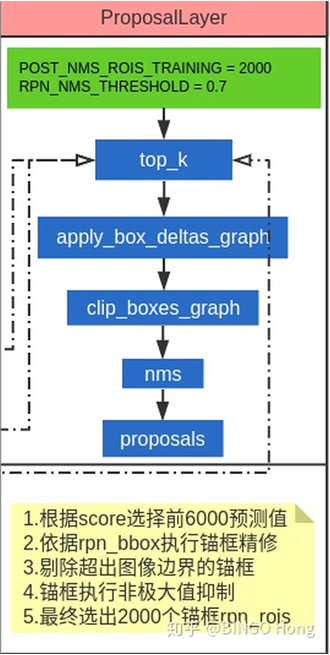
根据前面rpn model生成的锚框的标签,在proposallayer中对anchors进行筛选,根据图片中的步骤,最终筛选出2000个anchors,我们称之为roi(region of interest)。在测试阶段只筛选出1000个即可。
PS:这里补充说明下NMS(非极大抑制)的机制
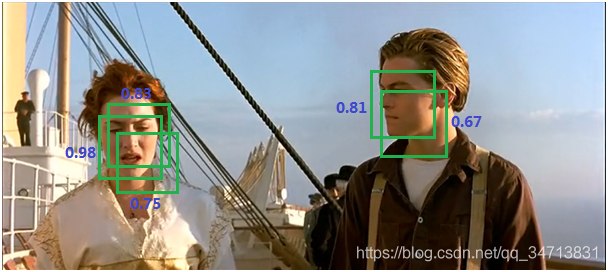
由于锚点经常重叠,因此建议最终也会在同一个目标上重叠。为了解决重复建议的问题,我们使用一个简单的算法,称为非极大抑制(NMS)。NMS 获取按照分数排序的建议列表并对已排序的列表进行迭代,丢弃那些 IoU 值大于某个预定义阈值的建议,并提出一个具有更高分数的建议。总之,抑制的过程是一个迭代-遍历-消除的过程。如图所示
将所有候选框的得分进行排序,选中最高分及其所对应的BB;
遍历其余的框,如果它和当前最高得分框的重叠面积大于一定的阈值,我们将其删除;
从没有处理的框中继续选择一个得分最高的,重复上述过程。
下面部分的筛选只在训练阶段才有:
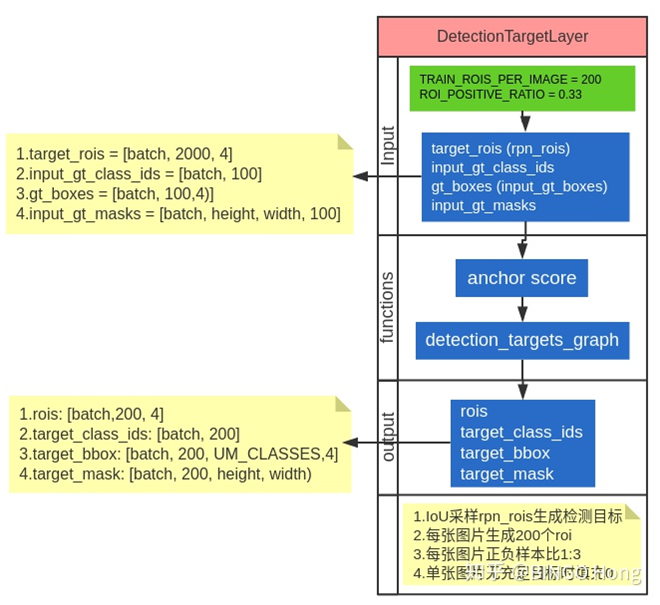
target_rois是第二部分ProposalLayer筛选提供的2000个区域建议框,在训练时,2000个显得太多,所以会进一步筛选为200个做为target。最终生成的200个roi以及对应的标签数据将送入三个分支网络中。
在筛选过程中,首先将2000个roi的边界框与输入的groundtruth计算IOU(可以理解为重叠面积的多少),IOU大于0.5的标记为正样本,小于0.5的标记为负样本。按照网络的参数设置,每张图片的正负样本比例为1:3,每张图片的总样本数目为200,按照上述数量要求从正负样本中随机选取指定数目样本,再根据输入的gt值计算出每个roi的标签(class, delte, mask)。这里注意一点,我从代码中看,只有正样本才进行这些标签的计算,负样本直接进行了零填充,但这一点我也不是太肯定就是这样...
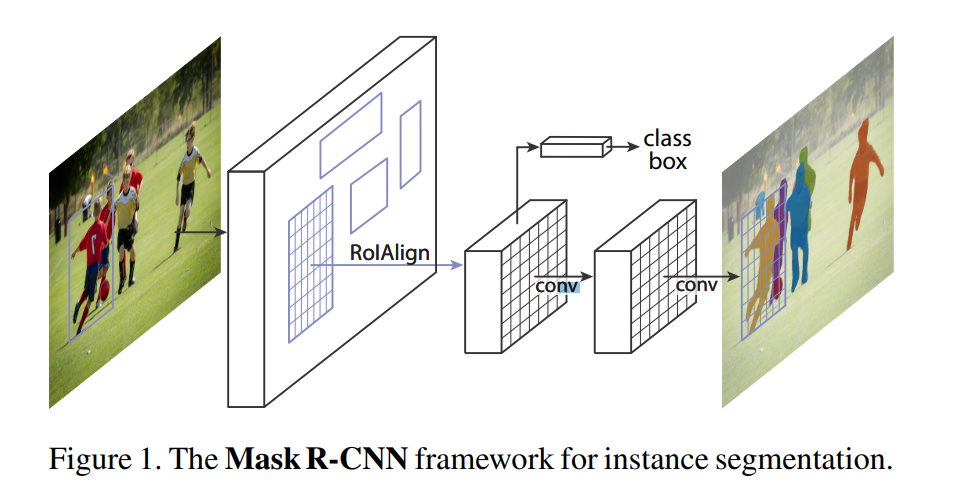
四、三个预测分支(class、box、mask)
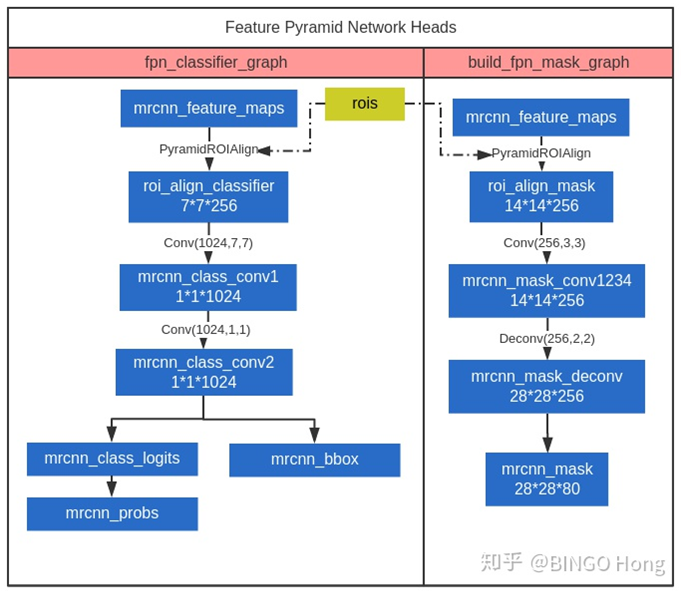
PyramidROIAlign这一步,输入detectionlayer导出 的200个roi和p2-p5四个feature_map,按照公式计算当前roi需要从哪一个feature_map上进行切割,然后进行切割,对切下来的特征进行align变换,使得其形状变为7×7或14×14。
整体FPN heads分为三个分支,分别用于分类、回归目标框偏移、像素分割,都是将rois在对应mrcnn_feature_maps特征层进行roialign特征提取,然后再经过各自的卷积操作预测最终结果。mask分支的输出有80个通道,对应着网络要求的80个类对于其中一个像素点,其对应一个长度为80的向量,其中只有一个为1,其余为0。
在训练阶段,三个分支进行并行计算。
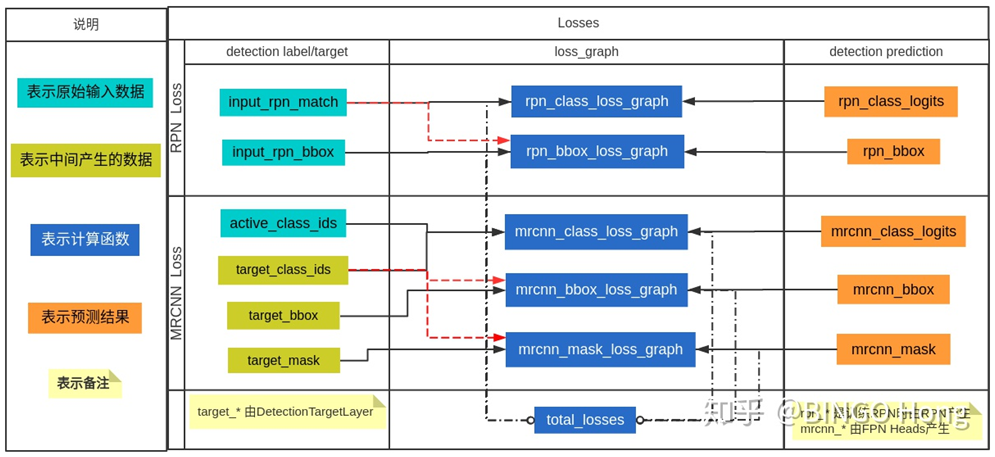
关于训练阶段的损失计算,mask分支的损失计算,需要使用class分支的输出,知道roi属于哪个种类后,在mrcnn_mask的80个通道中选择该种类对应的那一个通道(其他通道在计算损失时不考虑,论文中指出这样做可以降低其他种类的影响)。对于另外两个分支,将他们的输出结果与前面detectiontargetlayer层得到的每一个roi的标签进行比较计算,得到loss。最终三个分支的损失加上前面rpn网络计算的损失,作为该网络的总损失。
关于损失计算,可参见下图:
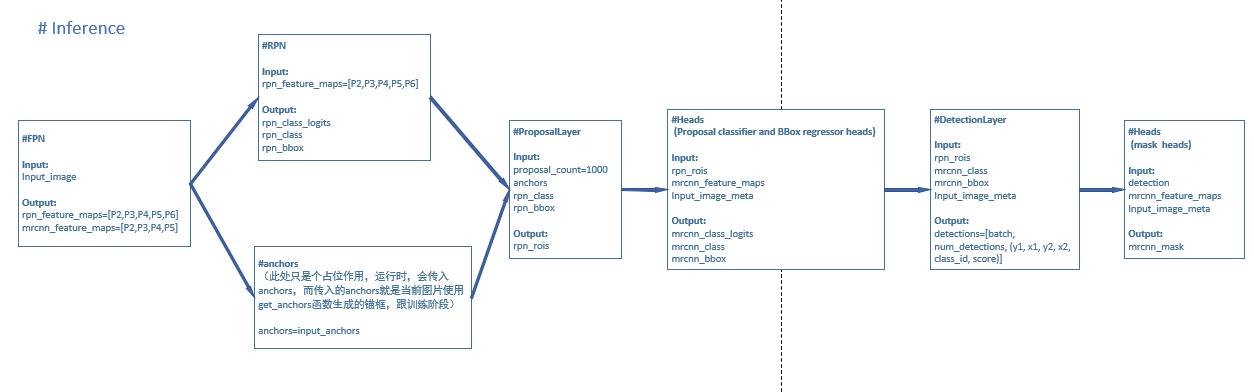
五、预测阶段
在预测阶段,即论文中提到的inference阶段,与训练阶段的区别在于:
1、rpn阶段不需要计算损失值,因为输入的只有图片,没有标签了。
2、在proposallayer层,会筛选出1000个roi,而不是2000个
3、训练阶段的detectiontargetlayer部分去掉,不再对1000个roi进行第二次筛选,而是1000个直接作为class分支和bbox分支的输入
4、mask分支不再与class分支和bbox分支进行并行计算,而是先计算class分支和bbox分支,再将得到的边界框和类别输入到mask分支中,选取输出中对应类别的mask