DeepLab-v3
DeepLab-v3(86.9 mIOU)
论文地址:https://arxiv.org/pdf/1706.05587.pdf(Rethinking Atrous Convolution for Semantic Image Segmentation)
讲解文章:https://blog.csdn.net/qq_14845119/article/details/102942576
参考项目:https://github.com/fregu856/deeplabv3
一、模型
(一)空洞卷积
同v2版本
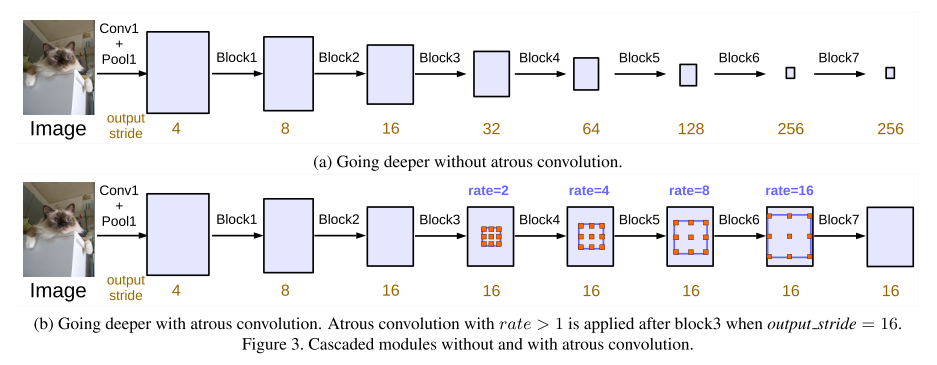
(二)Going deeper
(三)ASPP with BN ( batch normalization )
v3版本的ASPP相对于v2有了一些改进。
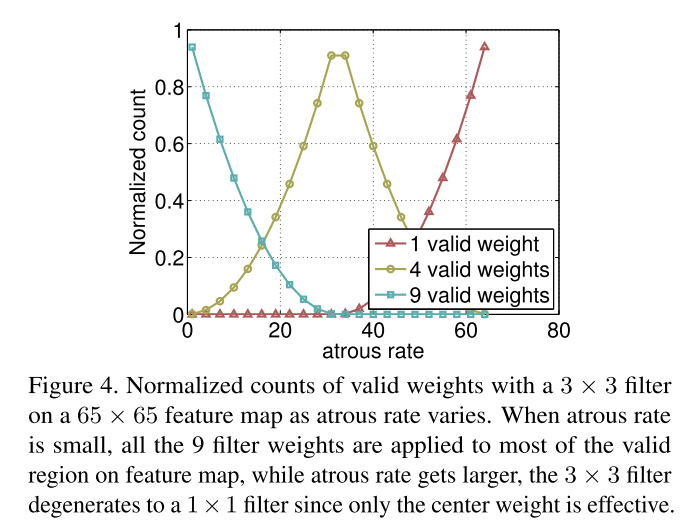
如上图所示,随着rate的变大,有效的卷积区域变得越来越少。在极端情况下,即rate = feature map size时,空洞卷积核的有效卷积区域只有1。为了解决这一问题,作者对ASPP进行了以下改进:
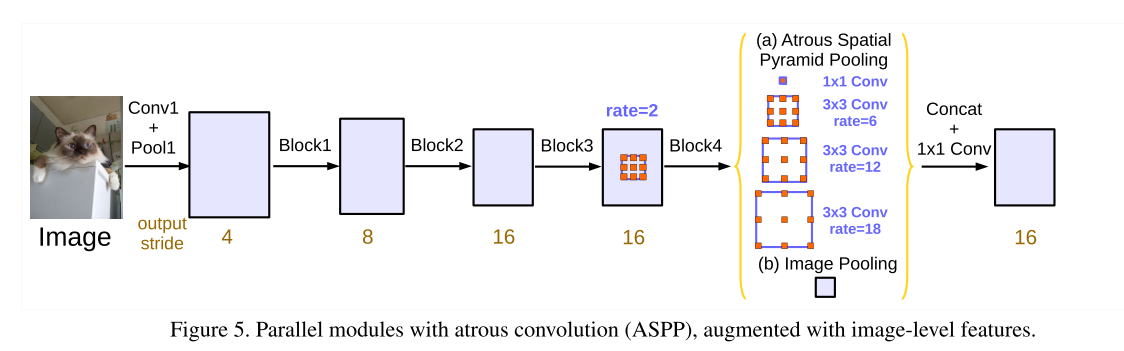
上图中黄色括号括起的部分就是改进之后的ASPP,对于输入的scores map,分别进行五个平行处理:①1×1卷积;②3×3的rate=6的空洞卷积;③3×3的rate=12的空洞卷积;④3×3的rate=18的空洞卷积;⑤全局平均池化+双线性插值上采样。五个操作的输出的尺寸是相同的,对于这五个输出在通道维度上进行concate;然后再进行1×1的卷积。
下面是得到原图大小1/16的scores map的例子:
class ASPP(nn.Module):
def __init__(self, num_classes):
super(ASPP, self).__init__()
self.conv_1x1_1 = nn.Conv2d(512, 256, kernel_size=1)
self.bn_conv_1x1_1 = nn.BatchNorm2d(256)
self.conv_3x3_1 = nn.Conv2d(512, 256, kernel_size=3, stride=1, padding=6, dilation=6)
self.bn_conv_3x3_1 = nn.BatchNorm2d(256)
self.conv_3x3_2 = nn.Conv2d(512, 256, kernel_size=3, stride=1, padding=12, dilation=12)
self.bn_conv_3x3_2 = nn.BatchNorm2d(256)
self.conv_3x3_3 = nn.Conv2d(512, 256, kernel_size=3, stride=1, padding=18, dilation=18)
self.bn_conv_3x3_3 = nn.BatchNorm2d(256)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_1x1_2 = nn.Conv2d(512, 256, kernel_size=1)
self.bn_conv_1x1_2 = nn.BatchNorm2d(256)
self.conv_1x1_3 = nn.Conv2d(1280, 256, kernel_size=1) # (1280 = 5*256)
self.bn_conv_1x1_3 = nn.BatchNorm2d(256)
self.conv_1x1_4 = nn.Conv2d(256, num_classes, kernel_size=1)
def forward(self, feature_map):
# (feature_map has shape (batch_size, 512, h/16, w/16))
feature_map_h = feature_map.size()[2] # (== h/16)
feature_map_w = feature_map.size()[3] # (== w/16)
out_1x1 = F.relu(self.bn_conv_1x1_1(self.conv_1x1_1(feature_map))) # (shape: (batch_size, 256, h/16, w/16))
out_3x3_1 = F.relu(self.bn_conv_3x3_1(self.conv_3x3_1(feature_map))) # (shape: (batch_size, 256, h/16, w/16))
out_3x3_2 = F.relu(self.bn_conv_3x3_2(self.conv_3x3_2(feature_map))) # (shape: (batch_size, 256, h/16, w/16))
out_3x3_3 = F.relu(self.bn_conv_3x3_3(self.conv_3x3_3(feature_map))) # (shape: (batch_size, 256, h/16, w/16))
out_img = self.avg_pool(feature_map) # (shape: (batch_size, 512, 1, 1))
out_img = F.relu(self.bn_conv_1x1_2(self.conv_1x1_2(out_img))) # (shape: (batch_size, 256, 1, 1))
out_img = F.upsample(out_img, size=(feature_map_h, feature_map_w), mode="bilinear") # (shape: (batch_size, 256, h/16, w/16))
out = torch.cat([out_1x1, out_3x3_1, out_3x3_2, out_3x3_3, out_img], 1) # (shape: (batch_size, 1280, h/16, w/16))
out = F.relu(self.bn_conv_1x1_3(self.conv_1x1_3(out))) # (shape: (batch_size, 256, h/16, w/16))
out = self.conv_1x1_4(out) # (shape: (batch_size, num_classes, h/16, w/16))
return out
经过ASPP之后,再通过上线性插值上采样恢复到原图尺寸,就得到了最终的分割图。在v3中作者没有对scores map进行CRF处理。
总的模型过程比较简单,可以分成下面三步:
feature_map = self.resnet(x) # (shape: (batch_size, 512, h/16, w/16))
output = self.aspp(feature_map) # (shape: (batch_size, num_classes, h/16, w/16))
output = F.upsample(output, size=(h, w), mode="bilinear") # (shape: (batch_size, num_classes, h, w))
return output
二、实验
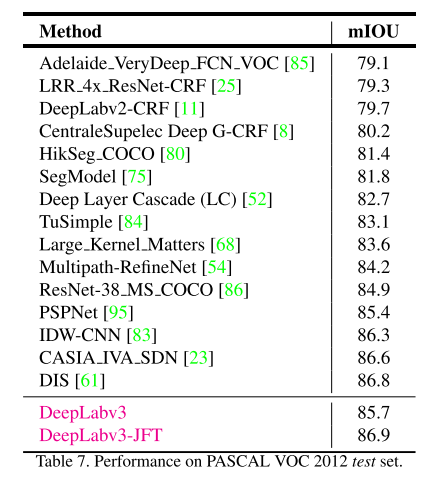
最高可以达到86.9mIOU


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端