DeepLab-v1
DeepLab-v1(71.6 mIOU)
参考文章:https://zhuanlan.zhihu.com/p/22308032(图像语义分割之FCN和CRF)
论文地址:https://arxiv.org/pdf/1412.7062v3.pdf
DeepLab可以换分为两部分:
前端使用带空洞卷积(Atrous Convolution)的FCN提取二维特征图;
后端采用CRF(条件随机场)来优化前端输出,最后得到分割图。
一、模型结构
(一)前端FCN部分(空洞卷积,控制感受野)
分类使用的网络通常会在最后连接几层全连接层,它会将原来二维的矩阵(图片)压扁成一维的,从而丢失了空间信息,最后训练输出一个标量作为分类标签。而图像分割的输出需要是一个二维的分割图,因此采用全卷积网络FCN来提取特征。
FCN为了保证之后输出的尺寸不至于太小,FCN的作者在第一层直接对原图加了100的padding,可想而知,这会引入噪声。
而怎样才能保证输出的尺寸不会太小而又不会产生加100 padding这样的做法呢?可能有人会说减少池化层不就行了,这样理论上是可以的,但是这样直接就改变了原先可用的结构了,而且最重要的一点是就不能用以前的结构参数进行fine-tune了。所以,Deeplab这里使用了一个非常优雅的做法:将pooling的stride改为1,再加上 1 padding。这样池化后的图片尺寸并未减小,并且依然保留了池化整合特征的特性。
但是,修改了pooling layer之后,因为池化层变了,后面的卷积的感受野也对应的改变了(由于修改后的池化层不再缩小输入图像的大小,那么后面卷积出来的像素的感受野会变小),这样也不能进行fine-tune了。所以,Deeplab提出了一种新的卷积,空洞卷积:Atrous Convolution.即:
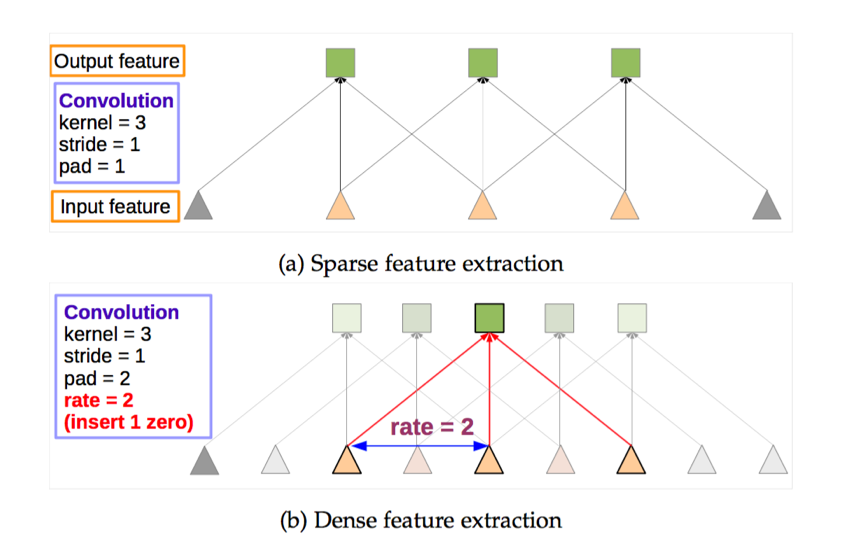
空洞卷积会增大卷积时的感受野,抵消掉池化层对感受野的影响,保证这样的池化后的感受野不变,从而可以fine tune,同时也能保证输出的结果更加精细。
对卷积出的scores map,论文中对其进行固定参数的双线性插值上采样(文中指出上采样率为8),恢复到原图的分辨率,即最后得到一个原图大小的scores map。后面再进行CRF处理。
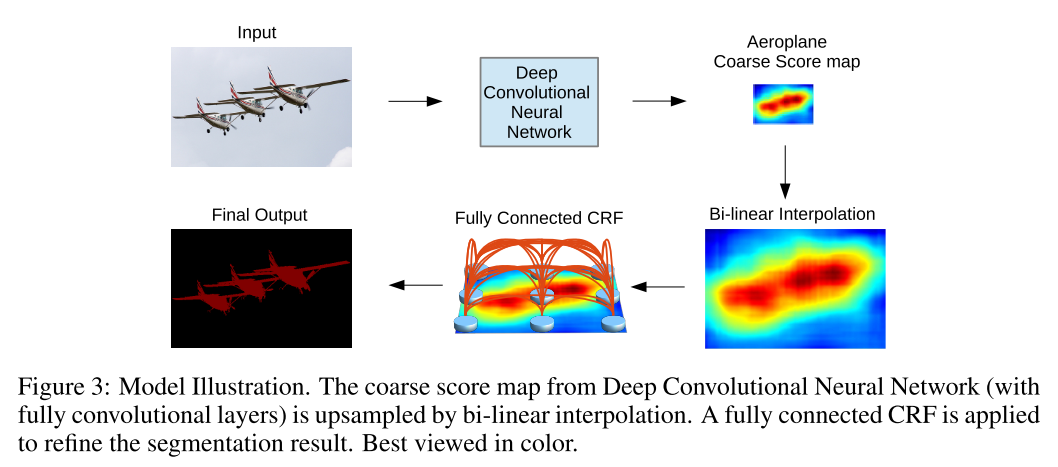
(二)后端CRF(条件随机场)
条件随机场可以优化物体的边界,平滑带噪声的分割结果,去掉物体中间的预测的孔洞,使得分割结果更加准确
(没太搞明白条件随机场)
(三)muti-scale多尺度预测
类似于FCN的skip结构的效果,作者在输入图片、前四个pooling层的后面都增加了一个两层的MLP结构(第一层是128 3×3的卷积,第二层是128 1×1的卷积),这些MLP的输出都concate到最后输出的feature map中,共同参与最后的softmax层。
二、实验结果
(一)
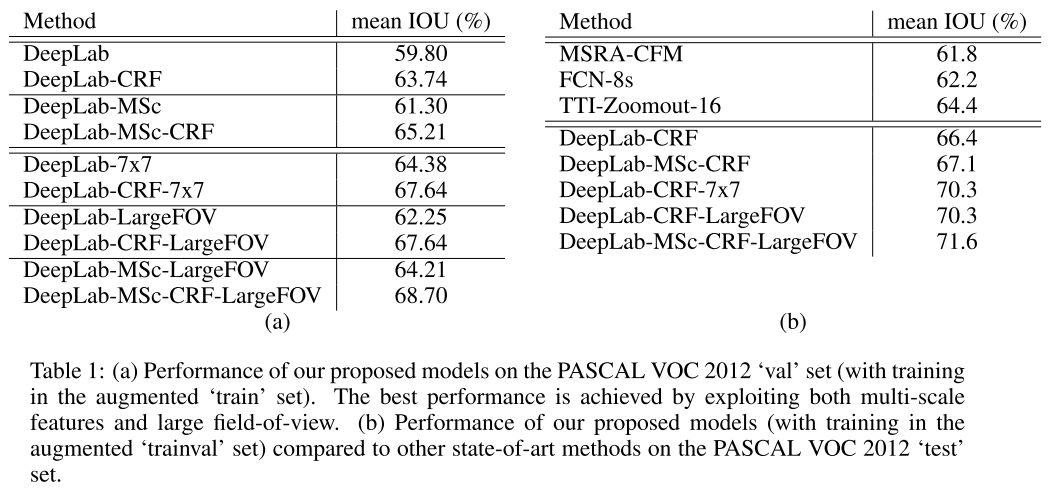
左侧表,
CRF表示后端使用条件随机场来处理,
MSc表示使用muti-scale机制,
LargeFOV表示大感受野。空洞卷积的kernal size和stride可以控制感受野的大小,所以作者实验了多组参数,找出了效果好,且计算量小的一组,kernal size为3×3,stride是12,即左侧图中带有LargeFOV标识的。
由上图可以看出,同时使用CRF、MSc、LargeFOV的最后一行的模型,效果最好,达到了68.7%的mean IOU。
右表是论文模型和其他一些模型的对比(与左侧图中数据不同是因为它们基于的数据集不同,仔细看图标下面的原文解释)。
(二)
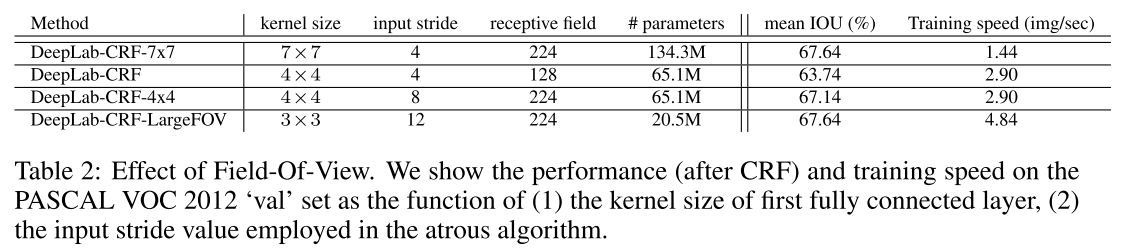
该图展示的是不同的感受野(即设置不同的kernal size和input stride来控制感受野的不同),所带给模型的影响。第四行的模型实现了与第一行相同的感受野,且在计算量上有优势。
(三)

上图可视化展示了,muti-scale的作用,第一行是不采用MSc的,第二行是使用的。显然从图中可以看出使用MSc边界刻画的更准确一些。
(四)

上图展示的是本文的模型与其他模型的效果对比图,第二行是groundtruth,第三行左侧是FCN-8s,右侧是TTI-Zoomout-16,第四行是本文模型。

