Fully Convolutional Networks
Fully Convolutional Networks (2015)
图像分割即对每一个像素进行预测
我们分类使用的网络通常会在最后连接几层全连接层,它会将原来二维的矩阵(图片)压扁成一维的,从而丢失了空间信息,最后训练输出一个标量,这就是我们的分类标签。而图像语义分割的输出需要是个分割图,且不论尺寸大小,但是至少是二维的。所以,我们需要丢弃全连接层,换上全卷积层,而这就是全卷积网络了
一、模型
(1)
(2)
(3)
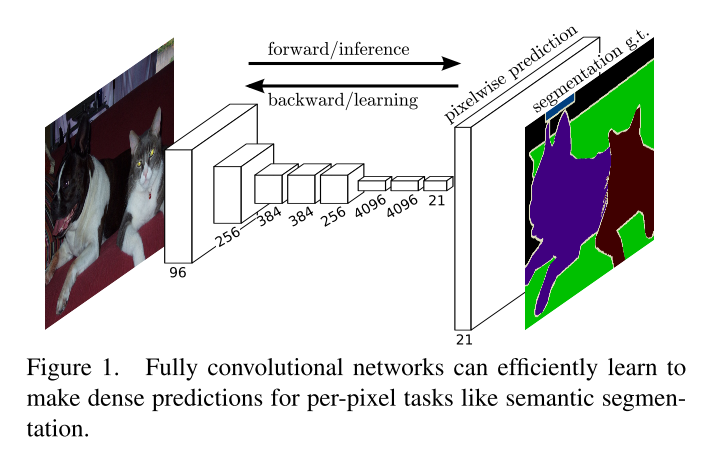
上面图一描绘的是FCN的整体结构,前面特征提取的网络可以采用一些成功的分类网络(如VGG等),参数带入进来再进行一些微调就好。对图像的特征提取后(即下采样后),再采用反卷积的方式对特征图进行上采样,恢复到原图的尺寸,这样来实现图像的分割。
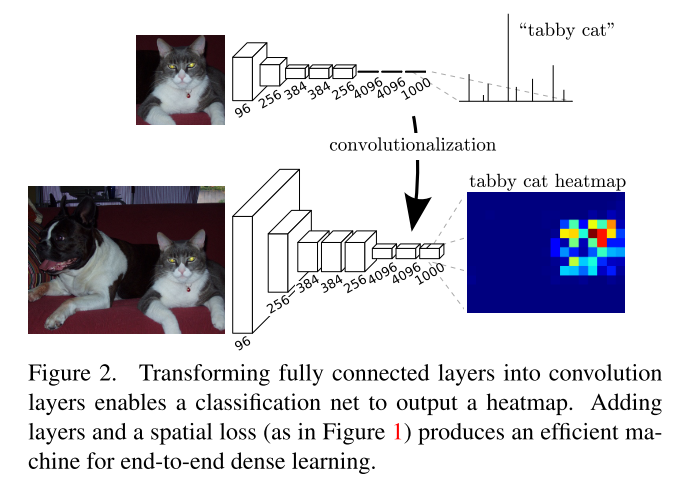
图二是展示的将分类网络迁移进FCN。
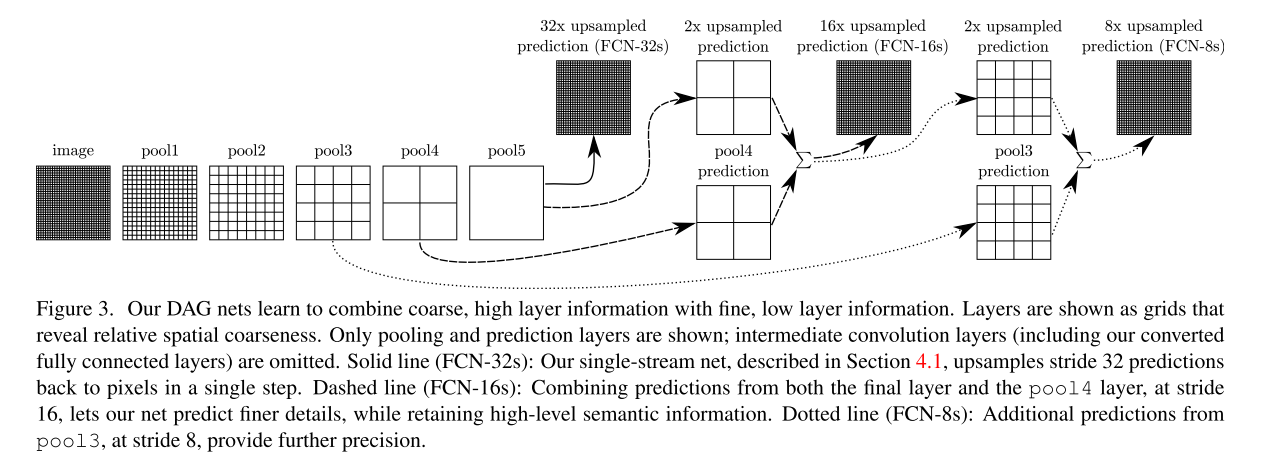
论文中提到的三种FCN结构:FCN-8s、FCN-16s、FCN-32s,每一个对前面不同尺度的特征结合程度不同,数字代表最后一层进行几倍的上采样。
二、实验

FCN-8s与SDS、R-CNN的比较,FCN-8s在PASCAL VOC2011和2012测试集上的mean IU分别达到了62.7和62.2。

FCN-8s和几个当时比较先进的分割模型输出的结果的对比。(注:最后一行,那个救生艇上面不是人,全是救生衣...)。
三、待改进之处
1、FCN为了使得前面部分卷积池化之后输出的特征图尺寸不要太小,作者在第一层直接对原图加了100的padding,可想而知,这会引入噪声
四、意义
1、FCN的意义在于,它首次将深度学习引入到图像分割的领域。通过去除分类网络后面全连接层的方式,来获取到二维的特征图(虽然分辨率只有原图的1/32),再用反卷积(上采样)的方式来根据二维特征图还原成最终输出。
2、FCN的主要特点归为三点:卷积化、上采样、skip结构

 浙公网安备 33010602011771号
浙公网安备 33010602011771号