

理论基础 —— 图 —— 图的存储结构
【邻接矩阵】
图的邻接矩阵存储也称数组表示法,其方法是用一个一维数组存储图中的顶点,用一个二维数组存储图中的所有的边,存储顶点之间邻接关系的二维数组称为邻接矩阵。
设图 G=(V,E) 具有 n 个顶点,则其邻接矩阵是一个 n*n 的方阵,定义为:
若 G 是网图,则有:
,其中
是边 (vi,vj) 或 弧 <vi,vj> 上的权值,INF 代表一极大的数,其大于所有边的权值。
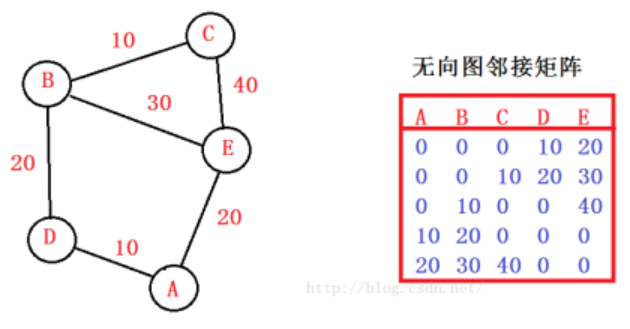
其对确定边操作效率高,但由于其过高的空间复杂度,对稀疏图来说造成了极大的浪费,且由于二维数组可开的空间范围有限,因此邻接矩阵一般适用于点较少的图。
int n;
int G[N][N];
void init(){
memset(g,0,sizeof(g));//图的初始化
cin>>n;//读入数据个数
while(n--){
cin>>i>>j>>w;//读入两个顶点序号及权值
G[i][j]=w;//对于不带权的图,可令g[i][j]=1
G[j][i]=w;//无向图的对称性,若是有向图,没有此句
}
}【邻接表】
邻接表是一种顺序存储与链接存储相结合的存储方法,类似于树的孩子链表表示法。
对于图 G 的每个顶点 vi,将所有邻接于 vi 的顶点链成一个单链表,称为 vi 的边表,若图 G 是一有向图,则称为 vi 的出边表。
为方便对所有边表的头指针进行存储操作,使用顺序存储,这样,存储边表头指针的数组和存储顶点信息的数组构成了邻接表的表头数组,称为顶点表。
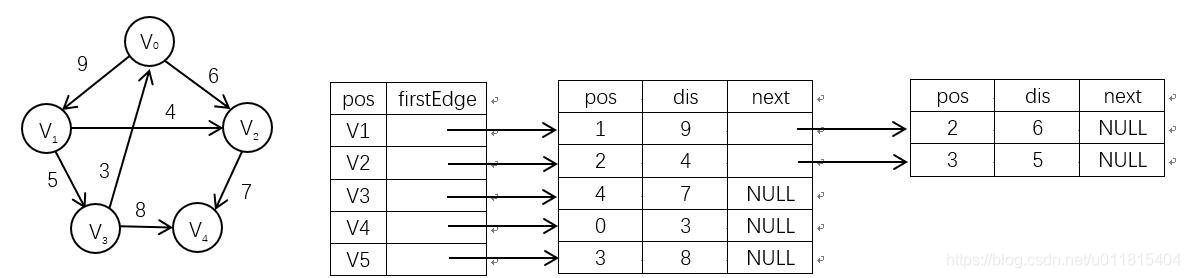
相较于邻接矩阵,其由数组转链表,由定长转不定长,内存利用率高,能较好的处理稀疏图,对不确定的边操作较为方便,但由于存储方式的问题,其对重边不好处理,且对确定边处理效率并不高。
struct Edge{//边表
int pos;//位置域,存放该顶点的邻接点在顶点表中的下标
int dis;//数据域,对于网图,增设一存取边上信息的域
Edge *next;//指针域,指向边表中下一结点
};
struct Node{//顶点表
int pos;//位置域,存放顶点信息
Edge *firstEdge;//指针域,指向边表中的第一个结点
}node[N];
int n,m;
void init(){
for(int i=0;i<n;i++){//n个点
cin>>node[i].pos;
node[i].firstEdge=NULL;
}
for(int i=0;i<m;i++){//m条边
int x,y;
cin>>x>>y;//边所依附的两点编号
Edge *p;//边表结点
//添边x->y
p->pos=y;
p->next=node[x].firstEdge;
node[x].firstEdge=p;
//添边y->x
p->pos=x;
p->next=node[y].firstEdge;
node[y].firstEdge=p;
}
}【前向星】
对于邻接矩阵来说,其方便但效率低,对于邻接表来说,其虽效率较高但实现较为困难,而前向星就是一个介于两者之间的较为中庸的结构,其虽然好写,但效率较邻接表来说较低,且其不能直接用顶点进行定位,对重边不好处理,只能与邻接表一样遍历判重。
前向星以储存边的方式来存储图,其通过读入每条边的信息,将边存放在数组中,把数组中的边按照起点顺序排序进行构造。
常用于具有多个点或两点间具有多条弧的情况,其缺点是不能直接用顶点进行定位。
int n,m;
vector<int> edge[N];
void init(){
cin>>n>>m;
for(int i=0;i<m;i++){
int x,y;
cin>>x>>y;//边所依附的两点编号
edge[x].push_back(y);//添边x->y
edge[y].push_back(x);//添边y->x
}
}【链式前向星】
由于前向星的效率并不高,因此可对其进行优化,在优化为链式前向星后,内存利用率极高,效率也得到了极大的提升,在图论题中,链式前向星可适用于所有的图。
但经过优化后,其缺点也很明显,即:操作复杂化、不好处理重边等
struct Edge{
int next;//下一条边的数组下标
int to;//该边的另一个顶点
int dis;//该边的权值
}edge[N];
int n,m;//点数,边数
int head[N];//head[i]表示顶点i的第一条边的数组下标,-1表示顶点i没有边
int tot;//边的条数即边序号
void addEdge(int from,int to,int dis){
edge[tot].dis=dis;//权值
edge[tot].to=to;//另一顶点
edge[tot].next=head[from];//同结点下该边的下一条边
head[from]=tot++;//结点from的第一条边
}
int mian(){
memset(head,-1,sizeof(head));
tot=0;
for(int i=0;i<m;i++){
int x,y,w;
scanf("%d%d%d",&x,&y,&w);
addEdge(x,y,w);//添边x->y
addEdge(y,x,w);//添边y->x
}
//遍历从x出发的所有边
int x=0;
for(int i=head[x];i!=-1;i=edge[i].next){
int y=edge[i].to;
...
}
...
return 0;
}【十字链表与邻接多重表】
十字链表与邻接多重表也是图的一种存储方法,但由于操作复杂、内存利用率不高等因素常不被使用。
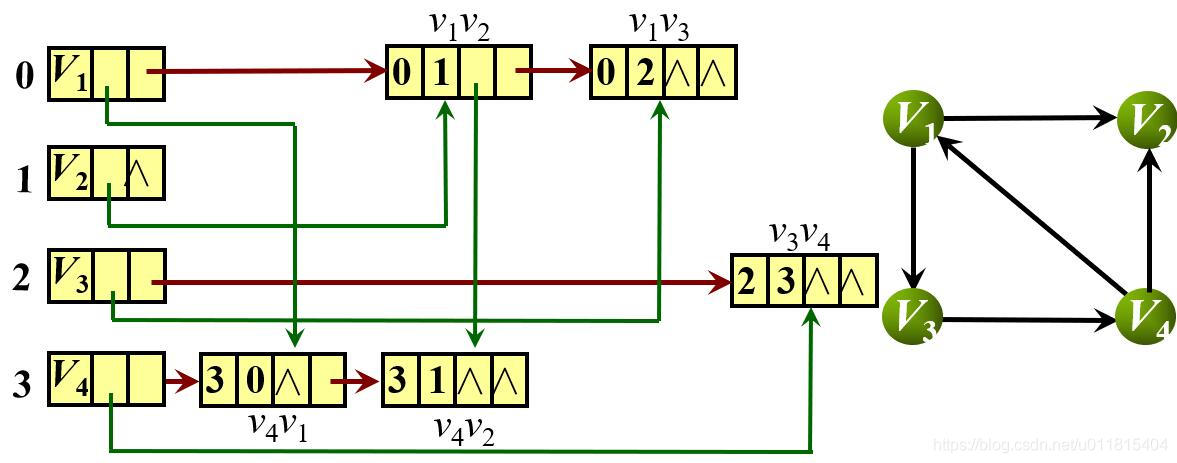
1.十字链表
十字链表是有向图的一种存储方法,其实质上是邻接表与逆邻接表的结合,每条边对应的边结点分别组织到出边表与入边表中,其顶点表和边表结点结构如下:
对于顶点表来说,data 为数据域,存放顶点信息;firstIn 为入边表头指针,指向以该顶点为终点的弧构成的链表中的第一个结点;firstOut 为出边表头指针,指向以该顶点为始点的弧构成的链表中的第一个结点。
对于边表来说,tailPos 代表弧的起点在顶点表中的下标;headPos 代表弧的终点在顶点表中的下标;headLink 为入边表指针域,指向终点相同的下一条边;tailLink 为出边表指针域,指向起点相同的下一条边。
2.邻接多重表
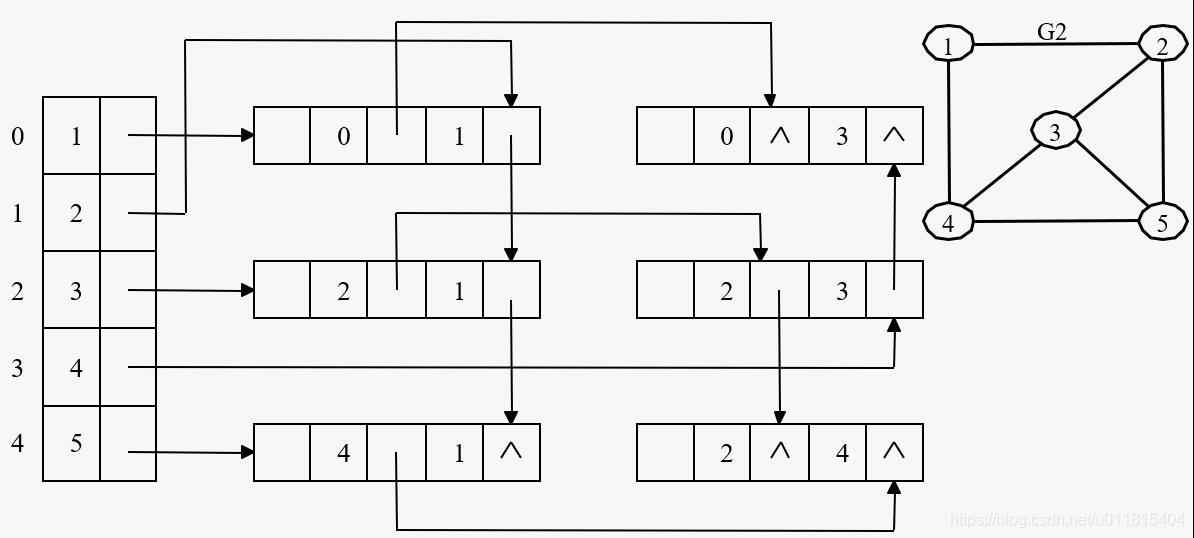
用邻接表存储无向图,每条边的两个顶点分别在以该边所依附的两个顶点的边表中,这种重复存储给图的某些操作带来不便,因此有了邻接多重表。
邻接多重表主要用于存储无向图,其存储结构与邻接表类似,也有顶点表和边表组成,每条边用一个边表结点表示,其顶点表和边表的结点结构如下:

对于顶点表而言,data 为数据域,存放顶点信息;firstEdge 为边表头指针,指向依附于该顶点的第一条边的边表结点。
对于边表而言,iPos、jPos 为与某边依附的两顶点在顶点表中的下标;iLink 为指针域,指向依附于顶点 iPos 的下一条边;jLink 为指针域,指向依附于顶点 jPos 的下一条边


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程使用 AI 从 0 到 1 写了个小工具
· 快收藏!一个技巧从此不再搞混缓存穿透和缓存击穿
· AI 插件第二弹,更强更好用
· Blazor Hybrid适配到HarmonyOS系统
· 支付宝 IoT 设备入门宝典(下)设备经营篇