



【大数据应用技术】作业八|爬虫综合大作业(下)
本次所以的要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
前言
本次作业是爬取拉勾网python相关岗位的信息,通过爬取岗位id、城市、公司全名、福利待遇、工作地点、学历要求、工作类型、发布时间、职位名称、薪资、工作年限等数据并对其进行数据分析从而得出相应结论。
网页爬虫
1.代理IP
在爬取数据之前我们可以考虑使用代理ip进行爬取,所以这里我写了一段代码检测ip的有效性,这里我使用的是西刺免费代理ip进行测试。不过在测试中我发现可用的免费代理ip少之又少,并且时效性较短,用起来不太方便,所以如果有专门的爬虫需求的人可以考虑使用付费ip。
测试代理ip时效性代码如下:
import requests import random proxies = {'http': ''} def loadip(): url='https: // proxy.horocn.com / api / proxies?order_id = 3JXK1633928414619951 & num = 20 & format = text & line_separator = win & can_repeat = yes' req=requests.get(url) date=req.json() ipdate2=date['msg'] global ipdate ipdate.extend(ipdate2) print(ipdate) def getproxies(): b=random.choice(ipdate) d = '%s:%s' % (b['ip'], b['port']) global proxies proxies['http']=d global msg msg=b loadip() getproxies() print(proxies)
2.拉勾网python相关岗位爬虫
测试完代理IP之后,我们就可以开始正式对拉勾网python相关岗位的信息进行爬虫了。拉勾网python相关岗位网页爬虫代码如下所示:
(注意:在下面的 ip_list 中的代理IP到现在为止应该已经失效了,所以如果还要使用代理IP的话需要重新找新的代理IP)
1 # encoding: utf-8 2 import json 3 import requests 4 import xlwt 5 import time 6 import random 7 8 def GetUserAgent(): 9 ''' 10 功能:随机获取HTTP_User_Agent 11 ''' 12 user_agents=[ 13 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", 14 "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)", 15 "Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", 16 "Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)", 17 "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", 18 "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", 19 "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", 20 "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", 21 "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", 22 "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", 23 "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", 24 "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5", 25 "Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6", 26 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11", 27 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20", 28 "Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52", 29 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11", 30 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER", 31 "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)", 32 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)", 33 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER", 34 "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)", 35 "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)", 36 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)", 37 "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)", 38 "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)", 39 "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)", 40 "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1", 41 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1", 42 "Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5", 43 "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre", 44 "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0", 45 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11", 46 "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10" 47 ] 48 user_agent = random.choice(user_agents) 49 return user_agent 50 51 # 获取存储职位信息的json对象,遍历获得公司名、福利待遇、工作地点、学历要求、工作类型、发布时间、职位名称、薪资、工作年限 52 def get_json(url, datas): 53 user_agent = GetUserAgent() 54 ip_list = [ 55 {"http":"http://138.255.165.86:40600"}, 56 {"http":"http://195.122.185.95:3128"}, 57 {"http":"http://185.203.18.188:3128"}, 58 {"http":"http://103.55.88.52:8080"} 59 ] 60 proxies=random.choice(ip_list) 61 my_headers = { 62 "User-Agent": user_agent, 63 "Referer": "https://www.lagou.com/jobs/list_Python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=", 64 "Content-Type": "application/x-www-form-urlencoded;charset = UTF-8" 65 } 66 time.sleep(5) 67 ses = requests.session() # 获取session 68 ses.headers.update(my_headers) # 更新 69 ses.proxies.update(proxies) 70 71 cookie_dict = dict() 72 ses.cookies.update(cookie_dict) 73 74 ses.get( 75 "https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=",headers=my_headers) 76 time.sleep(5) 77 content = ses.post(url=url, data=datas) 78 result = content.json() 79 info = result['content']['positionResult']['result'] 80 info_list = [] 81 for job in info: 82 information = [] 83 information.append(job['positionId']) # 岗位对应ID 84 information.append(job['city']) # 岗位对应城市 85 information.append(job['companyFullName']) # 公司全名 86 information.append(job['companyLabelList']) # 福利待遇 87 information.append(job['district']) # 工作地点 88 information.append(job['education']) # 学历要求 89 information.append(job['firstType']) # 工作类型 90 information.append(job['formatCreateTime']) # 发布时间 91 information.append(job['positionName']) # 职位名称 92 information.append(job['salary']) # 薪资 93 information.append(job['workYear']) # 工作年限 94 info_list.append(information) 95 # 将列表对象进行json格式的编码转换,其中indent参数设置缩进值为2 96 # print(json.dumps(info_list, ensure_ascii=False, indent=2)) 97 # print(info_list) 98 return info_list 99 100 101 def main(): 102 page = int(input('请输入你要抓取的页码总数:')) 103 # kd = input('请输入你要抓取的职位关键字:') 104 # city = input('请输入你要抓取的城市:') 105 106 info_result = [] 107 title = ['岗位id', '城市', '公司全名', '福利待遇', '工作地点', '学历要求', '工作类型', '发布时间', '职位名称', '薪资', '工作年限'] 108 info_result.append(title) 109 for x in range(56, page + 1): 110 url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false' 111 # 请求参数,pn参数是页数,kd参数是职位关键字 112 datas = { 113 'first': 'false', 114 'pn': x, 115 'kd': 'python', 116 } 117 try: 118 info = get_json(url, datas) 119 info_result = info_result + info 120 print("第%s页正常采集" % x) 121 except Exception as msg: 122 print("第%s页出现问题" % x) 123 124 # 创建workbook,即excel 125 workbook = xlwt.Workbook(encoding='utf-8') 126 # 创建表,第二参数用于确认同一个cell单元是否可以重设值 127 worksheet = workbook.add_sheet('lagoupy', cell_overwrite_ok=True) 128 for i, row in enumerate(info_result): 129 # print(row) 130 for j, col in enumerate(row): 131 # print(col) 132 worksheet.write(i, j, col) 133 workbook.save('lagoupy.xls') 134 135 136 if __name__ == '__main__': 137 main()
数据分析
在执行完上述爬虫代码之后,我们可以得到一个lagoupy.xls的文件,里面存储的是我们爬虫的结果,总共爬取了2640条数据,如下图所示。

1.数据预处理
由于我们爬取下来的数据并不是全部都是我们所要的,或者是有一些数据需要进行加工才可以用到,这时候数据的预处理就必不可少了。
① 删除重复值
如果数据中存在重复记录, 而且重复数量较多时, 势必会对结果造成影响, 因此我们应当首先处理重复值。打开lagoupy.xls文件,选中岗位id这一列数据,选择数据——>删除重复值,对重复值进行删除,删除重复值后,我们可以发现,数据从原来的2641条变成2545条。
② 过滤无效数据
由于某些数据对我们的数据分析并无用处,所以对于这一部分数据我们可以不要,在这里发布时间是无效数据,所以我们可以直接删除这一列。
③ 加工数据
由于爬取下来的数据中薪资这一列是类似于15k-30k这样的数据,并且这样的数据不能满足我们的分析需求, 因此需要对薪资这一列数据进行分列操作,把薪资这一列分裂成最低工资和最高工资,接着我们可以利用最低工资和最高工资计算出平均工资,并把平均工资作为新的一列添加进数据表中。
经过上述三个步骤后,我们最终可以得到一个经过数据预处理之后的lagoupy.xls文件,经过预处理之后我们的数据条数也从原来的2640条变成了2544条,如下图所示。

2.数据分析
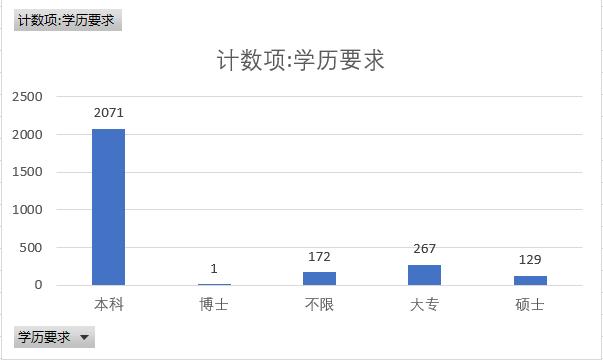
① 学历要求
根据所统计的数据来看,python对学历要求以本科和大专居多,其中本科以2071名列第一 。
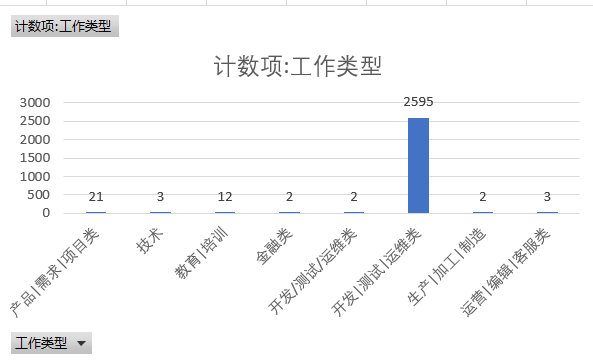
② 工作类型
我们把python相关的工作大体分为八类,分别是产品|需求|项目类、技术类、教育|培训类、金融类、开发|测试|运维类、生产|加工|制造类、运营|编辑|客服类,其中以开发|测试|运维类这一类工作类型的人才需求多,占绝对优势。
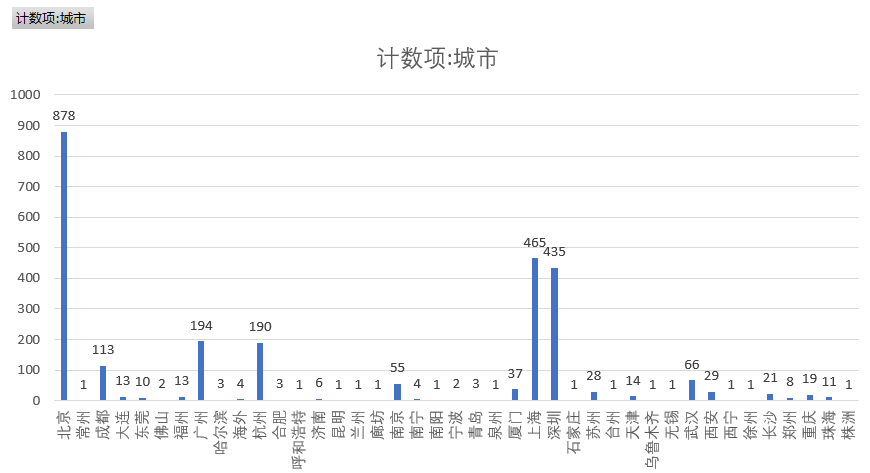
③ 工作城市
统计各个城市对python相关岗位的需求情况,由下图我们不难发现,北京、上海、深圳、广州、杭州、成都这六个城市对python这一相关行业的需求比较大。
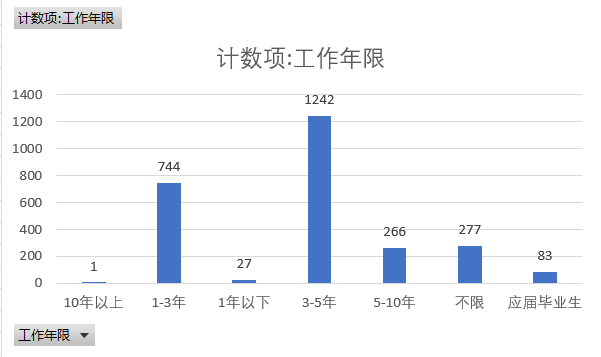
④ 工作年限
对python相关岗位的工作年限进行统计,我们可以发现企业对于python的工作经验要求以3-5年、1-3年这两种工作年限需求居多。
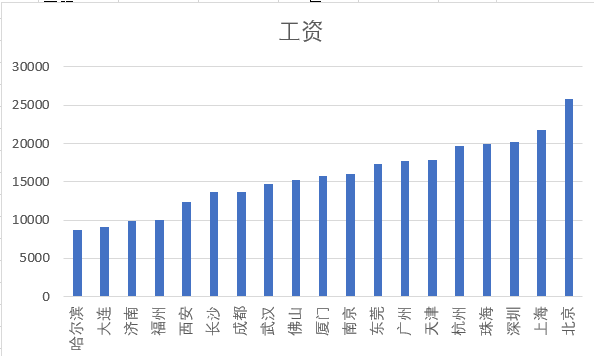
⑤ 城市与工资——较发达的城市工资水平较高
由下图可知,城市与工资有一定的关系,在北上广深等发达的城市里,python相关职位的工资较高。
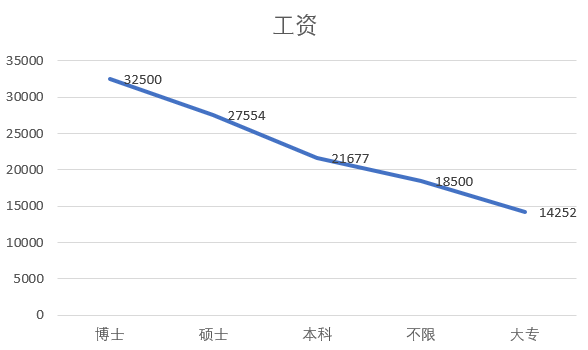
⑥ 学历与工资——学历越高工资越高
由图可知,整体上看学历越高工资越高。由于博士学历只有一条数据,所以这里可能因为数据不足的原因导致分析结果有所误差。
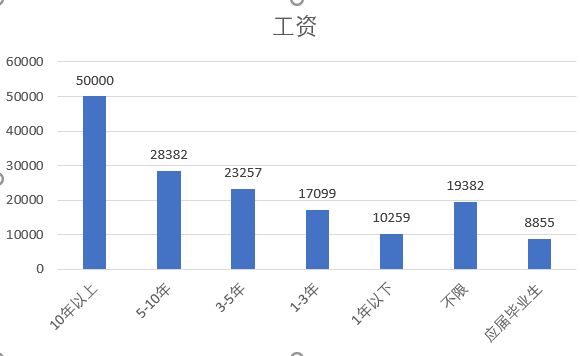
⑦ 工作年限与工资——工作年限越长工资越高
由图可知,工作年限越长,工资越高。其中因为10年以上只有一条数据,所以对于10年以上的工作经验所统计出来的数据可能有所偏差。
⑧ 福利待遇
首先,我们新建一个fuli.txt的文件,把福利待遇这一列粘贴到fuli.txt中并保存,如下图所示。
其次,我们对fuli.txt进行词频统计,把词频统计生成的结果存为fuli.csv文件。福利待遇词频统计代码如下所示:
1 # -*- coding: utf-8 -*- 2 import jieba # 加载停用表 3 import pandas as pd 4 from wordcloud import WordCloud 5 import matplotlib.pyplot as plt 6 7 # 分解 8 article = open("fuli.txt", "r", encoding='utf-8').read() 9 jieba.add_word('五险一金') 10 jieba.add_word('七险一金') 11 jieba.add_word('六险一金') 12 jieba.add_word('带薪年假') 13 jieba.add_word('美女多') 14 jieba.add_word('帅哥多') 15 jieba.add_word('年底双薪') 16 jieba.add_word('绩效奖金') 17 jieba.add_word('股票期权') 18 jieba.add_word('扁平管理') 19 jieba.add_word('弹性工作') 20 jieba.add_word('管理规范') 21 jieba.add_word('岗位晋升') 22 jieba.add_word('技能培训') 23 jieba.add_word('节日礼物') 24 jieba.add_word('带薪年假') 25 jieba.add_word('定期体检') 26 jieba.add_word('通讯津贴') 27 jieba.add_word('领导好') 28 jieba.add_word('年度旅游') 29 jieba.add_word('交通补助') 30 jieba.add_word('年终分红') 31 jieba.add_word('丰盛三餐') 32 jieba.add_word('发展空间大') 33 jieba.add_word('午餐补助') 34 jieba.add_word('快速发展') 35 jieba.add_word('发展前景好') 36 jieba.add_word('专项奖金') 37 jieba.add_word('免费班车') 38 jieba.add_word('丰盛三餐') 39 jieba.add_word('科技大牛') 40 words = jieba.cut(article, cut_all=False) # 统计词频 41 stayed_line = {} 42 for word in words: 43 if len(word) == 1: 44 continue 45 else: 46 stayed_line[word] = stayed_line.get(word, 0) + 1 47 48 print(stayed_line) # 排序 49 xu = list(stayed_line.items()) 50 # print(xu) 51 52 #存到csv文件中 53 pd.DataFrame(data=xu).to_csv("fuli.csv",encoding="utf_8_sig")
执行完上述代码后,我们可以生成一个fuli.csv文件,如下图所示。
根据所生成fuli.csv文件使用WordArt对福利待遇生成中文词云,结果如下图所示,我们可以发现python相关岗位的福利待遇中,被提及最多的词汇分别是带薪年假、股票期权、绩效奖金、年底双薪、节日礼物、技能培训、定期体检、五险一金等。


