


linux使用进阶(一)
本文依据《应该知道的Linux技巧》coolshell上的一篇文章提到的Linux技巧,结合自己掌握的情况进行扩展和总结得来。主要包含下面内容:
![]()
![]()

![]()
![]()

![]()
![]()
![]()
![]()
![]()
一、日常操作
二、数据处理
三、系统调试
四、网络管理
一、日常操作
日常操作是在使用Linux进行编程开发中经常使用的命令,工具的总结。
1、ssh
2、熟悉bash中的作业管理
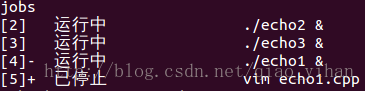
& 命令后面加“&”表示后台执行
$jobs 查看后台执行的程序(包含停止的和正在执行的)
$fg %n 让后台执行的工作n到前台执行
$bg %n 让工作n在后台执行
当中n代表工作号
Ctrl+z、Ctrl+c、Ctrl+\的差别:
Ctrl+z:发送SIGTSTP信号,挂起前台全部进程;
Ctrl+c:发送SIGINT信号,结束前台全部进程;
Ctrl+d:结束输入或退出shell,相当于EOF;
Ctrl+\:发送SIGQUIT信号,结束前台进程,并声称core文件。
TIP:能够在vi编辑过程中,按Ctrl+z挂起vi编辑,查看文件后(或做其它事),用fg让vi到前台执行。
kill在bash工作控制中的使用:
kill -l l位L的小写,列出kill可使用的信号
kill -2 相当于Ctrl+c
kill -9 强制结束一个进程
kill -15 以正常方式结束掉一个进程
(-9和-15的差别,比如正在编辑的vi,假设以正常方式结束,那么会删除.filename.swap文件,假设是强制结束不会删除掉.filename.swap文件。)
另:kill后面默认跟进程的PID,用在bash工作控制时,要跟%n(n为工作编号)。
3、文件管理
ls, ls -l, less, more, tail, head, ln, ln -s, chgrp, chown, chmod, du, df, fdisk, mkfs, mount, umount, find
- head
head filename
显示前面几行,默认显示前10行。
head -n 20 filename
用-n指定显示前多少行。
- tail
tail filename
默认显示后10行。
tail -n 20 filename
用-n指定显示后多少行。
tail -f filename
一直侦測filename的内容,直到Ctrl+c为止,filename一有内容就会输出。
- ln
ln [-sf] 来源文件 目标文件
假设不加不论什么參数,就是硬链接(hard link),假设加-s就是符号链接(symbolic link)。
-f 假设目标文件存在就直接把目标文件删除后再建立。
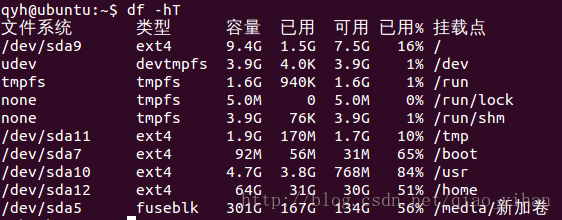
- df
列出文件系统磁盘的总体使用量。
-a:列出全部的文件系统,包含系统特有的/proc等文件系统;
-k(-m):以KByte(MByte)的容量显示各文件系统;
-h:以人们易阅读的GByte,MByte,KByte等格式自行显示;
-H:以 M=1000K代替M=1024K 的进位方式;
-T:连同该 partition的filesystem 名称 (比如 ext3) 也列出;
-i:不用硬盘容量,而以 inode的数量来显示。
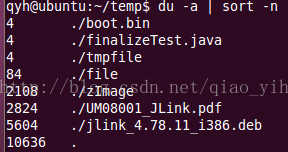
- du
du [-ahskm] 档案或文件夹名称
选项參数:
-a:列出全部档案的容量,由于默认仅统计文件夹底下的档案量而已;
-h:以人们较易读的容量格式 (G/M) 显示;
-s:列出总量而已,而不列出每一个各别的文件夹占用容量;
-S:不包含子文件夹下的总计,与-s有点区别;
-k:以 KBytes 列出容量显示;
-m:以 MBytes 列出容量显示;
- chgrp
chgrp [-R] dirname/filename ...
-R:递归的意思,文件夹下的全部档案和子文件夹都改为这个群组。
chgrp qyh filename
要改变为的群组必须在/etc/group中存在。
- chown
# chown [-R] 账号名称 档案或文件夹
# chown [-R] 账号名称:组名 档案或文件夹
- fdisk
先了解一下磁盘的一些知识(主要分三类):
ATA(Advanced Technology Attachment),高技术配置(IDE并行接口),40pin,线多,干扰大,如今已基本不用;
SATA,串行ATA,SATA3.0可达到6Gbit/s;
SCSI(Small Computer System Interface),小型计算机系统接口;
在Linux中,第一个软盘驱动叫/dev/fd0,第二个叫/dev/fd1;第一个SCSI硬盘叫/dev/sda,第二个叫/dev/sdb;第一个SCSI CD-ROM叫/dev/scd0或者/dev/sr0;在IDE控制器上的主硬盘叫/dev/hda,在IDE控制器上的从硬盘叫/dev/hdb。
在每一个磁盘上的分区,用数字来区分,比方在一个SCSI磁盘上的两个分区命名为/dev/sda1和/dev/sda2。
fdisk -l 装置名称 (磁盘分区)
fdisk -l 列出全部分区信息
sudo fdisk /dev/sda
- mkfs
mkfs [-t 文件系统格式] 装置文件名称
把指定的分区格式化为指定的文件系统格式。
mkfs[tab][tab] (按两个tab键会出现支持的文件系统格式)
格式化磁盘能够使用支持具体參数的mke2fs指令。
另外还有两个磁盘检验的命令fsck, badblocks 。
- mount
# mount [-t 文件系统] [-L Label 名] [-o 额外选项] [-n] 装置文件名称 挂载点
单一文件系统不应该被反复挂载在不同的挂载点(文件夹)中;
单一文件夹不应该反复挂载多个文件系统;
要作为挂载点的文件夹,理论上应该都是空文件夹才是。
选项与參数:
-a :按照配置文件 /etc/fstab 的数据将全部未挂载的磁盘都挂载上来
-l :单纯的输入 mount 会显示眼下挂载的信息。加上 -l 可增列 Label 名称!
-t :与 mkfs 的选项很类似的,能够加上文件系统种类来指定欲挂载的类型。
常见的 Linux 支持类型有:ext2, ext3, vfat, reiserfs, iso9660(光盘格式),
nfs, cifs, smbfs(此三种为网络文件系统类型)
-n :在默认的情况下,系统会将实际挂载的情况实时写入 /etc/mtab 中,以利其它程序
的执行。但在某些情况下(比如单人维护模式)为了避免问题,会刻意不写入。
此时就得要使用这个 -n 的选项了。
-L :系统除了利用装置文件名称 (比如 /dev/hdc6) 之外,还能够利用文件系统的标头名称
(Label)来进行挂载。最好为你的文件系统取一个独一无二的名称吧!
-o :后面能够接一些挂载时额外加上的參数!例如说账号、password、读写权限等:
ro, rw: 挂载文件系统成为仅仅读(ro) 或可擦写(rw)
async, sync: 此文件系统是否使用同步写入 (sync) 或异步 (async) 的
内存机制,请參考文件系统执行方式。默觉得 async。
auto, noauto: 同意此 partition 被以 mount -a 自己主动挂载(auto)
dev, nodev: 是否同意此 partition 上,可创建装置文件? dev 为可同意
suid, nosuid: 是否同意此 partition 含有 suid/sgid 的文件格式?
exec, noexec: 是否同意此 partition 上拥有可执行 binary 文件?
user, nouser: 是否同意此 partition 让不论什么使用者执行 mount ?一般来说,
mount 仅有 root 能够进行,但下达 user 參数,则可让
一般 user 也可以对此 partition 进行 mount 。
defaults: 默认值为:rw, suid, dev, exec, auto, nouser, and async
remount: 又一次挂载,这在系统出错,或又一次升级參数时,非常实用!
mount /dev/sda5/ ./mnt/E (双系统,在Linux下挂载windows的文件系统)
挂载/dev/sda5到./mnt/E,能够省去參数,linux能够自己主动识别。
- umount
# umount [-fn] 装置文件名称或挂载点
选项与參数:
-f :强制卸除!可用在类似网络文件系统 (NFS) 无法读取到的情况下;
-n :不升级 /etc/mtab 情况下卸除。
另外,我们也能够利用 mount 来将某个文件夹挂载到另外一个文件夹去喔!这并非挂载文件系统,而是额外挂载某个文件夹的方法! 尽管底下的方法也能够使用 symbolic link 来连结,只是在某些不支持符号链接的程序执行中,还是得要透过这个方案才行。
$ sudo mount --bind /home/qyh/work ~/mnt/w
$ umount ~/mnt/w
4、Some Tips
a)在bash里,Ctrl-R能够查找历史命令,Ctrl-P和Ctrl-N分别用来调出上一条命令和下一条命令。
Ctrl-W用来删除最后一个单词,Ctrl-U用来删除一句。
Alt-.把上一次命令的最后一个參数打出来,Alt-*列出你能够输出的命令。
cd - 回到上一次工作文件夹;cd ~ 回到/home/usr文件夹。
假设你有输了个命令行,可是你改变注意了,但你又不想删除它,由于你要在历史命令中找到它,但你也不想运行它。那么,你可
以按下 Alt-# ,于是这个命令关就被加了一个#字符,于是就被凝视掉了。
b)pstree -p能够查看进程树。
c)sudo !!以root来运行上次命令,在忘记打上sudo的时候这条命令比較实用。
d)man ascii 查看ASCII表。
e)> file创建一个空文件。
f)echo “ls -l” | at midnight 在某个时间执行某个命令。
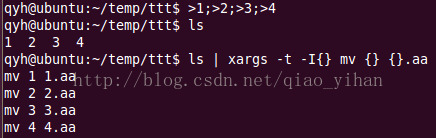
g)xargs的使用方法:
它的作用是将參数列表转换成小块分段传递给其它命令,以避免參数列表过长的问题。
$ find /tmp -name core -type f -print | xargs /bin/rm -f
查找/tmp下的core文件并删除它,可是假设文件名称包括空格或换行符就会运行错误。
$ find /tmp -name core -type f -print0 | xargs -0 /bin/rm -f
-print0表示输出以null分隔,-0表示输入以null分隔
$ find /tmp -depth -name core -type f -delete
比前面的样例更有效率,由于不须要使用fork和exec去运行rm了
$ cut -d: -f1 < /etc/passwd | sort | xargs echo
输出所用实用户
-t:先打印出命令再运行;
-I{}:用“{}”取代输入參数,运行时”{}“会变成输入參数,“{}”也可用其它字符串取代
比方ls | xargs -t -Ixx mv xx xx.aa和上面的效果一样。
二、数据管理
sort, uniq, cut, paste, join, tr, strings, iconv, split
命令的使用及參数见本文档组下的《linux经常使用命令总结》。以下介绍一些实例。
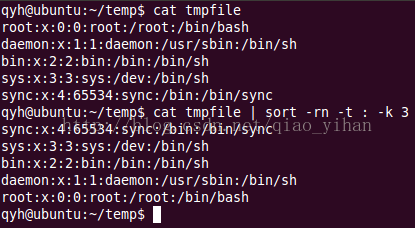
- sort
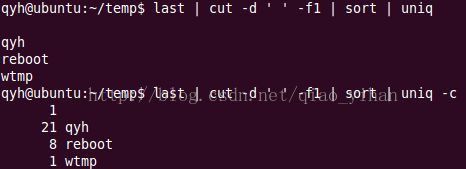
- uniq
注:last命令式列出账号登陆信息。
- tr
# tr [-ds] SET1 ...
选项与參数:
-d :删除讯息其中的 SET1 这个字符串;
-s :代替掉反复的字符!
将last输出的信息其中的小写字母转换成大写字母:
$ last | tr '[a-z]' '[A-Z]'
删除last输出的信息中的冒号“:”
$ last | tr -d ':'
- join
# join [-ti12] file1 file2
选项与參数:
-t :join 默认以空格符分隔数据,而且比对『第一个字段』的数据,
假设两个档案同样,则将两笔数据联成一行,且第一个字段放在第一个!
-i :忽略大写和小写的差异;
-1 :这个是数字的 1 ,代表『第一个档案要用那个字段来分析』的意思;
-2 :代表『第二个档案要用那个字段来分析』的意思。
实例:
qyh@ubuntu:~/temp$ cat tmpfile
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/bin/sh
bin:x:2:2:bin:/bin:/bin/sh
sys:x:3:3:sys:/dev:/bin/sh
sync:x:4:65534:sync:/bin:/bin/sync
qyh@ubuntu:~/temp$ cut -d : -f 1-4 tmpfile > tmpfile_1
qyh@ubuntu:~/temp$ cut -d : -f 5- tmpfile > tmpfile_2
qyh@ubuntu:~/temp$ cat tmpfile_1 tmpfile_2
root:x:0:0
daemon:x:1:1
bin:x:2:2
sys:x:3:3
sync:x:4:65534
root:/root:/bin/bash
daemon:/usr/sbin:/bin/sh
bin:/bin:/bin/sh
sys:/dev:/bin/sh
sync:/bin:/bin/sync
qyh@ubuntu:~/temp$ join -t : tmpfile_1 tmpfile_2
root:x:0:0:/root:/bin/bash
daemon:x:1:1:/usr/sbin:/bin/sh
bin:x:2:2:/bin:/bin/sh
sys:x:3:3:/dev:/bin/sh
sync:x:4:65534:/bin:/bin/sync
qyh@ubuntu:~/temp$ join -t : -1 1 tmpfile_1 -2 1 tmpfile_2
root:x:0:0:/root:/bin/bash
daemon:x:1:1:/usr/sbin:/bin/sh
bin:x:2:2:/bin:/bin/sh
sys:x:3:3:/dev:/bin/sh
sync:x:4:65534:/bin:/bin/sync
- paste
# paste [-d] file1 file2
选项与參数:
-d :后面能够接分隔字符。预设是以 [tab] 来分隔的!
- :假设 file 部分写成 - ,表示来自 standard input 的资料的意思。
注:paste与join不同之处在于,paste不须要考虑字段的相关性,直接将两行贴在一起,中间以tab键分隔。
qyh@ubuntu:~/temp$ paste tmpfile_1 tmpfile_2
root:x:0:0 root:/root:/bin/bash
daemon:x:1:1 daemon:/usr/sbin:/bin/sh
bin:x:2:2 bin:/bin:/bin/sh
sys:x:3:3 sys:/dev:/bin/sh
sync:x:4:65534 sync:/bin:/bin/sync
cat a b | sort | uniq > c # c is a union b 并集
cat a b | sort | uniq -d > c # c is a intersect b 交集
cat a b b | sort | uniq -u > c # c is set difference a - b 差集
注:uniq -d 只打印反复的行 uniq -u 只打印唯一的行
- strings
Usage: strings [option(s)] [file(s)]
Display printable strings in [file(s)] (stdin by default)
The options are:
-a - --all Scan the entire file, not just the data section
-f --print-file-name Print the name of the file before each string
-n --bytes=[number] Locate & print any NUL-terminated sequence of at
-<number> least [number] characters (default 4).
-t --radix={o,d,x} Print the location of the string in base 8, 10 or 16
-o An alias for --radix=o
-T --target=<BFDNAME> Specify the binary file format
-e --encoding={s,S,b,l,B,L} Select character size and endianness:
s = 7-bit, S = 8-bit, {b,l} = 16-bit, {B,L} = 32-bit
- iconv
# iconv --list
# iconv -f 原本编码 -t 新编码 filename [-o newfile]
选项与參数:
--list :列出 iconv 支持的语系数据
-f :from ,亦即来源之意,后接原本的编码格式;
-t :to ,亦即后来的新编码要是什么格式;
-o file:假设要保留原本的档案,那么使用 -o 新档名,能够建立新编码档案。
- split
# split [-bl] file PREFIX
选项与參数:
-b :后面可接欲切割成的档案大小,可加单位,比如 b, k, m 等;
-l :以行数来进行切割。
PREFIX :代表前导符的意思,可作为切割档案的前导文字。
qyh@ubuntu:~/temp$ ls -lh file
-rw-r--r-- 1 qyh qyh 84K 2014-04-15 18:02 file
qyh@ubuntu:~/temp$ split -b 30K file File
qyh@ubuntu:~/temp$ ls -lh File*
-rw-r--r-- 1 qyh qyh 30K 2014-04-24 18:58 Fileaa
-rw-r--r-- 1 qyh qyh 30K 2014-04-24 18:58 Fileab
-rw-r--r-- 1 qyh qyh 24K 2014-04-24 18:58 Fileac

