
1、添加索引
2、避免select * (在解析的过程中,会将*依次转换成所有的列名。查到多余的数据)
3、order by 语句优化 (添加索引)
4、GROUP BY语句优化(将不需要的记录在GROUP BY 之前过滤掉)
5、使用 varchar/nvarchar 代替 char/nchar
7、能用DISTINCT的就不用GROUP BY
9、在Join表的时候使用相当类型的例,并将其索引
常用优化总结
优化语句很多,需要注意的也很多,针对平时的情况总结一下几点:
1、有索引但未被用到的情况(不建议)
(1) Like的参数以通配符开头时
尽量避免Like的参数以通配符开头,否则数据库引擎会放弃使用索引而进行全表扫描。
以通配符开头的sql语句,例如:select * from t_credit_detail where Flistid like '%0'\G
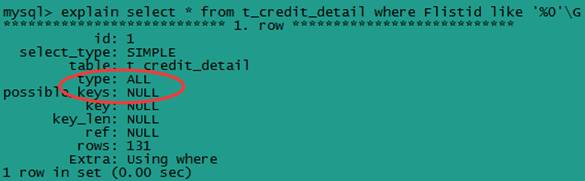
这是全表扫描,没有使用到索引,不建议使用。
不以通配符开头的sql语句,例如:select * from t_credit_detail where Flistid like '2%'\G
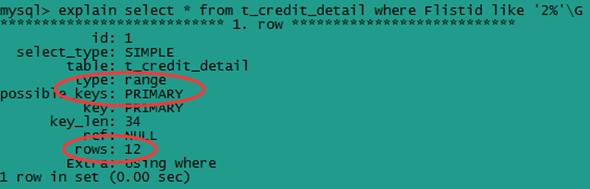
很明显,这使用到了索引,是有范围的查找了,比以通配符开头的sql语句效率提高不少。
(2) where条件不符合最左前缀原则时
例子已在最左前缀匹配原则的内容中有举例。
(3) 使用!= 或 <> 操作符时
尽量避免使用!= 或 <>操作符,否则数据库引擎会放弃使用索引而进行全表扫描。使用>或<会比较高效。
select * from t_credit_detail where Flistid != '2000000608201108010831508721'\G
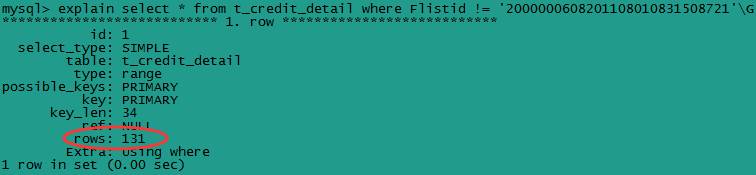
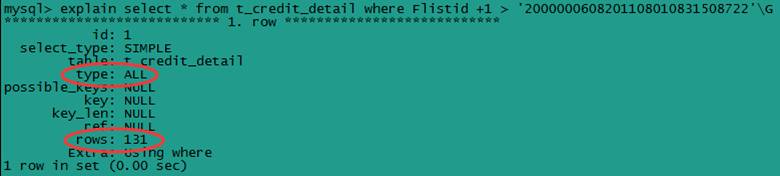
(4) 索引列参与计算
应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。
select * from t_credit_detail where Flistid +1 > '2000000608201108010831508722'\G
(5) 对字段进行null值判断
应尽量避免在where子句中对字段进行null值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: 低效:select * from t_credit_detail where Flistid is null ;
可以在Flistid上设置默认值0,确保表中Flistid列没有null值,然后这样查询: 高效:select * from t_credit_detail where Flistid =0;
(6) 使用or来连接条件
应尽量避免在where子句中使用or来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如: 低效:select * from t_credit_detail where Flistid = '2000000608201108010831508721' or Flistid = '10000200001';
可以用下面这样的查询代替上面的 or 查询: 高效:select from t_credit_detail where Flistid = '2000000608201108010831508721' union all select from t_credit_detail where Flistid = '10000200001';

2、避免select *
在解析的过程中,会将'*' 依次转换成所有的列名,这个工作是通过查询数据字典完成的,这意味着将耗费更多的时间。
所以,应该养成一个需要什么就取什么的好习惯。
3、order by 语句优化
任何在Order by语句的非索引项或者有计算表达式都将降低查询速度。
方法:1.重写order by语句以使用索引;
2.为所使用的列建立另外一个索引
3.绝对避免在order by子句中使用表达式。
4、GROUP BY语句优化
提高GROUP BY 语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉
低效:
SELECT JOB , AVG(SAL)
FROM EMP
GROUP by JOB
HAVING JOB = ‘PRESIDENT'
OR JOB = ‘MANAGER'
高效:
SELECT JOB , AVG(SAL)
FROM EMP
WHERE JOB = ‘PRESIDENT'
OR JOB = ‘MANAGER'
GROUP by JOB
5、用 exists 代替 in
很多时候用 exists 代替 in 是一个好的选择: select num from a where num in(select num from b) 用下面的语句替换: select num from a where exists(select 1 from b where num=a.num)
6、使用 varchar/nvarchar 代替 char/nchar
尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
7、能用DISTINCT的就不用GROUP BY
SELECT OrderID FROM Details WHERE UnitPrice > 10 GROUP BY OrderID
可改为:
SELECT DISTINCT OrderID FROM Details WHERE UnitPrice > 10
8、能用UNION ALL就不要用UNION
UNION ALL不执行SELECT DISTINCT函数,这样就会减少很多不必要的资源。
9、在Join表的时候使用相当类型的例,并将其索引
如果应用程序有很多JOIN 查询,你应该确认两个表中Join的字段是被建过索引的。这样,MySQL内部会启动为你优化Join的SQL语句的机制。
而且,这些被用来Join的字段,应该是相同的类型的。例如:如果你要把 DECIMAL 字段和一个 INT 字段Join在一起,MySQL就无法使用它们的索引。对于那些STRING类型,还需要有相同的字符集才行。(两个表的字符集有可能不一样)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现