
(1) 最左前缀匹配原则
(2) 尽量选择区分度高的列作为索引。
(3) =和in可以乱序
(4) 索引列不能参与计算
(5) 尽量的扩展索引,不要新建索引。
建索引的几大原则
(1) 最左前缀匹配原则
对于多列索引,总是从索引的最前面字段开始,接着往后,中间不能跳过。比如创建了多列索引(name,age,sex),会先匹配name字段,再匹配age字段,再匹配sex字段的,中间不能跳过。mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配。
一般,在创建多列索引时,where子句中使用最频繁的一列放在最左边。
看一个补符合最左前缀匹配原则和符合该原则的对比例子。
实例:表c2c_db.t_credit_detail建有索引(Flistid,Fbank_listid)
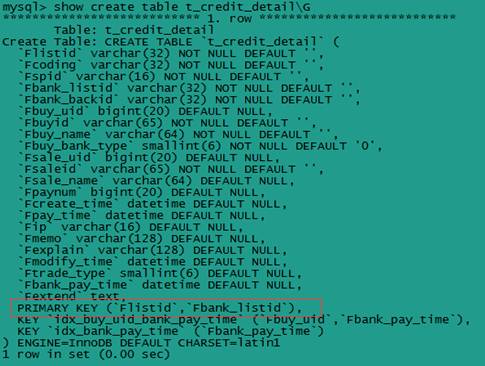
不符合最左前缀匹配原则的sql语句:
select * from t_credit_detail where Fbank_listid='201108010000199'\G
该sql直接用了第二个索引字段Fbank_listid,跳过了第一个索引字段Flistid,不符合最左前缀匹配原则。用explain命令查看sql语句的执行计划,如下图:
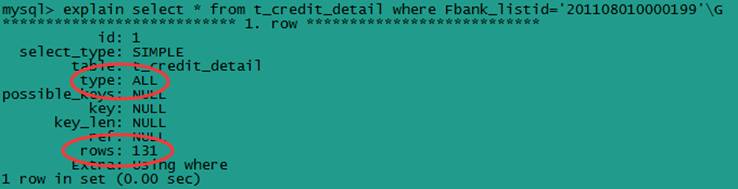
从上图可以看出,该sql未使用索引,是一个低效的全表扫描。
符合最左前缀匹配原则的sql语句:
select * from t_credit_detail where Flistid='2000000608201108010831508721' and Fbank_listid='201108010000199'\G
该sql先使用了索引的第一个字段Flistid,再使用索引的第二个字段Fbank_listid,中间没有跳过,符合最左前缀匹配原则。用explain命令查看sql语句的执行计划,如下图:

从上图可以看出,该sql使用了索引,仅扫描了一行。
对比可知,符合最左前缀匹配原则的sql语句比不符合该原则的sql语句效率有极大提高,从全表扫描上升到了常数扫描。
(2) 尽量选择区分度高的列作为索引。
比如,我们会选择学号做索引,而不会选择性别来做索引。
(3) =和in可以乱序
比如a = 1 and b = 2 and c = 3,建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
(4) 索引列不能参与计算,保持列“干净”
比如:Flistid+1>‘2000000608201108010831508721‘。原因很简单,假如索引列参与计算的话,那每次检索时,都会先将索引计算一次,再做比较,显然成本太大。
(5) 尽量的扩展索引,不要新建索引。
比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现