

hive的常用函数与连续登录问题
hive的查询语法(DQL)
全局排序
- order by 会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间
- 使用 order by子句排序 :ASC(ascend)升序(默认)| DESC(descend)降序
- order by放在select语句的结尾
局部排序
-
sort by 不是全局排序,其在数据进入reducer前完成排序。
-
如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by 只保证每个reducer的输出有序,不保证全局有序。asc,desc
-
设置reduce个数
set mapreduce.job.reduce=3; set mapred.reduce.tasks=3; -
查看reduce个数
set mapreduce.job.reduce; -
排序
select * from 表名 sort by 字段名[,字段名...];
分区排序
distribute by(字段)根据指定的字段将数据分到不同的reducer,且分发算法是hash散列。
类似MR中partition,进行分区,结合sort by使用。(注意:distribute by 要在sort by之前)
对于distrbute by 进行测试,一定要多分配reduce进行处理,否则无法看到distribute by的效果。
- 设置reduce个数
set mapreduce.job.reduce=7;
- 排序
select * from 表名 distribute by 字段名[,字段名...];
分区并排序
- cluster by(字段)除了具有Distribute by的功能外,还会对该字段进行排序
- cluster by = distribute by + sort by 只能默认升序,不能使用倒序
select * from 表名 sort cluster by 字段名[,字段名...];
select * from 表名 distribute by 字段名[,字段名...] sort by 字段名[,字段名...];
hive的内置函数
内置函数分类
关系操作符:包括 = 、 <> 、 <= 、>=等
算数操作符:包括 + 、 - 、 *、/等
逻辑操作符:包括AND 、 && 、 OR 、 || 等
复杂类型构造函数:包括map、struct、create_union等
复杂类型操作符:包括A[n]、Map[key]、S.x
数学操作符:包括ln(double a)、sqrt(double a)等
集合操作符:包括size(Array)、sort_array(Array)等
类型转换函数: binary(string|binary)、cast(expr as )
日期函数:包括from_unixtime(bigint unixtime[, string format])、unix_timestamp()等
条件函数:包括if(boolean testCondition, T valueTrue, T valueFalseOrNull)等
字符串函数:包括acat(string|binary A, string|binary B…)等
其他:xpath、get_json_objectscii(string str)、con
hive常用函数
关系运算
等值比较:= == <= =>
不等值比较:!= <>
区间比较:between and
空值、非空值判断:is null、is not null、nvl()、isnull()
模糊查询:like——A like B(%:任意字符、_表示占位符) rlike:A rlike B 表示B是否在A里面
regexp的用法和rlike一样
数值计算
取整函数(四舍五入):round
向上取整:ceil
向下取整:floor
条件函数
if:格式if(表达式,表达式成立的返回值,表达式不成立的返回值)
if可以嵌套使用
select score,if(score>120,'优秀',if(score>100,'良好',if(score>90,'及格','不及格'))) as pingfen from score limit 20;
coalesce
select COALESCE(null,'1','2'); // 1 从左往右 依次匹配 直到非空为止
select COALESCE('1',null,'2'); // 1
case when:
select score
,case when score>120 then '优秀'
when score>100 then '良好'
when score>90 then '及格'
else '不及格'
end as pingfen
from score limit 20;
日期函数
from_unixtime():转化时间戳到当前时区的时间格式
select from_unixtime(1610611142,'YYYY/MM/dd HH:mm:ss');
unix_timestamp:获取当前时间戳
unix_timestamp('2022-09-14 19:29:00');//日期字符串必须满足yyyy-MM-dd格式
current_timestamp:当前的时间字符串
to_date:日期时间转日期
select to_date('2022-09-14 19:29:00');
输出:2022-09-14
current_date:当前日期
date_sub:返回日期前n天的日期
date_add:返回日期后n天的日期
获取日期的年、月、日、小时、分钟、秒
year() month() day() hour() minute() second()
datediff:返回日期相减的天数
last_day:当月的最后一天日期
months_between:返回日期相减的月数
字符串函数
拼接函数:concat
concat_ws:指定分隔符拼接,并且会忽略NULL
select concat_ws('#','a','b','c',NULL);
substr/substring():字符串截取函数,从1开始计数
split():字符串分割函数,返回值是一个数组。数组的下标依旧从0开始
length():字符串长度函数
upper/ucase():字符串大写函数
lower/lcase():字符串小写函数
trim:去除字符串两边的空格
ltrim:去除字符串左边的空格
rtrim:去除字符串右边的空格
regexp_replace():将字符串A中的符合java正则表达式B的部分替换为C
get_json_object:json解析函数
select get_json_object('{"name":"zhangsan","age":18,"score":[{"course_name":"math","score":100},{"course_name":"english","score":60}]}',"$.score[1].score"); // 60
repeat():字符串复制函数,返回重复n次后的str字符串
窗口函数
普通的聚合函数每组(Group by)只返回一个值,而开窗函数则可为窗口中的每行都返回一个值。
简单理解,就是对查询的结果多出一列,这一列可以是聚合值,也可以是排序值。
开窗函数一般就是说的是over()函数,其窗口是由一个 OVER 子句 定义的多行记录
开窗函数一般分为两类,聚合开窗函数和排序开窗函数。
-- 聚合格式
select sum(字段名) over([partition by 字段名] [ order by 字段名]) as 别名,
max(字段名) over() as 别名
from 表名;
-- 排序窗口格式
select rank() over([partition by 字段名] [ order by 字段名]) as 别名 from 表名;
注意点:
- over()函数中的分区、排序、指定窗口范围可组合使用也可以不指定,根据不同的业务需求结合使用
- over()函数中如果不指定分区,窗口大小是针对查询产生的所有数据,如果指定了分区,窗口大小是针对每个分区的数据
聚合开窗函数
sum():求和
min():最小值
max():最大值
avg():平均值
count():计数
count(*):包括了所有的列,查询所有的行数,不会忽略列值为空,只有一列数据的时候使用最快
count(1):忽略了所有列,用1代表代码行,在统计结果的时候不会忽略列值为空
count(列名):只包括列名那一列,在统计结果的时候,会忽略列值为空
lag():获取前n行的数据**LAG(col,n,default_val)
lead():获取后n行的数据
rows必须跟在Order by 子句之后,对排序的结果进行限制,使用固定的行数来限制分区中的数据行数量。
current row:当前行
n preceding:前n行
n following:后n行
unbounded preceding:起点
unbounded following:终点
例子:-- 当前和后面所有的行
sum(score) over(partition by subject order by score rows between current row and unbounded following) as sum7
from t_fraction;
排序开窗函数
rank():排序相同时会重复,总数不会变
dense_rank():排序相同时会重复,总数会减少
row_number():会根据顺序计算
percent_rank():计算给定行的百分比排名。可以用来计算超过了百分之多少的人(当前行的rank值-1)/(分组内的总行数-1)
hive行转列
lateral view explode
例子:小虎 "150","170","180"
火火 "150","180","190"//name和weight
select name,col1 from testarray2 lateral view explode(weight) t1 as col1;
输出:小虎 150
小虎 170
小虎 180
火火 150
火火 180
火火 190
hive多列转行
collect_list()和collect_set():区别就是list里面可重复而set里面是去重的
例子:将上面的结果生成一张表testLieToLine
select name,collect_list(col1) from testLieToLine group by name;
// 结果
小虎 ["150","180","190"]
火火 ["150","170","180"]
综合案例——连续登录问题
数据:
id datestr amount
1,2019-02-08,6214.23
1,2019-02-08,6247.32
1,2019-02-09,85.63
1,2019-02-09,967.36
1,2019-02-10,85.69
1,2019-02-12,769.85
1,2019-02-13,943.86
1,2019-02-14,538.42
1,2019-02-15,369.76
1,2019-02-16,369.76
1,2019-02-18,795.15
1,2019-02-19,715.65
1,2019-02-21,537.71
2,2019-02-08,6214.23
2,2019-02-08,6247.32
2,2019-02-09,85.63
2,2019-02-09,967.36
2,2019-02-10,85.69
2,2019-02-12,769.85
2,2019-02-13,943.86
2,2019-02-14,943.18
2,2019-02-15,369.76
2,2019-02-18,795.15
2,2019-02-19,715.65
2,2019-02-21,537.71
3,2019-02-08,6214.23
3,2019-02-08,6247.32
3,2019-02-09,85.63
3,2019-02-09,967.36
3,2019-02-10,85.69
3,2019-02-12,769.85
3,2019-02-13,943.86
3,2019-02-14,276.81
3,2019-02-15,369.76
3,2019-02-16,369.76
3,2019-02-18,795.15
3,2019-02-19,715.65
3,2019-02-21,537.71
建表语句
create table deal_tb(
id string
,datestr string
,amount string
)row format delimited fields terminated by ',';
计算逻辑
- 先按用户和日期分组求和,使每个用户每天只有一条数据
select id,datestr,sum(amount) as sum_amount from deal_tb group by id,datestr
- 根据用户ID分组按日期排序,将日期和分组序号相减得到连续登陆的开始日期,如果开始日期相同说明连续登陆
- datediff(string end_date,string start_date); 等于0说明连续登录
- 统计用户连续交易的总额、连续登陆天数、连续登陆开始和结束时间、间隔天数
sql实现:
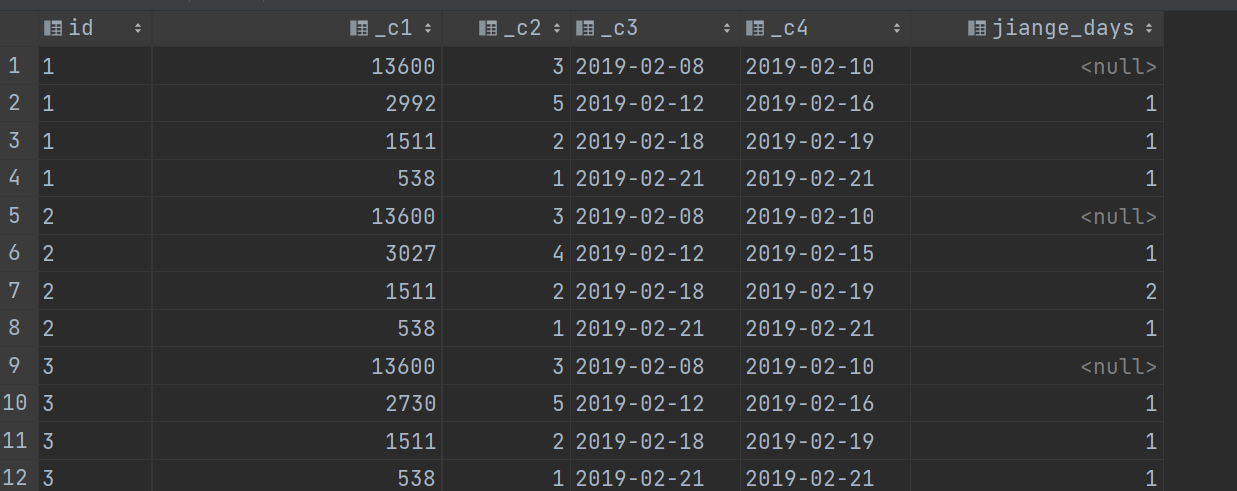
select t3.id,round(sum(sum_amount)),count(1),min(t3.datestr),max(t3.datestr),datediff(t3.new_date,lag(new_date,1) over (partition by t3.id order by t3.new_date)) as jiange_days
from(select t2.id,t2.datestr,t2.sum_amount,t2.rn ,date_sub(t2.datestr,t2.rn) as new_date from (select t1.id, t1.datestr,t1.sum_amount,
row_number() over (partition by t1.id order by t1.datestr) as rn
from (select id,datestr,sum(amount) as sum_amount from deal_tb group by id,datestr)t1)t2)t3 group by t3.id,t3.new_date;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!