

Hive的分区、分桶
Hive的分区、分桶
Hive分区
在大数据中,最常见的一种思想就是分治,我们可以把大的文件切割划分成一个个的小的文件,这样每次操作一个个小的文件就会很容易了,同样的道理,在hive当中也是支持这种思想的,就是我们可以把大的数据,按照每天或者每小时切分成一个个小的文件,这样去操作小的文件就会容易很多了。
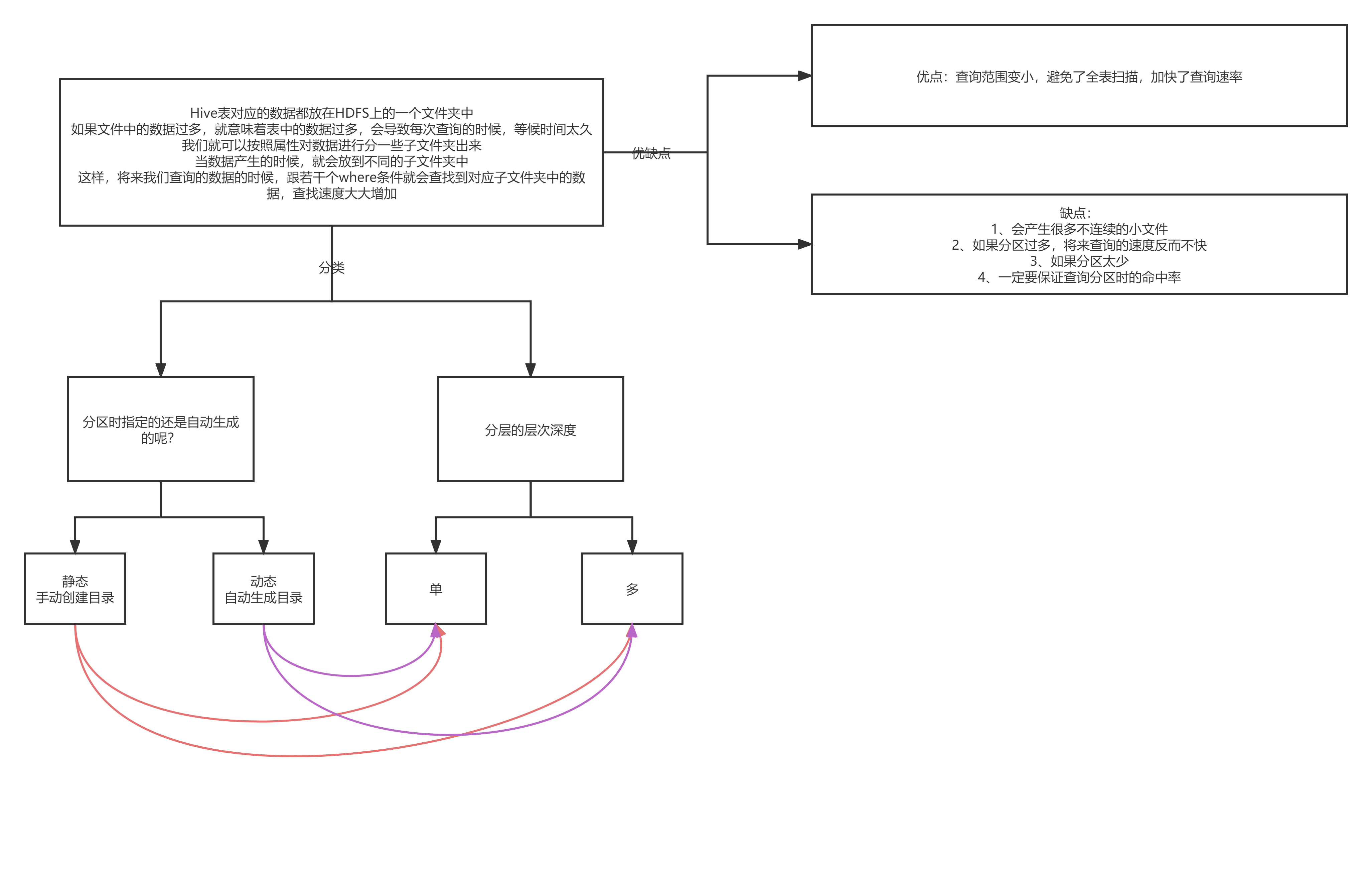
分区的优点:查询范围变小,避免全盘扫描,加快查询效率
缺点:会产生很多不连续的小文件、如果分区过多反而会降低查询效率
静态分区(SP)
借助于物理的文件夹分区,实现快速检索的目的。
一般对于查询比较频繁的列设置为分区列。
分区查询的时候直接把对应分区中所有数据放到对应的文件夹中。
创建单分区表
CREATE TABLE IF NOT EXISTS t_student (
sno int,
sname string
) partitioned by(grade int)
row format delimited fields terminated by ',';
-- 分区的字段不要和表的字段相同。相同会报错error10035
载入数据:将相同分区的数据放到一个表里
1,bfy01,1
2,bfy02,1
3,bfy03,1
4,bfy04,1
5,bfy05,1
//student_1.txt
6,bfy06,2
7,bfy07,2
8,bfy08,2
load data local inpath '/usr/local/soft/bigdata19/hivedata/student_1.txt' into table t_student partition(grade=1);
--分区的列的值是分区的值,不是原来的值,即使分区的列值与分区值不一样,在进入分区后也会变成分区值,它不会检查数据,认为只要是进入到这个分区的就是这个分区的值。
多分区表语法
CREATE TABLE IF NOT EXISTS t_teacher (
tno int,
tname string
) partitioned by(grade int,clazz int)
row format delimited fields terminated by ',';
--注意:前后两个分区的关系为父子关系,也就是grade文件夹下面有多个clazz子文件夹。
数据:
1,bfy01,1,1
2,bfy02,1,1
3,bfy03,1,2
4,bfy04,1,2
7,bfy05,2,1
8,bfy06,2,1
load data local inpath '/usr/local/soft/bigdata19/hivedata/teacher_1.txt' into table t_teacher partition(grade=1,clazz=1);
分区表查询
select * from t_student where grade = 1;
// 全表扫描,不推荐,效率低
select count(*) from students_pt1;
// 使用where条件进行分区裁剪,避免了全表扫描,效率高
select count(*) from students_pt1 where grade = 1;
// 也可以在where条件中使用非等值判断
select count(*) from students_pt1 where grade<3 1 and grade>=1;
查看分区
show partitions t_student;
添加分区
alter table t_student add partition (grade=5);
alter table t_student add partition (grade=5) location '指定数据文件的路径';
删除分区
alter table t_student drop partition (grade=5);
动态分区(DP)
- 动态分区(DP)dynamic partition
- 静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进行判断。
- 详细来说,静态分区的列是在编译时期通过用户传递来决定的;动态分区只有在SQL执行时才能决定。
开启动态分区
# 表示开启动态分区
hive> set hive.exec.dynamic.partition=true;
# 表示动态分区模式:strict(需要配合静态分区一起使用)、nostrict
# strict: insert into table students_pt partition(dt='anhui',pt) select ......,pt from students;
hive> set hive.exec.dynamic.partition.mode=nonstrict;
动静态分区的优缺点
- 优点:不用手动指定了,自动会对数据进行分区
- 缺点:可能会出现数据倾斜
Hive分桶
分区提供了一个隔离数据和优化查询的便利方式,不过并非所有的数据都可形成合理的分区,尤其是需要确定合适大小的分区划分方式
不合理的数据分区划分方式可能导致有的分区数据过多,而某些分区没有什么数据的尴尬情况
分桶是将数据集分解为更容易管理的若干部分的另一种技术。
分桶就是将数据按照字段进行划分,可以将数据按照字段划分到多个文件当中去。
分桶原理
Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
数据分桶优势
方便抽样
使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便
提高join查询效率
获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
分桶和分区的区别
首先,分区和分桶是两个不同的概念,很多资料上说需要先分区在分桶,其实不然,分区是对数据进行划分,而分桶是对文件进行划分。
当我们的分区之后,最后的文件还是很大怎么办,就引入了分桶的概念。
将这个比较大的文件再分成若干个小文件进行存储,我们再去查询的时候,在这个小范围的文件中查询就会快很多。
分桶操作
开启分桶支持
set hive.enforce.bucketing=true;
数据准备(id,name,age)
1,tom,11
2,cat,22
3,dog,33
4,hive,44
5,hbase,55
6,mr,66
7,alice,77
8,scala,88
创建一个普通的表
create table psn31
(
id int,
name string,
age int
)
row format delimited
fields terminated by ',';
将数据load到这张表中
load data local inpath '文件在Linux上的绝对路径' into table psn31;
创建分桶表
create table psn_bucket
(
id int,
name string,
age int
)
clustered by(age) into 4 buckets
row format delimited
fields terminated by ',';
将数据insert到表psn_bucket中
(注意:这里和分区表插入数据有所区别,分区表需要select 和指定分区,而分桶则不需要)
insert into psn_bucket select id,name,age from psn31;
在Hive进行查询
-- tablesample是抽样语句,语法:TABLESAMPLE(BUCKET x OUT OF y)
-- 分桶语句中的分母表示的是数据将会被散列的桶的个数,分子表示将会选择的桶的个数。
-- x表示从哪个bucket开始抽取。
-- 例如,table总bucket数为32,tablesample(bucket 2 out of 2)
-- 表示总共抽取(2/2=)1个bucket的数据,分别为第2个bucket和第(2+2=)4个bucket的数据
-- y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。
-- 例如,table总共分了4份,当y=2时,抽取(4/2=)2个bucket的数据,当y=8时,抽取(4/8=)1/2个bucket的数据
select * from psn_bucket tablesample(bucket 3 out of 2);
随机取值(设置因子,桶的个数/因子)
这里就是取2号桶和4号桶,取2个
select * from psn_bucket tablesample(bucket 2 out of 4);
随机取值(设置因子,桶的个数/因子)
这里就是取2号桶,取一个
select * from psn_bucket tablesample(bucket 2 out of 8);
随机取值(设置倍数,倍数/桶的个数)
这里就是取2号桶 1/2个数据
取出来是一条数据
抽样命令TABLESAMPLE(BUCKET x OUT OF y)中,y必须是表格中分桶数的倍数或者因子。Hive根据y的大小,决定抽样的比例。x表示从哪个桶开始抽取。例如,表格的总分桶数为16,tablesample(bucket 3 out of 8),表示总共抽取(16/8=)2个bucket的数据,分别为第3个桶和第(3+8=)11个桶的数据


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!