

Hadoop HA(高可用)、脑裂、联邦机制详解
Hadoop HA(高可用)
一、hadoop1.x的问题
1.单点故障
- 每个集群只有一个NameNode,NameNode存在单点故障(SPOF)
- 如果该计算机或者NameNode进程不可用,那么整个集群在NameNode重启或在另一台计算机上启动之前不可用
- 计划内的维护事件,例如NameNode计算机上的软件或者硬件升级,将导致集群停机的时间延长
2.将来水平扩展服务器启动的时候,启动速度慢
3.namenode随着业务的增多,内存占用也会越来越多,如果namenode内存占满,将无法提供服务
4.日志丢失问题
二、解决这些问题的设计思路
- hadoop2.x后启用了主备节点切换的模式
- 当主节点出现异常的时候,集群将备用节点切换成主节点,那么就要备用节点能立刻工作,主备节点的内存需要同步
- 需要一个独立的线程来监控主备节点的健康状态,来判断是否需要切换主备节点
- 需要有一定的选举机制来帮我们判断集群启动的时候谁当主节点,谁当备用节点
- 需要存储日志的中间件,让主备节点都能从中获取日志
三、Active NameNode(ANN)活跃的主节点
功能上与NameNode一致。
- 接收用户端请求,查询block块的位置信息
- 存储数据的元数据信息,包括文件的权限、归属、大小、修改时间、block块信息
- 启动时:接收DN汇报的block块信息,运行时:时刻与DN保持心跳机制(3S 10Min)
四、Standby NameNode(SNN)备用主节点
它和主节点做一样的工作,但是不会发送任何命令,一个集群中只能有一个活跃的主节点。
五、hadoop HA流程图
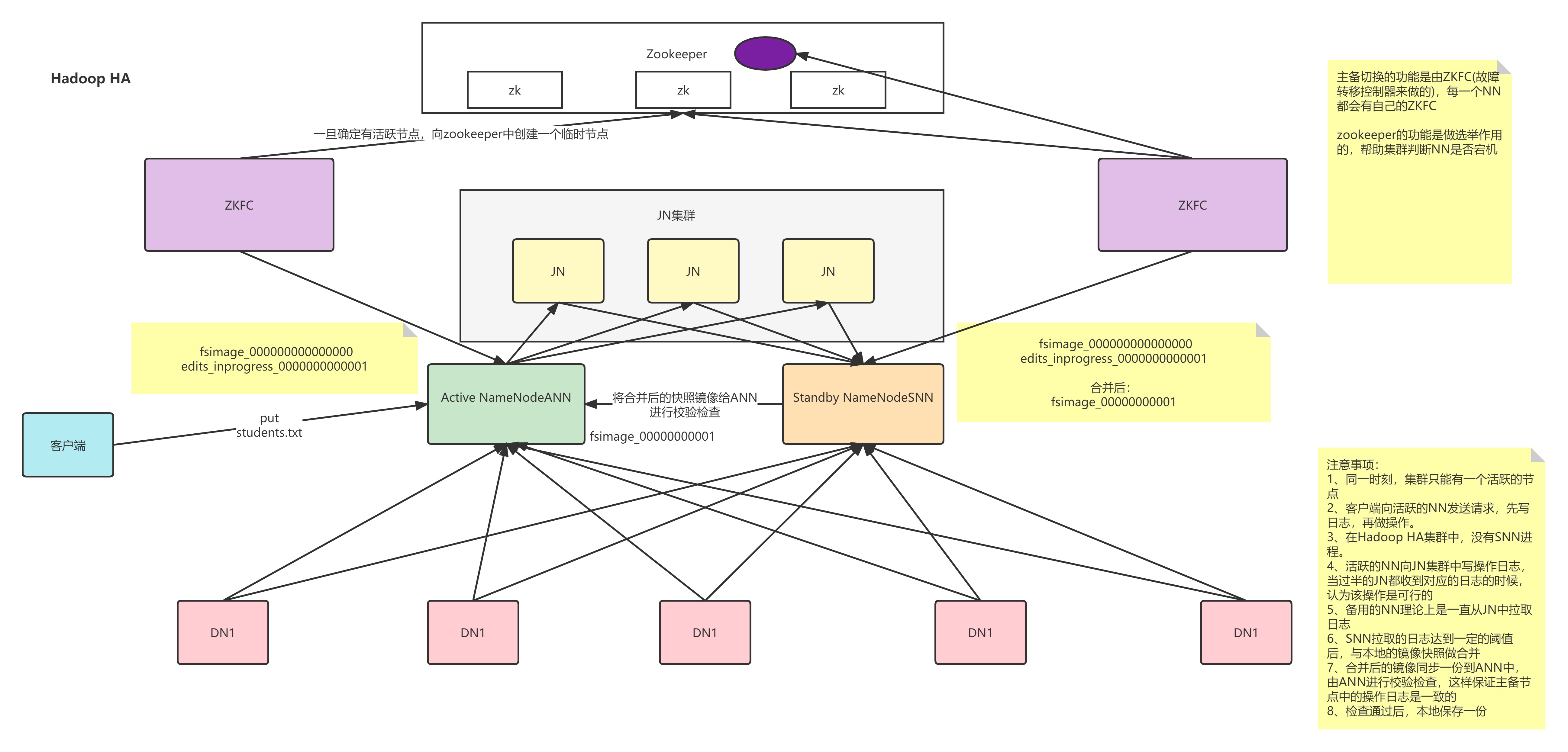
当我们搭建好集群的时候,格式化主备节点,ANN和SNN都会默认创建fsimage_000000000000000这样的快照文件,当客户端发送请求,ANN接收到后会产生日志信息edit_inprogress_0000000000001。活跃主节点会将新产生的日志信息同步到 JournalNode(JN)集群上每个节点上,JN不要求所有的节点都接收到日志,只要有半数以上的节点接收到,那么这条日至就会生效。Standby NameNode 每隔一段时间就会去JournalNode集群上取回最新的日志,SNN拉取的日志达到一定阈值后与本地的快照文件做合并生成新的快照文件,将新的快照文件复制一份发给ANN 进行校验检查,无误后SNN保留这个新的快照。这样可以最大程度上保证主备节点的日志一致。那么主备节点是如何切换的,HDFS是如何判断主节点宕机的。当集群启动时,Failover Controller(ZKFC:故障转移控制器)如果只检查到一个节点是健康状态,就会直接把这个节点设置为主节点,如果检查到两个健康状态的节点,发起选举机制,利用zookeeper集群来完成主备选举。NameNode选举成功后,监控活跃主节点的ZKFC会在zookeeper上创建一个临时节点,这个临时节点由备用主节点的ZKFC监控。如果ZFKC监控到主节点异常,就会删除这个临时节点,此时备用节点的监视器就会接收到这个临时节点删除的信息,并创建一个新的临时节点,备用节点切换成活跃节点。
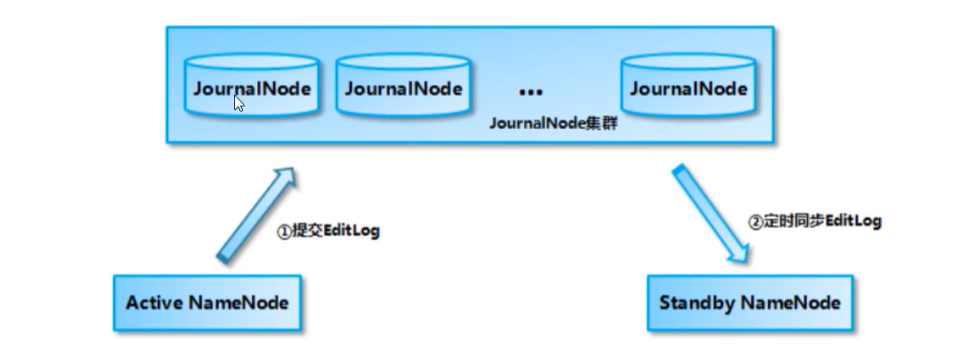
JournalNode(JN)
- Quorum JournalNode Manager 共享存储系统,NameNode通过共享存储系统实现日志数据同步。
- JournalNode是一个独立的集群
- ANN产生日志文件的时候,就会同时发送到journalNode的集群中的每个节点上,JN不要求所有的节点都能接收到日志,只要有半数以上的节点收到,那么这条日志就生效。
- StandBy NameNode 每隔一段时间就去Quorum JournalNode Manager上取回最新的日志
- JournalNode只允许存在一个活跃的主节点,在故障转移,主备切换期间,由变为活跃状态的主节点承担往journalNode写入日志的角色,防止另一个namenode继续处于活跃状态,从而使新的active节点可以安全的进行故障转移
ZK FailoverController(ZKFC:故障转移控制器)
对JNameNode的主备切换进行总体控制,能及时检测到NameNode的健康状况。在主节点故障时,借助ZooKeeper实现自动的主备选举和切换。
运行时:
ZK FailoverController启动的时候会创建HealthMonitor和ActiveStandbyElector这两个内部组件。HealthMonitor主要负责检测NameNode的健康状态
ActiveStandbyElector主要负责自动的主备选举,内部封装了ZooKeeper的处理逻辑。
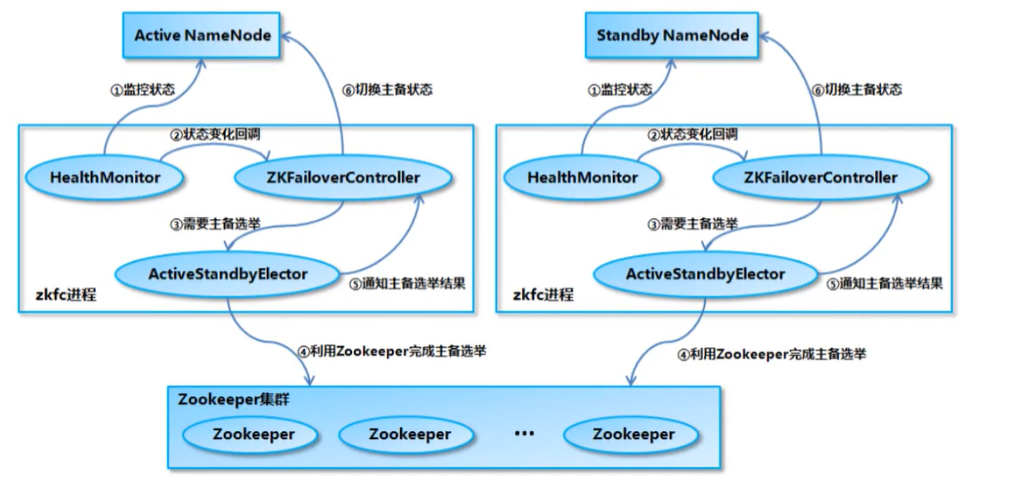
主备节点正常切换
NameNode 在选举成功后, ActiveStandbyElector 会在 zk 上创建一个
ActiveStandbyElectorLock 临时节点,而没有选举成功的备 NameNode 中的ActiveStandbyElector 会监控这个节点
如果 Active NameNode 对应的 HealthMonitor 检测到 NameNode 的状态异常时,ZKFailoverController 会主动删除当前在 Zookeeper 上建立的临时节点ActiveStandbyElectorLock
处于 Standby 状态的 NameNode 的 ActiveStandbyElector 注册的监听器就会收到这个节点的 NodeDeleted 事件,并创建 ActiveStandbyElectorLock 临时节点,本来处于 Standby 状态的 NameNode 就选举为 Active NameNode 并随后开始切换为 Active 状态。
如果是 Active NameNode 的机器整个宕掉的话,那么跟 zookeeper 连接的客户端线程也挂了 , 会话结束 , 那么根据 Zookeepe 的临时节点特性, ActiveStandbyElectorLock 节点会自动被删除,从而也会自动进行一次主备切换,
Zookeeper
为主备节点切换控制器提供主备选举支持
辅助投票
和ZKFC保持心跳机制,确定ZKFC的存活
六、脑裂brain-split
定义
脑裂是 Hadoop2.X 版本后出现的全新问题,实际运行过程中很有可能出现两个 namenode 同时服务于整个集群的情况,这种情况称之为脑裂。
原因
脑裂通常发生在主从 namenode 切换时,由于 ActiveNameNode 的网络延迟、设备故障等问题,另一个 NameNode 会认为活跃的 NameNode 成为失效状态,此时 StandbyNameNode 会转换成活跃状态,此时集群中将会出现两个活跃的 namenode 。因此,可能出现的因素有网络延迟、心跳故障、设备故障等。
脑裂场景
NameNode 可能会出现这种情况, NameNode 在垃圾回收( GC )时,可能会在长时间内整个系统无响应
zkfc 客户端也就无法向 zk 写入心跳信息,这样的话可能会导致临时节点掉线,备 NameNode会切换到 Active 状态
这种情况可能会导致整个集群会有同时有两个 Active NameNode
脑裂问题的解决方案是隔离( Fencing )
- 第三方共享存储:任一时刻,只有一个 NN 可以写入;
- DataNode :需要保证只有一个 NN 发出与管理数据副本有关的命令;
- Client 需要保证同一时刻只有一个 NN 能够对 Client 的请求发出正确的响应。
a) 每个 NN 改变状态的时候,向 DN 发送自己的状态和一个本次选举对应的序列号。
b) DN 在运行过程中维护此序列号,当 failover 时,新的 NN 在返回 DN 心跳时会返回自己的 active 状态和一个更大的序列号。
DN 接收到这个返回是认为该 NN 为新的 active 。
(c) 如果这时原来的 active (比如 GC )恢复,返回给 DN 的心跳信息包含 active 状态和原来的序列号,这时 DN 就会拒绝这个 NN 的命令。
解决方案
ActiveStandbyElector 为了实现 fencing ,当 NN 成为 ANN 之后创建 Zookeeper 临时节点ActiveStandbyElectorLock ,创建 ActiveBreadCrumb 的持久节点,这个节点里面保存了这个Active NameNode 的地址信息 (node-01)
Active NameNode 的 ActiveStandbyElector 在正常的状态下关闭 Zookeeper Session 的时候,会一起删除这个持久节点
但如果 ActiveStandbyElector 在异常的状态下关闭,那么由于 /hadoop ha/${dfs.nameservices}/ActiveBreadCrumb 是持久节点,会一直保留下来,后面当另一个NameNode 选主成功之后,会注意到上一个 Active NameNode 遗留下来的这个节点,从而会回调 ZKFailoverController 的方法对旧的 Active NameNode 进行 fencing 。
首先尝试调用这个旧 Active NameNode 的 HAServiceProtocol RPC 接口的transitionToStandby 方法,看能不能把它转换为 Standby 状态;
如果 transitionToStandby 方法调用失败,那么就执行 Hadoop 配置文件之中预定义的隔离措施。 - sshfence :通过 SSH 登录到目标机器上,执行命令 fuser 将对应的进程杀死
- shellfence :执行一个用户自定义的 shell 脚本来将对应的进程隔离
在成功地执行完成 fencing 之后,选主节点成功的 ActiveStandbyElector 才会回调ZKFailoverController 的 becomeActive 方法将对应的 NameNode 转换为 Active 状态,开始对外提供服务。新的主创建临时节点 ActiveStandbyElectorLock ,创建持久化节点 ActiveBreadCrumb ,并将自己的主机地址 Node02 赋值给初始化节点
七、Hadoop-federation(联邦机制)
Namespace(命名空间)的限制
单个datanode从4T增长到36T,集群的尺寸增长到8000个datanode。存储的需求从12PB增长到大于100PB。
性能的瓶颈
由于是单个Namenode的HDFS架构,因此整个HDFS文件系统的吞吐量受限于单个Namenode的吞吐量。毫无疑问,这将成为下一代MapReduce的瓶颈。
隔离问题
由于HDFS仅有一个Namenode,无法隔离各个程序,因此HDFS上的一个实验程序就很有可能影响整个HDFS上运行的程序。那么在HDFS Federation中,可以用不同的Namespace来隔离不同的用户应用程序,使得不同Namespace Volume中的程序相互不影响。
集群的可用性
在只有一个Namenode的HDFS中,此Namenode的宕机无疑会导致整个集群不可用。
Namespace和Block Management的紧密耦合
当前在Namenode中的Namespace和Block Management组合的紧密耦合关系会导致如果想要实现另外一套Namenode方案比较困难,而且也限制了其他想要直接使用块存储的应用。
为什么纵向扩展目前的Namenode不可行?比如将Namenode的 JVM Heap空间扩大到512GB。
这样纵向扩展带来的第一个问题就是启动问题,启动花费的时间太长。当前具有50GB Heap Namenode的HDFS启动一次大概需要30分钟到2小时,那512GB的需要多久?第二个潜在的问题就是Namenode在Full GC时,如果发生错误将会导致整个集群宕机。第三个问题是对大JVM Heap进行调试比较困难。优化Namenode的内存使用性价比比较低。
联邦机制流程
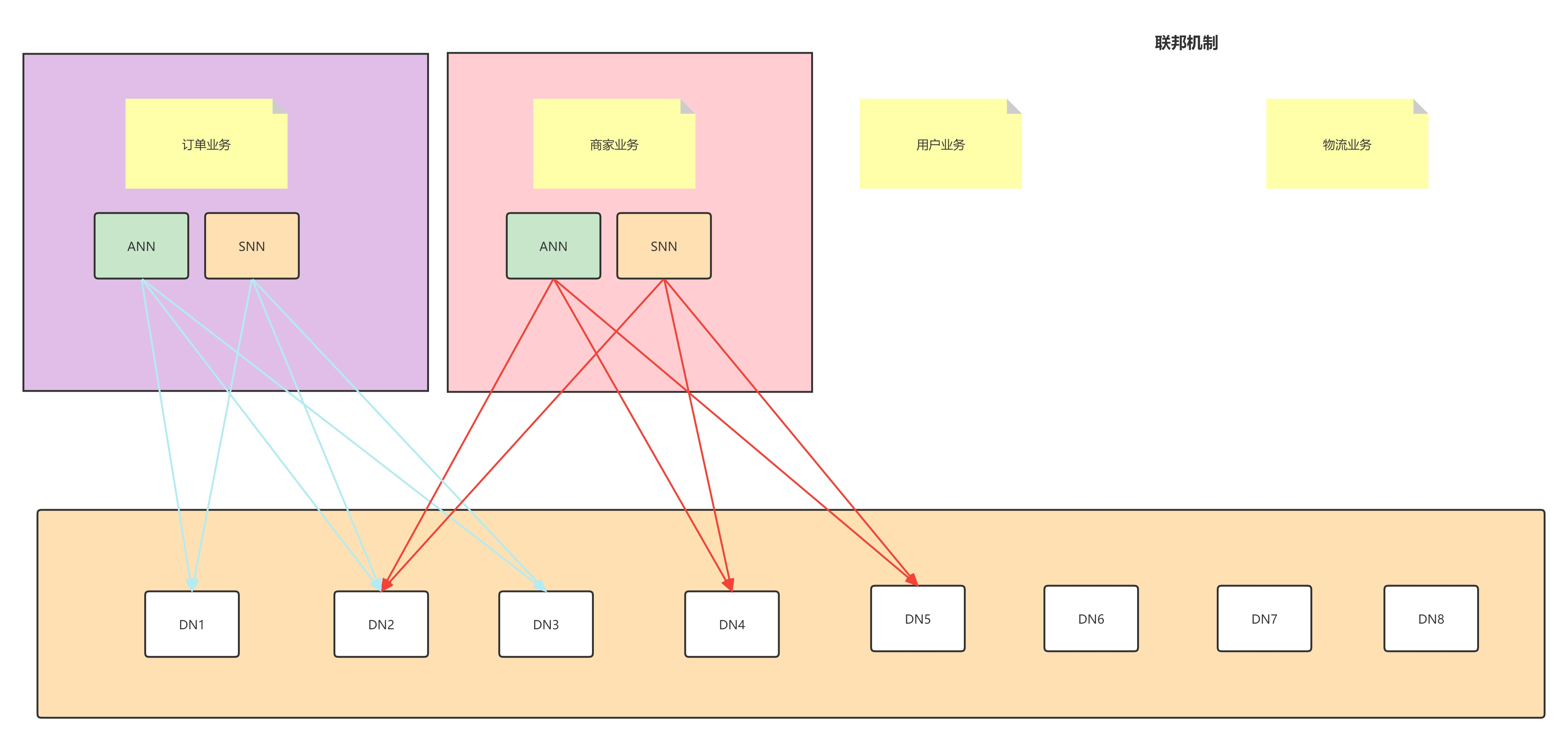
理解:联邦机制就是水平扩展业务,NameNode提供了命名空间(NameSpace)和块(block)管理功能,每个命名空间管理属于自己的一组块,这些块构成了块池(block pool),每个DataNode都可以存储所有块池中的块,也就是说所有的块共享DataNode。块池是一个逻辑概念,当datanode与Namenode建立联系并开始会话后自动建立Block pool。每个block都有一个唯一的标识,这个标识我们称之为扩展的块ID(Extended Block ID)= BlockID+BlockID。这个扩展的块ID在HDFS集群之间都是唯一的,Datanode中的数据结构都通过块池ID(BlockPoolID)索引。通过构建联邦机制的形式将元数据的存储和管理分到多个节点中,降低了单个节点的数据压力,同时,一个节点出现问题不会导致其他节点不工作。
注意:联邦机制和HA完全不一样的,是解决不一样的问题,联邦机制解决的是业务水平扩展的问题,HA解决的是单点故障的问题


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!