
Python Web编程
1.统一资源定位符(URL)
URL用来在Web上定位一个文档。浏览器只是Web客户端的一种,任何一个向服务器端发送请求来获取数据的应用程序都被认为是客户端
URL格式:port_sch://net_loc/path;params?query#frag
port_sch 网络协议或者下载规划,如http
/net_loc 服务器位置,如www.baidu.com
path 斜杠/限定文件或者CGI应用程序的路径
params 可选参数
query 连接符&连接键值对
frag 拆分文档中的特殊锚
2.urllib模块


1 urlopen(urlstr,postQueryData=None) #打开一个给定URL字符串与Web连接,并返回了文件类的对象 2 f.read([bytes]) #从f中读出所有或bytes个字节 3 f.readline() #从f中读出一行 4 f.readlines() #从f中读出所有行并返回一个列表 5 f.close() #关闭f的URL的连接 6 f.fileno() #返回f文件的句柄 7 f.info() #获得f的MIME头文件,文件类型可以用哪类应用程序打开 8 f.geturl() #返回f所打开的真正的URL 9 10 urlretrieve(urlstr,localfile=None,downloadStatusHook=None) 11 #可以方便地将urlstr定位到的整个HTML文件下载到本地的硬盘上。 12 #返回一个二元组(filename,mine_hdrs),filename是包含下载数据的本地文件名,mine_hdrs是对Web服务器响应后返回的一系列MIME文件头 13 14 quote(urldata,safe='/') #将urldata的无效的URL字符编码;在safe列的则不必编码
3.urllib.request
在Python3.3后urllib2已经不能再用,只能用urllib.request来代替,可以处理更复杂URL的打开问题,如有基本认证(登录名和密码名)需求的Web站点
基本的网络请求示例
1 import urllib.request 2 3 f = urllib.request.urlopen('http://www.baidu.com',data=None,timeout=10) #请求百度网页,超过10s为请求超时 4 print(f.read().decode('utf-8')) #读取所有字节数据并解码 5 print(f.status) #请求头信息 200代表成功 404代表网页未找到
urllib.request.Request(urll,data=None,headers={},method=None)
headers参数是一个字典,可以在构造Request时传参,也可以通过调用Request对象的add_header()方法来添加请求头,默认的User-Agent是Python-urllib可修改它来伪装成浏览器
method是一个字符串,用来指定请求使用的方式,如GET POST PUT
4.GET、PUT、POST
1、GET请求会向数据库发索取数据的请求,从而来获取信息,该请求就像数据库的select操作一样,只是用来查询一下数据,不会修改、增加数据,不会影响资源的内容,即该请求不会产生副作用。无论进行多少次操作,结果都是一样的。
2、与GET不同的是,PUT请求是向服务器端发送数据的,从而改变信息,该请求就像数据库的update操作一样,用来修改数据的内容,但是不会增加数据的种类等,也就是说无论进行多少次PUT操作,其结果并没有不同。
3、POST请求同PUT请求类似,都是向服务器端发送数据的,但是该请求会改变数据的种类等资源,就像数据库的insert操作一样,会创建新的内容。几乎目前所有的提交操作都是用POST请求的。
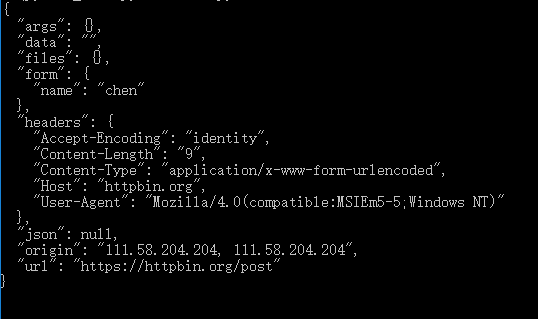
1 from urllib import request,parse 2 3 url = "http://httpbin.org/post" 4 headers = { #伪装成一个火狐浏览器 5 "User-Agent":'Mozilla/4.0(compatible:MSIEm5-5;Windows NT)', 6 "host":'httpbin.org' #httpbin.org 这个网站能测试 HTTP 请求和响应的各种信息,比如 cookie、ip、headers 和登录验证等,且支持 GET、POST 等多种方法 7 } 8 9 dict = {"name":"chen"} 10 data = bytes(parse.urlencode(dict),encoding="utf-8") #data如果是一个字典,可先用urllib.parse.urlencode()编码,再用bytes转换成字节流 11 req = request.Request(url = url,data=data,headers=headers,method='POST') #data须是字节流 12 response = request.urlopen(req) 13 print(response.read().decode('utf-8'))
返回结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号