
Python 正则
正则表达式:用来匹配字符串
要导入re模块
\d 匹配一个数字 \D匹配任意非数字 \w匹配一个字母或数字 . 匹配任意字符
* 任意个字符 + 至少一个字符 ? 0个或1个字符 \n匹配一个换行符
\s 一个空格 \S匹配任意非空字符 {n} n个字符 {n,m} 表示n~m个字符
[ ] 范围 [0-9a-zA-Z\_] 匹配一个数字、字母或者下划线 [^abc]匹配除了a,b,c之外的字符
A|a 匹配A或a ^ 行的开头 ^\d 必须以数字开头 \t匹配一个制表符
$ 行的结束 \d$ 必须以数字结束 ( )( ) 分组 \G匹配最后匹配完成的位置
反斜杠本身需要使用反斜杠转义,标点符号只有被转义时才匹配自身,否则它们表示特殊的含义
1 #!/usr/bin/python3 2 3 import re 4 5 #re.match(正则表达式, 要拿来匹配的字符串) 成功返一个math对象 否则返回Node 6 m = re.match(r'^(\d{3})-(\d{3,8})$', '666-123456') 7 print(m) 8 9 #re.split(正则表达式, 要拿来匹配的字符串) 以正则表达式作为分隔符 10 print( re.split(r'[\s\,]+', 'a,b,c, d') ) #以空格或,分割 11 12 #提取字串 13 print( m.group(0) ) #group(0)永远是原始字符 14 print( m.group(1) ) 15 print( m.group(2) )

正则匹配默认是贪婪匹配

由于\d+采用贪婪匹配,直接把后面的0全部匹配了,结果(0*)分组只能匹配空字串了
要抑制贪婪匹配,+?
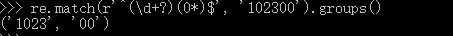
如正则表达式重复使用多次,可预编译该正则表达式,提高效率
re.compile(pattern[,flags]) pattern正则表达式,flags可选,表示匹配模式,多个匹配模式通过 | 来分隔
re.I忽略大小写 re.X为增加可读性,忽略空格和“#”后面的注释
re.M多行匹配,影响^和$ re.S使.匹配包括换行在内的所有字符
#!/usr/bin/python3 import re #编译正则 re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$') #直接使用正则 print( re_telephone.match('098-23432').groups() )

re.search(pattern,string,flags=0) 扫描整个字符串并返回第一个成功的匹配
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
re.sub(pattern,repl,string,count=0) repl:替换的字符串,也可为一个函数 string要被查找替换的原始字符串 count:替换的最大次数,默认0表示替换所有匹配
1 import re 2 3 phone = '0123-959-555' #这是一个电话号码 4 num = re.sub(r'\D',"",phone) #移除非数字的内容 5 print("电话号码:",num) #电话号码: 0123959555
findall(string[,start[,end]]) 在字符串中找到正则表达式所匹配的所有子串,成功返所有匹配部分的列表,没有找到会返空列表。start开始,默认0;end结束,默认字符串长度
1 import re 2 3 pattern = re.compile(r'\d+') 4 result = pattern.findall('asd 154 asdaa 888') 5 print(result) #['154', '888']
re.finditer(pattern,string,flags=0) 与findall类似,不过返回的是迭代器
1 import re 2 3 it = re.finditer(r'\d+','12adf887fadf28') 4 for match in it: 5 print(match.group(),end=" ") #12 887 28
re.split(pattern,string[,maxsplit=0,flags=0]) 照能够匹配的子串将字符串分割后返回列表,maxsplit分隔次数,默认不限制
1 import re 2 3 L = re.split(',','runoob,225,fqwr3555.') 4 print(L) #['runoob', '225', 'fqwr3555.']
正则匹配中文
固定形式 \u4E00-\u9FA5
1 import re 2 3 s = re.search(r'[\u4E00-\u9FA5]+-\d+','南宁市-0771') 4 print(s.group(0)) #南宁市-0771

 浙公网安备 33010602011771号
浙公网安备 33010602011771号