Linux 定时器与进程同步
Linux实验报告
实验八 :定时器实验
1.1 实验目的
- 通过实验加深对定时器的理解。
- 掌握设计定时器的方法。
1.2 实验任务
注册一个定时器,使其 5 s后得到执行,打印提示信息。
1.3 实验原理及方法
1.3.1 实验原理
- 定时器实验主要原理是对
jiffies的理解:
jiffies记录自系统启动以来产生的节拍总数。- 系统运行时间=
jiffies/HZ。 - 无符号长整型,在 32 位机上为 32 位,在 64 位机上为64 位 。
- 定时器就是利用到达
jiffies时,执行所指定的函数操作来实现的。
1.3.2 实验方法
- Linux在
<linux/timer.h>头文件中定义了数据结构timer_list来描述一个内核定时器:
struct timer_list {
struct list_head list;
unsigned long expires;
unsigned long data;
void (*function)(unsigned long);
};
- 现在对上面结构体内容进行逐个解释:
-
struct list list_head list:list是一个双向列表元素用来将多个定时器链接成为一条双向循环队列。 -
expires:字段表示期望定时器执行的jiffies值,到达该jiffies值时,将调用function函数 -
函数指针
function:指向一个可执行函数。当定时器到期时,内核就执行function所指定的函数。 -
data:被内核用作function函数的调用参数。
- 有了数据结构还需要对几个调用函数进行说明
timer_setup(timer, callback, flags): 用于为第一次使用timer做好准备,一般和add_timer 配合使用。其中的callback用于指定expires到期时要执行的函数。timer_add(struct timer_list *timer):用于开始一个定时器。mod_timer(struct timer_list *timer, unsigned long expires):用于修改定时器的expires。del_timer(struct timer_list *timer):删除定时器。
- 有了上述基础便可以开始编写自己的定时器了:下面便是定时器模块的源程序
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/timer.h>
#include <linux/jiffies.h>
struct timer_list test_timer; //建立定时器的数据结构
void timer_function(struct timer_list *timer){
printk(">>>The timer is running!\n"); // printk函数输出需要使用dmesg命令查看
mod_timer(&test_timer, jiffies + 5000); //修改expires,等待到达设置的值执行timer_function()
}
int timer_init(void){ // 此函数用作插入模块时执行
test_timer.expires = jiffies + 5000; // linux中时钟频率为1000HZ,加5000即为5秒后执行
timer_setup(&test_timer, timer_function, 0); // 指定定时器到期时要执行的函数timer_function()
add_timer(&test_timer); // 开始定时器
printk(">>>The timer is ready!\n");
return 0;
}
void timer_exit(void){ // 此函数用作模块卸载时执行
printk(">>>The timer is already delete.\n");
del_timer(&test_timer); // 删除定时器
}
module_init(timer_init); // 插入模块
module_exit(timer_exit); // 卸载模块
MODULE_LICENSE("GPL");
Makefile中代码如下:
obj-m := timer_clock.o #表示将timer_clock.o 编译为模块
CURRENT_PATH := $(shell pwd)
LINUX_KERNEL := $(shell uname -r)
LINUX_KERNEL_PATH := /lib/modules/$(LINUX_KERNEL)/build
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
# -C 将当前工作目录转移到指定的位置
# 程序会自动到指定的dir目录中查找模块源码,将其编译,生成.ko文件
.PHONY:install clean uninstall #.PHONY 用于说明伪目标,即下面三个伪目标
install:
insmod timer_clock.ko # 使用 make install 加载模块
clean:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) clean
uninstall:
rmmod timer_clock.ko #使用 make uninstall 卸载模块
1.4 实验结果
- 执行
make得到下列文件现在就可以安装与卸载模块了:

- 执行
make install进行安装模块:(使用dmesg命令对输出进行查看)

- 使用
make uninstall对模块进行卸载:

1.5 实验遇到的问题及总结
1.5.1 遇到的问题
实验总体没有遇到大的问题,遇到最大的问题就是makefile文件的编写,一开始找不到内核地址,导致makefile无法通过,后来通过查找资料将makefile中的内核地址进行修改便成功执行了。
1.5.2 实验总结
定时器实验最难的地方其实不是编程,最难的地方时对定时器的理解,比如expires为什么加上5000便可以在5秒后执行。这些问题需要网上搜索很多资料才能比较好的理解定时器的使用方法。总之,通过本次实验,我收获还是比较多的,能够完成定时器的卸载和插入模块并且懂得了定时器的基本原理,并且使我对lLinux内核中的时间概念有了一定的了解。
实验十一:进程同步实验
2.1 实验目的
-
通过应用层的进程同步实验,加深其原理的理解。
-
掌握应用层的同步编程方法。
2.2 实验任务
采用信号量实现进程之间的同步:即采用 P、V 操作,使两个进程同步完成工作,一个进程负责与用户的交互(读取两个整数与显示结果),另一个进程负责处理数据(整数相加)。
2.3 实验原理及方法
2.3.1 实验原理
- 最基本的原理就是操作系统课上学的进程之间通过P、V操作进行实现同步与互斥,这里主要讲解实验中的同步原理
- 由
mmap()函数建立进程之间共享的变量sum、num1、num2。 - 创建两个子进程一个用于对数字进行要求输入,另一个进行加法和输出
- 创建两个信号量用
semid1和semid2进行标识信号量,对第一个信号量赋值为1,第二个信号量赋值为-1。 - 为什么要这么做呢?因为一次只能有一个进程可以对于
sum、num1、num2三个变量进行访问,这边假设进程a用作输入操作,进程b用作输出操作,首先,进入进程a,然后a进程对semid1信号量进行P操作,第一个信号量值为1,那么刚好可以获得对数据的访问同时第一个信号量值变为0,然后进程b会对semid2信号量执行P操作,然而输入未完成semid2的值为0,进程b进入循环等待。直到用户输入数据后,进程a执行V操作使得semid2信号量值加一,进程b得以运行,如此循环往复。
2.3.2 实验方法
- 首先依旧是对结构体进行了解,
Linux在<linux/sem.h>中定义了sembuf结构体,用于对信号量进行表示与操作:
struct sembuf{
short sem_num;
short sem_op; // sem_op用于指定semop()函数所要执行的操作
short sem_flg;
};
- 对结构体字段进行逐个解释:
sem_num:信号量的编号,如果不需要使用一组信号量,这个值一般就取为0。sem_op:是信号量一次PV操作时加减的数值,一般只会用到两个操作,一个是-1,也就是P操作,等待信号量变得可用;另一个是+1,也就是V操作,发出信号量已经变得可用。sem_flg:通常被设置为SEM_UNDO.使操作系统跟踪当前进程对该信号量的修改情况。
- 然后还有一个重要的
union联合体需要我们关心:
union semun{
int val; // 最主要关心的是val值,用于给信号量赋值
struct semid_ds *buf;
unsigned short *array;
struct seminfo *__buf;
};
- 有了信号量,现在对信号量的操作需要调用的函数进行解释
- 首先最重要的是
mmap函数,这是一个十分重要的函数,在进程同步中是用来实现进程间共享变量的,原型声明如下:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset)
函数原型解释如下:
1.fd, offset和length都是用来描述要映射的文件区域的,"offset"是文件中映射的起始位置,"length"是映射的长度,"fd"是文件描述符,对于匿名映射,fd应该是-1。
2.prot:用于设置内核映射区域的读写属性等。
3.flags:用于设置内存映射的属性,例如共享映射、私有映射等。
4.addr:用于指定映射到进程空间的起始地址,为了应用程序的可移植性,一般设置为NULL,让内核来选择一个合适的地址。
返回值:成功,返回创建的映射区首地址;失败,返回MAP_FAILED宏。
-
int semget(key_t _key ,int _nsems,int _semflg):创建一个新的信号量或获取一个已经存在的信号量的键值,成功返回信号量标识码,失败,返回-1 -
int semop(int semid, struct sembuf *sops, unsigned nsops):对信号量集标识符为semid中的一个或多个信号量进行P操作或V操作 -
int semctl(int semid, int semnum, int cmd, union semun arg):得到一个信号量集标识符或创建一个信号量集对象并返回信号量集标识符
- 有了函数说明和结构体原型,现在便可以完成实验实现进程同步了:(实验源代码如下)
#include <stdio.h>
#include <sys/types.h>
#include <linux/sem.h>
#include <sys/mman.h>
#include <unistd.h>
#include <wait.h>
int semid1; // 用于得到信号量标识
int semid2;
int main(){
struct sembuf P,V;
union semun arg;
int *num1,*num2,*sum;
num1 = (int *)mmap(NULL, sizeof(int), PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);
num2 = (int *)mmap(NULL, sizeof(int), PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);
sum = (int *)mmap(NULL, sizeof(int), PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);
// 将三个变量映射到内存中,用于实现共享
*num1 = 0;
*num2 = 0;
*sum = 0;
// 创建信号量
semid1 = semget(IPC_PRIVATE, 1, IPC_CREAT | 00666);
semid2 = semget(IPC_PRIVATE, 1, IPC_CREAT | 00666);
/* set val for semid*/
arg.val = 1;
if(semctl(semid1, 0, SETVAL, arg) == -1)
perror("semctl setval error");
arg.val = 0;
if(semctl(semid2, 0, SETVAL, arg) == -1)
perror("semctl setval error");
V.sem_num = 0;
V.sem_op = 1;
V.sem_flg = SEM_UNDO;
P.sem_num = 0;
P.sem_op = -1;
P.sem_flg = SEM_UNDO;
if(fork() == 0){
while(1){
semop(semid1, &P, 1); // 对信号量semid1 进行p操作
printf("add<int>:please input the num1 and num2:");
scanf("%d%d", num1, num2);
semop(semid2, &V ,1); // 对信号量semid2 进行v操作
}
}else{
if(fork() == 0){
while(1){
semop(semid2, &P, 1); // 对信号量semid2 进行p操作
*sum = *num1 + *num2;
printf("%d + %d = %d \n", *num1, *num2, *sum);
semop(semid1, &V ,1); // 对信号量semid1 进行v操作
}
}
}
wait(NULL);
return 0;
}
- 我发现,实验指导书中使用了两个信号量,其实一个信号量就可以解决问题,说是同步量,更像是互斥量,只需要设置一个信号量,将其
val设置为1即可(更改为一个信号量,代码如下)
#include <stdio.h>
#include <sys/types.h>
#include <linux/sem.h>
#include <sys/mman.h>
#include <unistd.h>
#include <wait.h>
int semid;
int main(){
struct sembuf P,V;
union semun arg;
/*declare share memory*/
int *num1,*num2,*sum;
/*map the share memory*/
num1 = (int *)mmap(NULL, sizeof(int), PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);
num2 = (int *)mmap(NULL, sizeof(int), PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);
sum = (int *)mmap(NULL, sizeof(int), PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);
*num1 = 0;
*num2 = 0;
*sum = 0;
/*create semaphore*/
semid = semget(IPC_PRIVATE, 1, IPC_CREAT | 00666); // 与实验指导书不同只使用一个信号量
/* set val for semid*/
arg.val = 1;
if(semctl(semid, 0, SETVAL, arg) == -1)
perror("semctl setval error");
V.sem_num = 0;
V.sem_op = 1;
V.sem_flg = SEM_UNDO;
P.sem_num = 0;
P.sem_op = -1;
P.sem_flg = SEM_UNDO;
if(fork() == 0){
while(1){
semop(semid, &P, 1);
printf("add<int>:please input the num1 and num2:");
scanf("%d%d", num1, num2);
semop(semid, &V ,1);
}
}else{
if(fork() == 0){
while(1){
semop(semid, &P, 1);
*sum = *num1 + *num2;
printf("%d + %d = %d \n", *num1, *num2, *sum);
semop(semid, &V ,1);
}
}
}
wait(NULL);
return 0;
}
2.4 实验结果
- 通过用
gcc对sem.c进行编译链接形成可执行文件a.out - 执行结果如下:

2.5 遇到的问题及总结
2.5.1 遇到的问题
- 实验指导书中有一处错误,就是使用
wait函数没有加头文件,因此刚开始我把wait()函数删掉了,发现程序运行出来是这样的:
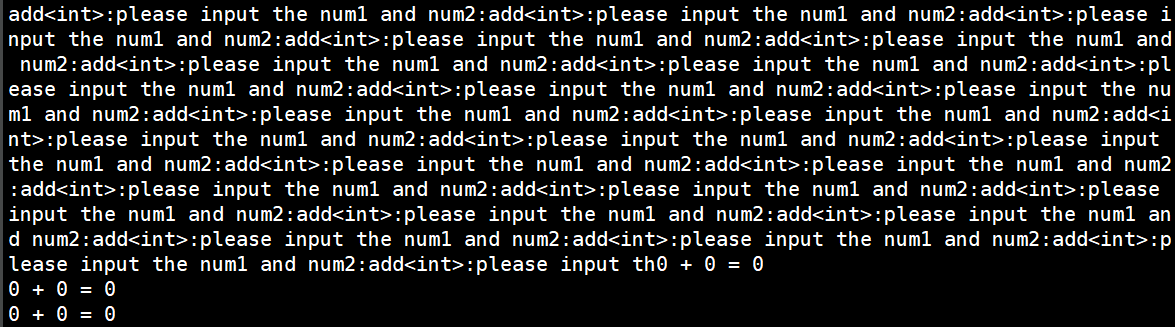
很是诧异,究竟是为什么导致这样的结果?经过查找资料,得知如果父进程不使用wait()函数进行等待的话,那么父进程会提前结束,导致其子进程成为孤儿进程,由pid为1的init进程进行托管。我的理解是两个孤儿进程成为了两个独立的进程所以会出现这种现象。
- 还有一个问题,关于c语言函数调用,进程同步中调用
mmap()函数时是这样的:
sum = (int *)mmap(NULL, sizeof(int), PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, -1, 0);
我不理解为中间的|是怎样的传参方式,查找资料也没有获得有效信息。
2.5.2 总结
进程同步实验,我觉得最难的地方就是对mmap()函数的理解,以及信号量和pv操作的理解。说实话,学操作系统的时候,对pv操作并不是特别理解,通过本次实验,有了具体的应用场景,我对信号量机制有了进一步的理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号