JMeter 源码解读 - HashTree
背景:
在 JMeter 中,HashTree 是一种用于组织和管理测试计划元素的数据结构。它是一个基于 LinkedHashMap 的特殊实现,提供了一种层次结构的方式来存储和表示测试计划的各个组件。
HashTree 的特点如下:
-
层次结构:HashTree 使用树状结构来组织测试计划元素。每个节点都可以包含子节点,这样就形成了一个层次结构。树的根节点是测试计划本身,而叶子节点是具体的测试元素(如线程组、HTTP 请求等)。
-
存储关联关系:HashTree 不仅存储了节点之间的层次关系,还存储了节点之间的关联关系。这意味着你可以在 HashTree 中方便地查找和获取节点之间的关联关系,而无需手动遍历整个树。
-
快速访问:HashTree 使用了 LinkedHashMap 来存储节点,这使得访问和检索元素变得非常高效。通过哈希表的快速访问特性,你可以根据节点的名称或其他属性,快速地获取到对应的节点。
具体介绍内容参考官方文档: http://jmeter.apache.org/api/org/apache/jorphan/collections/HashTree.html
jmx文件:
在 JMeter 中,JMX(Java Management Extensions)文件是测试计划的保存和加载文件格式。JMX 文件以 XML 格式编写,它包含了测试计划的配置信息、测试元素、线程组、监听器等各
个组件的设置和关系。而HashTree就是它在内存的一份映射。
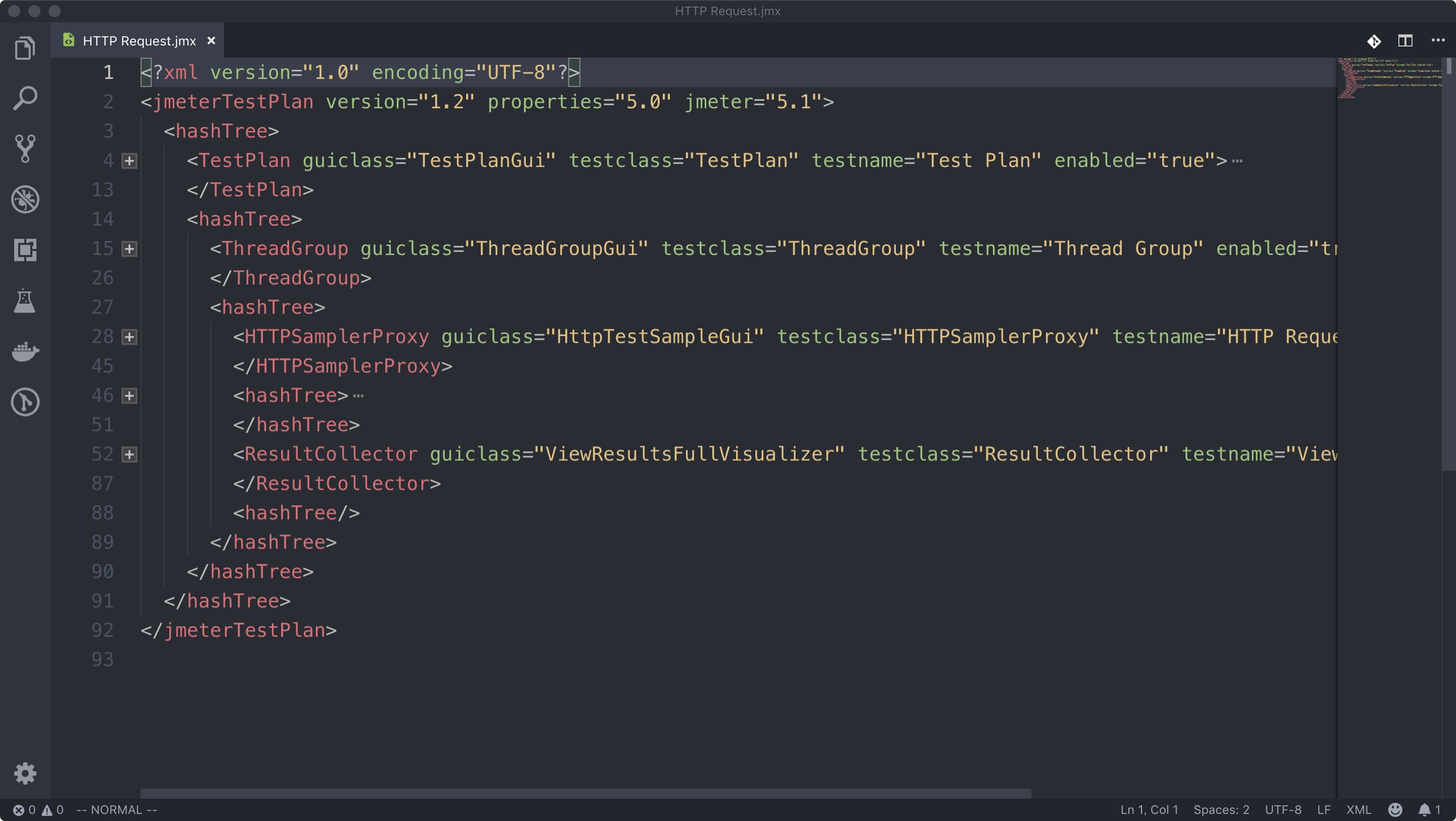
由以上的结构可知,每一层都只有2个类型的节点:
- Object 节点 - 代表一个 Test Component
- HashTree - 一个HashTree 的子节点
hashtree定义:
public class HashTree implements Serializable, Map<Object, HashTree>, Cloneable {
private static final long serialVersionUID = 240L;
// Used for the RuntimeException to short-circuit the traversal
private static final String FOUND = "found"; // $NON-NLS-1$
// N.B. The keys can be either JMeterTreeNode or TestElement
protected final Map<Object, HashTree> data; //
/**
* Creates an empty new HashTree.
*/
public HashTree() {
this(null, null);
}
.......
上述代码片段展示了 JMeter 中的 HashTree 类的定义。HashTree 类实现了 Serializable 接口和 Map 接口,并且可以进行克隆操作(Cloneable)。
HashTree 类的核心存储结构是一个名为 "data" 的受保护的最终类型的 Map,类型为 Map<Object, HashTree>。这个 Map 用于存储测试计划元素及其对应的 HashTree。
在 JMeter 中,HashTree 被用作测试计划元素的容器,它通过实现 Map 接口提供了对外的读写能力。具体来说,HashTree 可以通过调用 put 方法来添加键值对,其中键可以是 JMeterTreeNode 或 TestElement 类型的对象,值是对应的 HashTree。
通过调试可以确认,ListedHashTree 在内存中的结构就是 jmx 文件的映射。ListedHashTree 是 HashTree 的子类,实际上它使用了 ListedHashMap 数据结构,类似于 LinkedHashMap。ListedHashTree 保持了元素的添加顺序,并提供了方便的方法来遍历和访问元素。
综上所述,HashTree 是 JMeter 中用于存储测试计划元素的数据结构,它使用一个 Map 对象来实现存储和访问的功能。ListedHashTree 是 HashTree 的子类,使用了 ListedHashMap 来保持元素的顺序。这样的设计使得 HashTree 可以方便地映射和操作 JMX 文件中的测试计划元素。
HashTree 遍历获取元素过程:
在 JMeter 中,HashTree 使用了访问者模式来遍历数据节点。这是因为在测试执行过程中,JMeter 的 Engine 经常需要访问 JMX 文件中特定节点和子节点的数据。将这些访问方法放在 HashTree 本身会导致耦合度过高,不利于扩展和灵活性。通过使用访问者模式,可以解耦数据结构与操作,并提供更好的扩展性。
具体来说,访问者模式包含以下几个角色:
-
访问者(Visitor):定义了要对数据结构中的元素执行的操作接口。在 JMeter 中,访问者是一个接口,定义了可以在 HashTree 中访问不同类型的节点的方法。
-
具体访问者(Concrete Visitor):实现了访问者接口,提供了具体的操作实现。在 JMeter 中,具体访问者是 Engine,它实现了访问者接口,定义了在测试执行过程中对 HashTree 节点的具体访问操作。
-
数据结构(Element):定义了数据结构的接口,允许访问者访问它的元素。在 JMeter 中,数据结构是 HashTree,它实现了 Element 接口,允许访问者访问其中的节点。
-
具体数据结构(Concrete Element):实现了数据结构接口,提供了具体的数据结构实现。在 JMeter 中,具体数据结构是 HashTree 中的节点,例如 JMeterTreeNode 或 TestElement。
在 JMeter 中,Engine 作为具体访问者,通过访问者模式可以在测试执行过程中遍历 HashTree 中的节点和子节点。这样的设计提供了更好的扩展性,允许在不修改 HashTree 的情况下定义新的操作,并且可以根据需要将这些操作应用于 HashTree 中的元素。
遍历过程依赖的两个核心类:
/**
* Allows any implementation of the HashTreeTraverser interface to easily
* traverse (depth-first) all the nodes of the HashTree. The Traverser
* implementation will be given notification of each node visited.
*
* @see HashTreeTraverser
* @param visitor
* the visitor that wants to traverse the tree
*/
public void traverse(HashTreeTraverser visitor) {
for (Object item : list()) {
visitor.addNode(item, getTree(item));
getTree(item).traverseInto(visitor);
}
}
/**
* The recursive method that accomplishes the tree-traversal and performs
* the callbacks to the HashTreeTraverser.
*
* 完成树遍历和执行的递归方法对HashTreeTraverser的回调。使用深度优先遍历hashTree
*
* @param visitor
* the {@link HashTreeTraverser} to be notified
*/
private void traverseInto(HashTreeTraverser visitor) {
if (list().isEmpty()) {
visitor.processPath();
} else {
for (Object item : list()) {
final HashTree treeItem = getTree(item);
visitor.addNode(item, treeItem);
treeItem.traverseInto(visitor);
}
}
visitor.subtractNode();
}
在 JMeter 中,HashTreeTraverser 类是用于遍历 HashTree 的工具类,它提供了一种简单的方式来访问和处理 HashTree 中的节点和子节点。它的主要作用是封装了 HashTree 的遍历逻辑,使得遍历过程更加便捷和灵活。
以下是 HashTreeTraverser 类的关键方法和作用:
-
traverse(HashTree tree, HashTreeVisitor visitor)方法:该方法用于遍历 HashTree,并调用访问者的相应方法进行访问。它接受两个参数,tree表示要遍历的 HashTree 对象,visitor表示实现了 HashTreeVisitor 接口的访问者对象。 -
traverseIntoSubTree(Object key, HashTree tree, HashTreeVisitor visitor)方法:该方法用于遍历指定节点的子树,并调用访问者的相应方法进行访问。它接受三个参数,key表示节点的标识键,tree表示节点的子树 HashTree,visitor表示访问者对象。 -
traverseCollections(Collection<?> collection, HashTreeVisitor visitor)方法:该方法用于遍历集合对象,并调用访问者的相应方法进行访问。它接受两个参数,collection表示要遍历的集合对象,visitor表示访问者对象。
通过使用 HashTreeTraverser 类,可以更方便地遍历 HashTree 中的节点和子节点,并在访问者的方法中执行相应的操作。它封装了遍历的细节,使得访问者可以专注于实际的访问操作,而不需要关注遍历的具体实现。
public class SearchByClass<T> implements HashTreeTraverser {
private final List<T> objectsOfClass = new LinkedList<>();
private final Map<Object, ListedHashTree> subTrees = new HashMap<>();
private final Class<T> searchClass;
/**
* Creates an instance of SearchByClass, and sets the Class to be searched
* for.
*
* @param searchClass
* class to be searched for
*/
public SearchByClass(Class<T> searchClass) {
this.searchClass = searchClass;
}
/**
* After traversing the HashTree, call this method to get a collection of
* the nodes that were found.
*
* @return Collection All found nodes of the requested type
*/
public Collection<T> getSearchResults() { // TODO specify collection type without breaking callers
return objectsOfClass;
}
/**
* Given a specific found node, this method will return the sub tree of that
* node.
*
* @param root
* the node for which the sub tree is requested
* @return HashTree
*/
public HashTree getSubTree(Object root) {
return subTrees.get(root);
}
/** {@inheritDoc} */
@SuppressWarnings("unchecked")
@Override
public void addNode(Object node, HashTree subTree) { // 某一层HashTre 的数据访问
if (searchClass.isAssignableFrom(node.getClass())) {
objectsOfClass.add((T) node);
ListedHashTree tree = new ListedHashTree(node);
tree.set(node, subTree);
subTrees.put(node, tree);
}
}
/** {@inheritDoc} */
@Override
public void subtractNode() {
}
/** {@inheritDoc} */
@Override
public void processPath() {
}
}
在 JMeter 中,SearchByClass 类是一个实现了 HashTreeVisitor 接口的辅助类,用于在 HashTree 中搜索指定类型的元素。它提供了一种便捷的方式来遍历 HashTree,并将符合指定类型的元素保存起来。
以下是 SearchByClass 类的关键方法和作用:
-
构造函数
SearchByClass(Class<?> searchClass):该构造函数用于创建 SearchByClass 对象,并指定要搜索的目标元素类型。参数 searchClass表示要搜索的元素类型,它是一个 Class 对象。 -
addNode()方法的作用是在遍历 HashTree 的过程中,判断节点的类型是否与指定的目标类型兼容。如果兼容,将该节点添加到结果列表中,并创建一个新的 ListedHashTree 对象,将该节点作为根节点,并将其对应的子树添加到新创建的 ListedHashTree 中。最后,将新创建的 ListedHashTree 对象以节点为键,添加到 subTrees Map 中。 -
getSearchResults()方法:该方法用于获取搜索结果,即符合指定类型的元素列表。它返回一个 List 对象,其中包含了搜索结果。
通过使用 SearchByClass 类,可以方便地在 HashTree 中搜索指定类型的元素,并将符合条件的元素保存起来,以便后续使用。
使用例子:
SearchByClass searchByClass = new SearchByClass(TestPlan.class); hashTree.traverse(searchByClass); Object[] searchResults = searchByClass.getSearchResults().toArray();
创建一个实现了 HashTreeVisitor 接口的 SearchByClass 对象,用于指定要访问的元素类型。假设我们要访问的元素类型是 TestPlan.class,接下来,调用 HashTree 的 traverse() 方法,
将 SearchByClass 对象传递给它,以进行元素的访问和遍历,最后通过调用 searchByClass.getSearchResults().toArray() 来获取访问结果。这将返回一个数组,其中包含符合指
定元素类型的所有元素。
hashtree常用操作方法:
-
add(Object key, Object value):将一个键值对添加到 HashTree 中。键通常是元素对象,而值可以是另一个 HashTree 或其他对象。 -
put(Object key, Object value):与add()方法类似,将一个键值对添加到 HashTree 中。不同之处在于,如果键已经存在于 HashTree 中,则会用新值替换旧值, -
remove(Object key):从 HashTree 中删除指定的键及其关联的值。 -
get(Object key):根据键获取与之关联的值。 -
containsKey(Object key):检查 HashTree 中是否包含指定的键。 -
containsValue(Object value):检查 HashTree 中是否包含指定的值。 -
keySet():返回 HashTree 中所有键的集合。 -
values():返回 HashTree 中所有值的集合。 -
size():返回 HashTree 中键值对的数量。 -
isEmpty():检查 HashTree 是否为空。 -
clear():清空 HashTree,移除所有的键值对。 -
entrySet():返回 HashTree 中所有键值对的集合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号