

函数递归调用栈process
ret2text
n步过
s步进
EIP所指的位置即为当前程序运行的位置
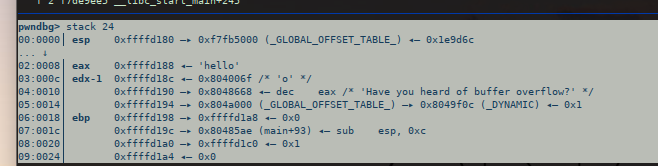
gdb的栈地址顺序上高下底
s起始地址与ebp为0x18-0x08=0x10=16*b'A'
整数打包为字节
shellcode
我们现在做的很多题目,都是堆栈不可执行,如果要使堆栈可执行,就要用到修改内存属性的函数,这属于比较高级的利用方式,所以我们很少用到shellcode,但是我们还是要了解shellcode的使用。
比如说,堆栈可执行(或者通过修改内存属性,使堆栈可执行,这时候我们就可以将shellcode放入栈中,然后将返回地址指向shellcode,我们就能顺利拿到shell。
shellcode还有很多高级用法,比如说字节限制,变形,绕过检测等等
攻击方式
1.向栈缓冲区注入
2.向bss缓冲区注入shellcode,bss存放全局变量
3.向堆缓存区注入

编译时可自行关闭保护机制


ASLR 每次加载程序地址都不固定
生成shellcode
context.arch="amd64" #指定环境amd64
print(shellcraft.amd64.sh())#生成64位的shell汇编代码
print(asm(shellcraft.sh()))
注意:1.若不指定则默认架构为32位 2. ("A" * 68).encode()等价于 b'A'*68
PIE会打乱bss
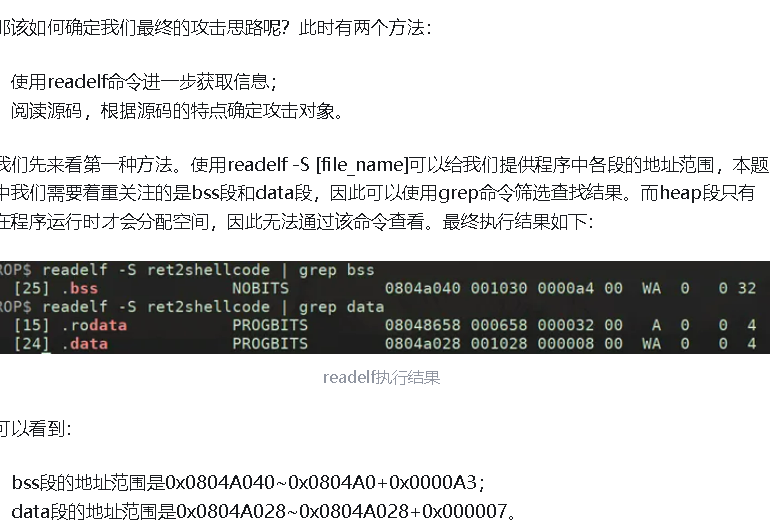
字长
递归函数调用栈:
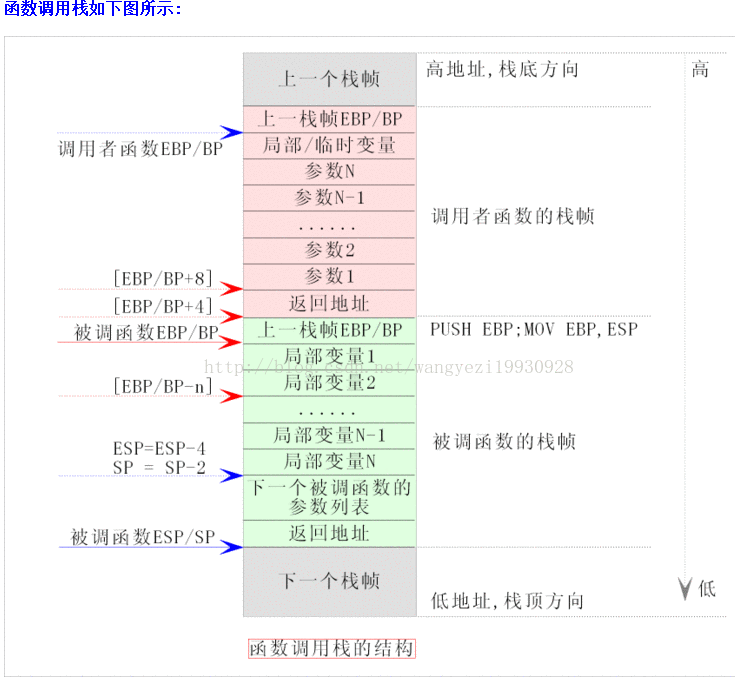
过程
调用
1,caller先压函数参数从右到左的顺序依次压入(参数一,二对应由高到低)
2,caller使用call指令调用callee(操作隐含在call指令中),然后将call指令下一条指令地址压入栈return address.
3.callee会先保存caller即父函数的ebp即(push ebp),然后再保存caller的esp即(mov ebp,esp)
4,再存callee的局部变量(先定义的变量先入栈)
返回
1,return前,会进行leave指令操作即2步(1)callee的esp会移动到callee的ebp,(2)再弹出ebp即(pop ebp),此时ebp的值是caller的ebp,caller的ebp值又回到ebp寄存器 ,同时esp指向return address
2.正式ret执行指令,callee的返回地址弹出到eip寄存器,此时便eip指向了caller的执行处
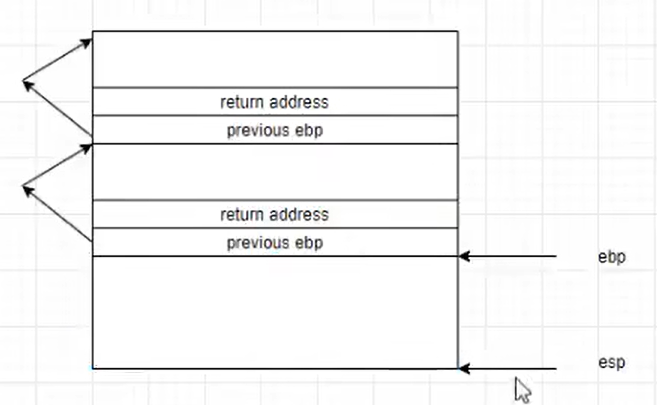
结论:
调用
ebp原本指向父函数的ebp
字后ebp有重要标记作用
ebp+4处值为callee的返回地址
ebp+8处值为传给calee的第一个参数
ebp-4为calee内的第一个局部变量

1、大端模式:高字节保存在内存的低地址
2、小端模式:高字节保存在内存的高地址
举例:
var = 0x11223344,对于这个变量的最高字节为0x11,最低字节为0x44
(1)大端模式存储(存储地址为16位)
地址 数据
0x0004(高地址) 0x44
0x0003 0x33
0x0002 0x22
0x0001(低地址) 0x11
(2)小端模式存储(存储地址为16位)
地址 数据
0x0004(高地址) 0x11
0x0003 0x22
0x0002 0x33
0x0001(低地址) 0x44
如何记忆?
自大的人眼高手低--其中,自大代表大端序,眼高代表高地址,手低代表低字节
strncpy

