

pwntool类型转换
pwntools:类型转换
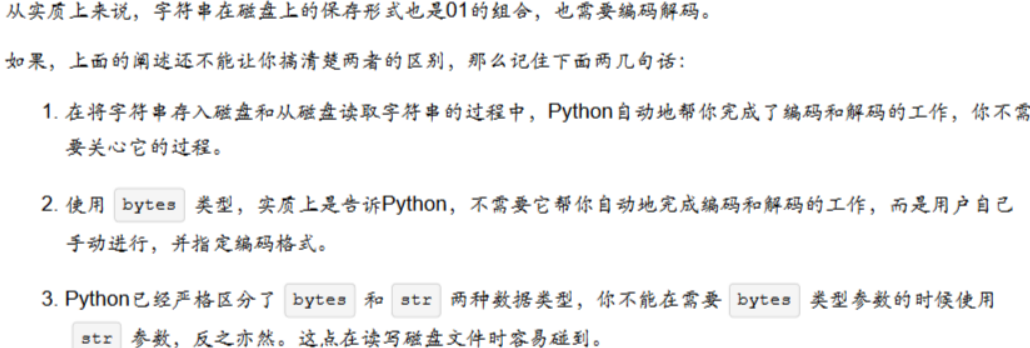
编码是什么?编码就是把一个字符用一个二进制来表示。
以ASCII编码为例,它规定1个字节8个比特位代表1个字符的编码,也就是"00000000"这么宽,一个一个字节的解读。例如:01000001表示大写字母A,有时我们会“偷懒"的用65这个十进制来表示A在ASCII中的编码。8个比特位,可以没有重复的最多表示2的8次方(255)个字符。
bytes和str区别
回到bytes和str的身上。bytes是一种比特流,它的存在形式是01010001110这种。计算机里都是0101串,怎样显示给人看,则需解码,但因编码方式不同,对它解读也很不同。
如下用python处理编码解码问题
#字符串(str) 👉 字节流(bytes)
encoded_str=bytes('中国', encoding="utf-8")
#b'\xe4\xb8\xad\xe5\x9b\xbd'
#解释b'\xe4\xb8\xad\xe5\x9b\xbd'这种形式,开头的表示这是一个bytes类型。Xe4是十六进制的示方式,它占用1个字节的长度,因此”中文“被编码成utf-8后,我们可以数得出一共用了6个字节,每个
or
encoded_str=str.encode("utf-8")
#字节流(bytes) 👉 字符串(str)
decoded_str=bytes(encoded_str, encoding="utf-8")
#or
decoded_str=encoded_str.decode('utf-8')
注意:
1.字节流不支持编码(encode) , 字符串不支持解码(decode)
2.字节流数据不支持str函数的使用如split()等
总结
pwntools常用转换
hex
hex(x)
x -- 10进制整数
返回16进制数,以字符串形式表示。
p32、p64(打包成服务器端的数据)
p32(x)
x-- 一个整型数据
返回byte型。
u32、u64(解包)
u32(x)
x-- byte型
返回整型。
int类型转换
int(a,base=x)
a-- 可以是byte也可以是str型
x是a本身的的进制。
返回10进制数,整型。
你可能有疑惑了,为什么byte型str型不是整数,却还有进制?
借鉴16进制: A表示10,B–1,C–12,D–13,E–14,F–15
int('A',base=9)#错
int('A',base=11)#对
send、sendline、recv
在pwn中,recv和send、sendline都是使用的byte型。
也就是说,我们在接收时,收到的是byte型,发送时,发送的是byte型。
from pwn import *
a='0x80489632'
print(type(a))#str
a1=int(a,16)
print(a1)
print(type(a1))#int
print(hex(a1))
print(type(hex(a1)))#str
print(p32(a1))
print(type(p32(a1)))#byte
'''
a2=u32(a)
print(a2)
print(type(a2))#int
'''
b=b'0x8048000'
print(type(b))#byte
b1=int(b,16)
print(b1)
print(type(b1))#int
print(hex(b1))
print(type(hex(b1)))#str
print(p32(b1))
print(type(p32(b1)))#byte
b=b'\xb0\x9a\t\x86\xe8\x7f\x00\x00'
'''
鉴于能够执行u32、u64的byte型数据是有要求的,我上面写的那个byte型数据b不符合要求,所以我换了一个b,只要能明白这些东西的类型转换就行,不要太纠结
'''
b2=u64(b)
print(b2)
print(type(b2))#int
字符串割片
bytes=b'The content of the address : 0xf7db9cd0\nLeave some message for me :'
#提取地址值
print(bytes.decode('utf-8').split("\n")[0][-10::])

