
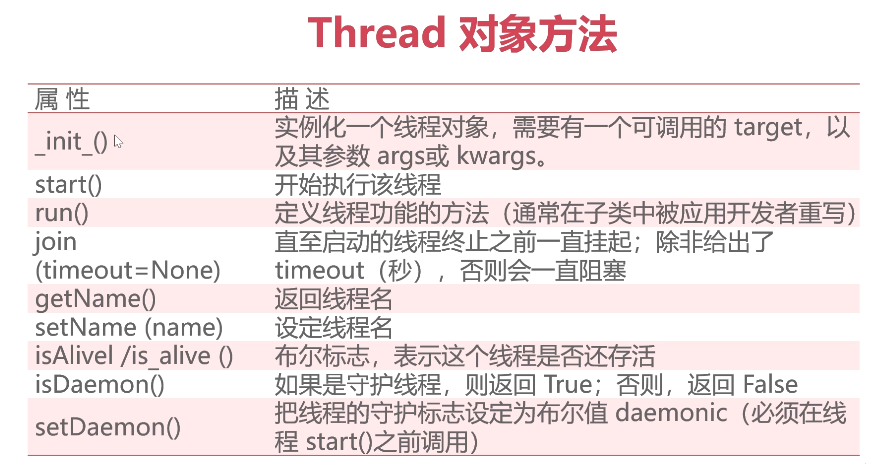
python16线程




python对于I/O密集型应用比较好,具体根据是什么类型应用来查看
对于cpu密集型应用可以借助python的一些扩展去实现


thread模块是比较早期的模块,thresding是比较新的模块,对thread模块进行了新的封装,



import threading def loop(): """新线程执行的代码""" loop_now_thread = threading.current_thread() print("loop现在的线程是{}".format(loop_now_thread)) n = 0 while n <5: print(n) n += 1 def use_thread(): """使用线程来实现""" #当前正在执行的线程名称 now_thread = threading.current_thread() print("现在的线程是{}".format(now_thread)) #设置线程 t = threading.Thread(target=loop,name="loop_thread") t.start() #挂起线程 t.join() if __name__ == "__main__": use_thread() 结果: 现在的线程是<_MainThread(MainThread, started 15572)> loop现在的线程是<Thread(loop_thread, started 3980)> 0 1 2 3 4
用类来实现:
import threading import time class LoopThrea(threading.Thread): n = 0 def run(self, n=None): while self.n < 5: print(self.n) now_thread = threading.current_thread() print("现在的线程是{}".format(now_thread)) time.sleep(1) self.n += 1 if __name__ == "__main__": t = LoopThrea(name = "quanzhiqiang_loop") t.start() t.join() 结果; 0 现在的线程是<LoopThrea(quanzhiqiang_loop, started 16708)> 1 现在的线程是<LoopThrea(quanzhiqiang_loop, started 16708)> 2 现在的线程是<LoopThrea(quanzhiqiang_loop, started 16708)> 3 现在的线程是<LoopThrea(quanzhiqiang_loop, started 16708)> 4 现在的线程是<LoopThrea(quanzhiqiang_loop, started 16708)>
import threading import time balance = 0 def change_it(n): global balance balance = balance +n time.sleep(2) balance = balance -n print("##################{0}#".format(balance)) time.sleep(1) class ChageBlance(threading.Thread): def __init__(self, num, *args, **kwargs): super().__init__(*args, **kwargs) self.num = num def run(self): for i in range(100000): change_it(self.num) if __name__ == "__main__": t1 = ChageBlance(5) t2 = ChageBlance(8) t1.start() t2.start() t1.join() t2.join() print("aaaa{0}".format(balance))
结果:有时候不为零 ##################5###################0# ##################8# ##################0# ##################5###################0# ##################5###################0#

import threading import time my_lock = threading.Lock() your_lock = threading.Lock() balance = 0 def change_it(n): global balance try: # 添加锁 my_lock.acquire() #my_lock.acquire()如果再加如一个锁,就会出现死锁 balance = balance +n time.sleep(2) balance = balance -n print("##################{0}#".format(balance)) #释放锁 finally: my_lock.release() time.sleep(1) class ChageBlance(threading.Thread): def __init__(self, num, *args, **kwargs): super().__init__(*args, **kwargs) self.num = num def run(self): for i in range(100000): change_it(self.num) if __name__ == "__main__": t1 = ChageBlance(5) t2 = ChageBlance(8) t1.start() t2.start() t1.join() t2.join() print("aaaa{0}".format(balance)) 结果; ##################0# ##################0# ##################0# ##################0# ##################0# ##################0#
因为都是零,这是每个线程都加了锁,防止被修改
Rlock,在一个线程里面可以多次进行自锁
import threading import time my_lock = threading.Lock() your_lock = threading.RLock() balance = 0 def change_it(n): global balance try: # 添加锁 your_lock.acquire() your_lock.acquire() balance = balance +n time.sleep(2) balance = balance -n print("##################{0}#".format(balance)) #释放锁R finally: your_lock.release() your_lock.release() time.sleep(1) class ChageBlance(threading.Thread): def __init__(self, num, *args, **kwargs): super().__init__(*args, **kwargs) self.num = num def run(self): for i in range(100000): change_it(self.num) if __name__ == "__main__": t1 = ChageBlance(5) t2 = ChageBlance(8) t1.start() t2.start() t1.join() t2.join() print("aaaa{0}".format(balance)) 结果: ##################0# ##################0# ##################0# ##################0# ##################0#

利用线程池,减少创建线程和销毁线程所带来的系统性能消耗

另外i一个也是线程池,只不过更加厉害

import time import threading from concurrent.futures.thread import ThreadPoolExecutor from multiprocessing.dummy import Pool def run(n): time.sleep(2) print(threading.current_thread().name,n) def main(): t1 = time.time() for n in range(5): run(n) print(time.time() - t1) def main_use_thread(): ls = [] t1 = time.time() for count in range(10): for i in range(10): t = threading.Thread(target=run,args=(i,)) ls.append(t) t.start() for l in ls: l.join() print(time.time() - t1) def main_use_pool(): t1 = time.time() n_list = range(100) pool = Pool(10) pool.map(run,n_list) pool.close() pool.join() print(time.time() - t1) def main_use_thread(): t1 = time.time() n_list = range(100) with ThreadPoolExecutor(max_workers=10) as executor: executor.map(run,n_list) print(time.time() - t1) if __name__ == "__main__": #main() #下面的执行都是使用十个线程去处理的,效率比较高 #main_use_thread() #main_use_pool()这个24秒 main_use_thread()#这个20秒
map函数:
map是python内置函数,会根据提供的函数对指定的序列做映射。 map()函数的格式是: map(function,iterable,...) 第一个参数接受一个函数名,后面的参数接受一个或多个可迭代的序列,返回的是一个集合。 把函数依次作用在list中的每一个元素上,得到一个新的list并返回。注意,map不改变原list,而是返回一个新list。 通过map还可以实现类型转换 将元组转换为list: map(int,(1,2,3)) # 结果如下: [1,2,3] 将字符串转换为list: map(int,'1234') # 结果如下: [1,2,3,4] 提取字典中的key,并将结果放在一个list中: map(int,{1:2,2:3,3:4}) # 结果如下 [1,2,3]
