python5



t = ("a","b","c",1,2) print(t) print(t[2]) print(t[-1]) print(t[1:4]) print('b' in t) #元组创建后不可变 #写入数据的函数也不支持 #特殊情况,如果元组内持有列表,那么列表的内容是允许被修改的 t2 = (['a',199],['b',100]) print(t2[1]) t2[1][1] = 1 print(t2) #对于元组元素的修改都是不可以的 t3 = (1,2,3) + (4,5,6) print(t3) #如果元组只用一个元素时,必须在这个元素后增加逗号说明是一个元组 t4 = ('a')*9 t5 = ('a',)*9 print(t4) print(t5)
结果 ('a', 'b', 'c', 1, 2) c 2 ('b', 'c', 1) True ['b', 100] (['a', 199], ['b', 1]) (1, 2, 3, 4, 5, 6) aaaaaaaaa ('a', 'a', 'a', 'a', 'a', 'a', 'a', 'a', 'a')




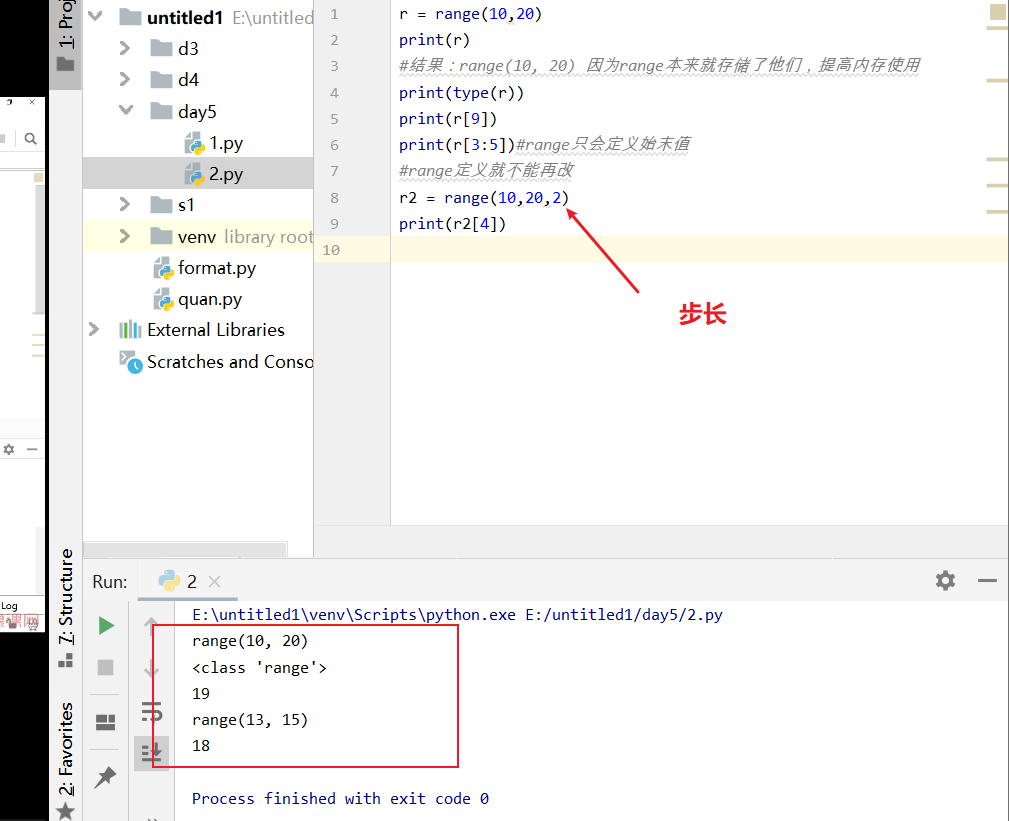

c = "abcdefg" for i in range(0,len(c)): letter = c[i] print(letter) #实现斐波那契数列, 1, 2, 3, 5, 8, 13, result = [] for i in range(0,20): if i == 0 or i ==1: result.append(1) else: result.append(result[i-2] + result[i-1]) print(result) #判断l质数 l = 776 is_prime = True for i in range(2,l): if 1 % i == 0: is_prime = False break if is_prime == True: print("{}是质素".format(l)) else: print("{} 不是质数".format(l))
结果 a b c d e f g [1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765] 776是质素

l1 = ['a','b','c'] t1 = ('d','e','f') s1 ='abc123' s2 = 'abc,123' r1 = range(1,4) l2 = list(t1) print(l2) #['d', 'e', 'f'] print(list(s1))#['a', 'b', 'c', '1', '2', '3'] print(s2.split(","))#['abc', '123'] print(list(r1))#[1, 2, 3] print(tuple(l1))#('a', 'b', 'c') print(tuple(s1))#('a', 'b', 'c', '1', '2', '3') print(tuple(s2.split(",")))#('abc', '123') #带有特殊符号的字符串是不能直接转换为元组 print(tuple(s2))#('a', 'b', 'c', ',', '1', '2', '3') print(tuple(r1))#(1, 2, 3) #str 用于将单个数据转换为字符串,join只能全部操作对象都是字符串 print(str(l1))#['a', 'b', 'c'] print("".join(l1))#abc print("|".join(t1))#d|e|f s3 = "" 包含数字的使用着这种 for i in r1 : s3 += str(i) print(s3)#123




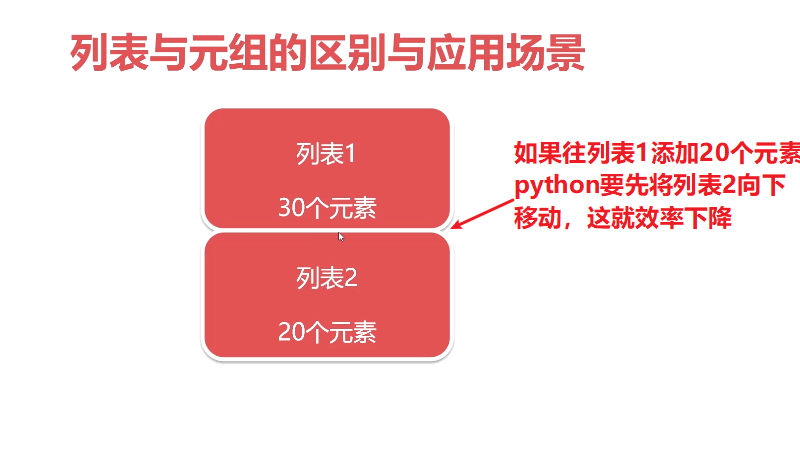
集合的读取和存储都是比较高效,但是就是浪费内存空间

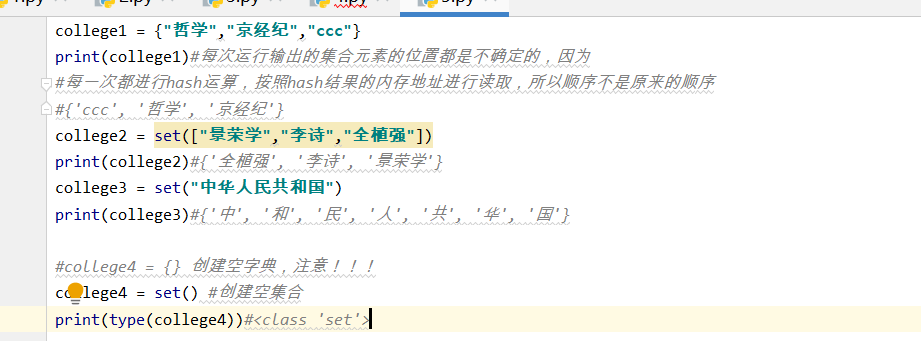

college1 = {"法学","经济学","教育学","哲学"}
college2 = {"金融学","哲学","经济学","历史学","文学"}
#A交B
#放回新的集合,两个集合都有的元素 #交集
c3 = college1.intersection(college2)
print(c3)#结果{'经济学', '哲学'}
college1.intersection_update(college2)#直接将结果跟新给college1
print(college1)#结果{'经济学', '哲学'}
#AUB
college1 = {"法学","经济学","教育学","哲学"}
college2 = {"金融学","哲学","经济学","历史学","文学"}
c4 = college1.union(college2) #并集,没有uptdate
print(c4)
#A - A交B
#差集,college1中有,college2中没有的元素
c5 = college1.difference(college2) #有update
print(c5)
#AUB - A交B
#两个集合各独自有的元素 #symmetric均衡的意思
c6 = college1.symmetric_difference(college2)
print(c6)
{'经济学', '哲学'}
{'经济学', '哲学'}
{'文学', '法学', '金融学', '历史学', '教育学', '经济学', '哲学'}
{'法学', '教育学'}
{'文学', '法学', '金融学', '历史学', '教育学'}
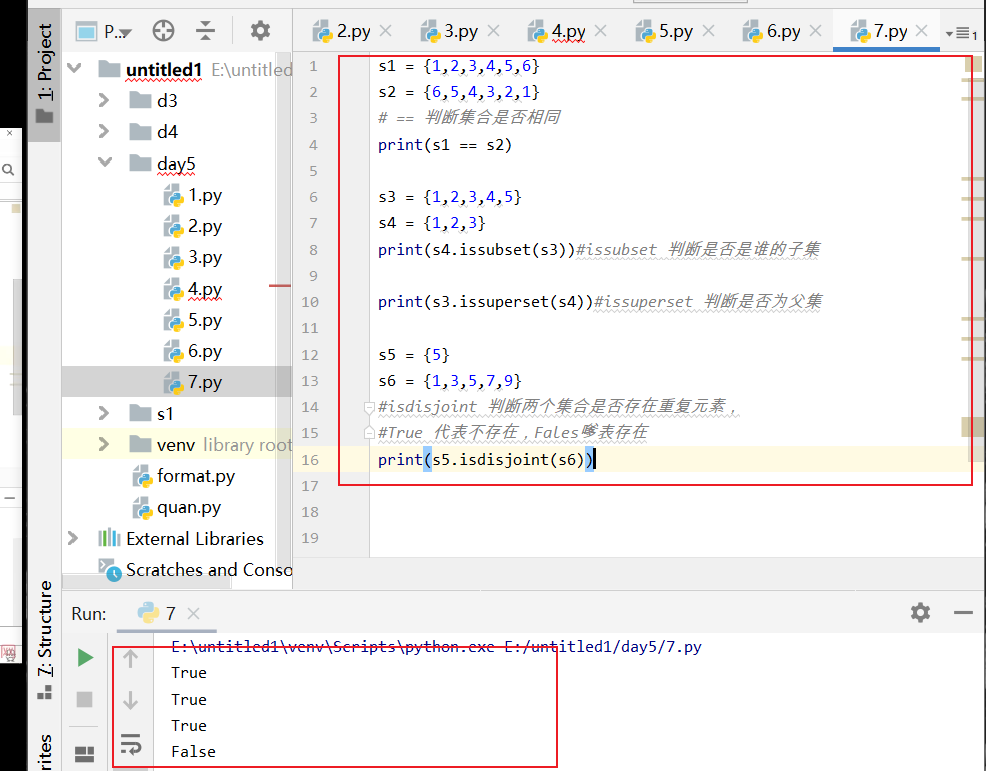
college1 = {"法学","经济学","教育学","哲学"}
for c in college1: #即使是遍历,输出的结果也和定义的不一样
print(c)
print("法学" in college1) #判断元素存在
#集合没有索引进行,不能进行数据的提取
#新增数据,add一次只能添加一个
college1.add("技术")
print(college1)#因为集合中不存在,添加!
college1.add("法学")
print(college1) #因为集合存在,而且元素不能重复,无添加!无报错
#update 一次性添加多个元素
college1.update(["发呕","测试"]) #括号里面可用是元组
print(college1)
#注意集合当中是不可以直接修改元素的,必须先删除后添加
college1.remove("发呕")
#remove 遇到不存在的元素,报错
college1.discard("发")
#discard 遇到不存在可用忽略报错
college1.add("拉肚")
print(college1)


#结构: #[被追加的数据 循环语句 循环或者判断语句] lst1 = [] for i in range(10,20): lst1.append(i*10) print(lst1) lst2 = [i*10 for i in range(10,20)] print(lst2) lst3 = [i*10 for i in range(10,20) if i%2 == 0] print(lst3) for i in range(10,20): if i % 2 == 0: lst3.append(i * 10) lst4 = [i*j for i in range(1,5) for j in range(1,5)] print(lst4) #字典生成式 lst5 = ["aaa","bbb","cccc"] dict1 = {i+1:lst5[i] for i in range(0,len(lst5))} print(dict1) #集合生成式 set1 = { i* j for i in range(1,4) for j in range(1,4) if i == j} print(set1) for i in range(1,4): for j in range(1,4): if j == i: set1.add(j * i)
结果 [100, 110, 120, 130, 140, 150, 160, 170, 180, 190] [100, 110, 120, 130, 140, 150, 160, 170, 180, 190] [100, 120, 140, 160, 180] [1, 2, 3, 4, 2, 4, 6, 8, 3, 6, 9, 12, 4, 8, 12, 16] {1: 'aaa', 2: 'bbb', 3: 'cccc'} {1, 4, 9}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号