面试集合
有个客户说访问不到你们的网站,但是你们自己测试内网和外网访问都没问题。你会怎么排查并解决客户的问题?
笔者回答:我们自己测了都没问题,只是这个客户访问有问题,那肯定是要先联系到这个客户,能远程最好,问一下客户的网络是不是正常的,访问其它的网站有没有问题(比如京东、百度什么的)。如果访问其它网站有问题,那叫客户解决本身网络问题。如果访问其它网站都没问题,用ping和nslookup解析一下我们的网站是不是正常的,让客户用IP来访问我们的网站是否可行,如果IP访问没问题,那就是客户的DNS服务器有问题或者DNS服务器解析不到我们的网站。还有一种可能就是跨运营商访问的问题,比如我们的服务器用的是北方联通、而客户用的是南方移动,就也有可能突然在某个时间段访问不到,这种情况在庞大的中国网络环境中经常发生(一般是靠CDN解决)。还有可能就是我们的网站没有SSL证书,在公网是使用的是http协议,这种情况有可能就是没有用https协议网站被运营商劫持了。
redhat 6.X版本系统 和 centos 7.X版本有啥区别?
笔者回答:桌面系统(6/GNOE2.x、7/GNOME3.x)、文件系统(6/ext4、7/xfs)、内核版本(6/2.6x、7/3.10x)、防火墙(6/iptables、7/firewalld)、默认数据库(6/mysql、7/mariadb)、启动服务(6/service启动、7/systemctl启动)、网卡(6/eth0、7/ens192)等。
你会用什么方法查看某个应用服务的流量使用情况?
笔者回答:如果是单一应用的服务器,只需要用iftop、sar等工具统计网卡流量就可以。如果服务器跑了多个应用,可以使用nethogs工具实现,它的特别之处在于可以显示每个进程的带宽占用情况,这样可以更直观获取网络使用情况
说一下你们公司怎么发版的(代码怎么发布的)?
笔者回答:我说什么来着,这个问题又问到了。发布:jenkins配置好代码路径(SVN或GIT),然后拉代码,打tag。需要编译就编译,编译之后推送到发布服务器(jenkins里面可以调脚本),然后从分发服务器往下分发到业务服务器上。
ansible你用过它的哪些模块,ansbile同时分发多台服务器的过程很慢(它是逐台分发的),你想过怎么解决吗?
笔者回答:用过ansible的(copy file yum ping command shell)等模块;ansible默认只会创建5个进程,所以一次任务只能同时控制5台机器执行.那如果你有大量的机器需要控制,或者你希望减少进程数,那你可以采取异步执行.ansible的模块可以把task放进后台,然后轮询它.这使得在一定进程数下能让大量需要的机器同时运作起来.
nginx有哪几种调度算法,解释一下ip hash和轮询有啥不一样?
笔者回答:常用的有3种调度算法(轮询、ip hash、权重)。
轮询:upstream按照轮询(默认)方式进行负载,每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。
ip hash:每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。
权重:指定轮询几率,权重(weight)和访问比率成正比,用于后端服务器性能不均的情况。
nginx你用到了哪些模块,在proxy模块中你配置过哪些参数?
笔者回答:用到过(负载均衡upstream、反向代理proxy_pass、location、rewrite等)。
proxy模块中配置过:proxy_set_header、proxy_connect_timeout、proxy_send_timeout、proxy_buffer_*
12、说一下iptables的原理,有哪些表、哪些链?怎么修改默认策略全部为DROP?
笔者回答:iptables是工作在TCP/IP的2、3、4层。你要说它的原理也不是几话能概括的,当主机收到一个数据包后,数据包先在内核空间中处理,若发现目的地址是自身,则传到用户空间中交给对应的应用程序处理,若发现目的不是自身,则会将包丢弃或进行转发。
4张表(raw表、mangle表、net表、filter表)
5条链(INPUT链、OUTPUT链、PORWARD链、PREROUTING链、POSTROUTING链)。
全部设置为DROP:
#iptables -P INPUT DROP
#iptables -P OUTPUT DROP
#iptables -P FORWARD DROP
小结:iptables远不止这几句话就能描述清楚的,也不是随便在网上趴些资料就能学好的,需要自己用起来,经过大量的实验和实战才能熟悉它,iptables真的很考验运维人员的技术水平,大家一定要用心学好这个iptables。
13、如何开启linux服务器路由转发功能?
笔者回答:echo "1" > /proc/sys/net/ipv4/ip_forward
14、nginx中rewrite有哪几个flag标志位(last、break、redirect、permanent),说一下都什么意思?
笔者回答:
- last : 相当于Apache的[L]标记,表示完成当前的rewrite规则
- break : 停止执行当前虚拟主机的后续rewrite指令集
- redirect : 返回302临时重定向,地址栏会显示跳转后的地址
- permanent : 返回301永久重定向,地址栏会显示跳转后的地址
301和302不能简单的只返回状态码,还必须有重定向的URL,这就是return指令无法返回301,302的原因了。这里 last 和 break 区别有点难以理解:
- last一般写在server和if中,而break一般使用在location中
- last不终止重写后的url匹配,即新的url会再从server走一遍匹配流程,而break终止重写后匹配
- break和last都能组织继续执行后面的rewrite指令
总结:关于nginx rewrite用法,笔者看到一篇文章总结的挺不错 ,可以参考一下 https://www.jianshu.com/p/a1fce9358d44
15、你在shell脚本中用过哪些语法,case语法会用到哪些地方?
笔者回答:一般会用到if语句、for语句、while语句、case语句以及function函数的定义;case语句为多选择语句,可以用case语句匹配一个值与一个模式,如果匹配成功,执行相匹配的命令。最典型的case语法会用到启动服务脚本的处理。
16、linux系统中你会用到什么命令查看硬件使用状态信息?
笔者回答:这个命令就很多了,比如:lscpu(查看cpu信息)、free -m(查看内存信息)、df -h(查看硬盘分区信息)、top(还可以动态查看cpu、内存使用情况的信息),/proc/目录下也可以查看很多硬件信息。
17、我要过滤一段文本(test.txt)中第二列的内容?如果这段文件有很多特殊符号,比如用:(冒号)怎么过滤它的第二段?如果我要过滤这段文本中,其中有一行只有7个符如何实现?
笔者回答: awk '{print $2}' tset.txt
awk -F':' '{print $2}' tset.txt
18、比如开发想找你查看tomcat日志,但是catalia.out特别大,你不可能用vi打开去看,你会怎么查看?如果你用 grep -i"error" 过滤只是包含error的行,我想同时过滤error上面和下面的行如何实现?
笔者回答:grep -i "error" catalia.out
grep -C 1 -i "error" catalia.out
参数-C:是匹配前后的行,后面1是匹配前后各1行
19、 怎么编写一个定时计划任务?里面用到的最小单位是什么?
笔者回答:crontab -e,最小单位是分钟
20、zabbix如何修改其中监控的一台服务器中内存阈值信息,比如正常内存使用到了80%报警,我想修改为60%报警?
笔者回答:正常来说,一般会把监控的服务器统一加入到一个模板中,修改模板的其是某一项的监控项参数和告警阈值后,加入模板中的所有主机都会同步。如果单独想修改其中某一台服务器内存告警阈值,需要进入这台主机,单独创建一个告警Triggers,关联这台主机监控内存的项,配置好告警的阈值为60%即可实现。其实,zabbix一切都为图形化操作,如果没有接触过zabbix的朋友,可能听起来不太清楚。
21、mysql主从复制原理说一下?
笔者回答:mysql支持三种复制类型(基于语句的复制、基于行的复制、混合类开进的复制)。
如果你记不住太多内容,可以简单说明一下原理:
(1) master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
(2) slave将master的binary log events拷贝到它的中继日志(relay log);
(3) slave重做中继日志中的事件,将改变反映它自己的数据。
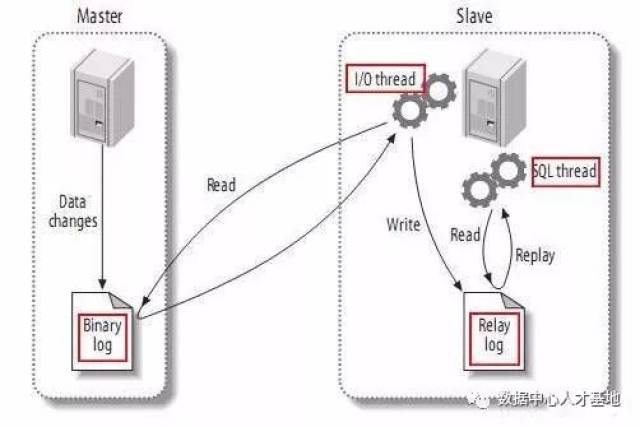
如果你能详细记住它的原理,可以这么回答:
该过程的第一部分就是master记录二进制日志。在每个事务更新数据完成之前,master在二日志记录这些改变。MySQL将事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。
下一步就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。
SQL slave thread(SQL从线程)处理该过程的最后一步。SQL线程从中继日志读取事件,并重放其中的事件而更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
22、用什么命令可以查看上一次服务器启动的时间、上一次谁登录过服务器?
笔者回答:w命令查看上次服务器启动时间。last命令 查看登录。
23、redis集群原理说一下,正常情况下mysql有多个库,redis也有多个库,我怎么进入redis集群中的第2个库?还有,我想查看以BOSS开头的值?redis持久化是如何实现(一种是RDS、一种是AOF),说一下他们有啥不一样?
笔者回答:这个redis原理的问题又问到了,看样子很多面试官都很关心这个redis,在上一篇文章笔者的一次面试也有这个面试问题。
【集群原理】:其实它的原理不是三两句话能说明白的,redis 3.0版本之前是不支持集群的,官方推荐最大的节点数量为1000,至少需要3(Master)+3(Slave)才能建立集群,是无中心的分布式存储架构,可以在多个节点之间进行数据共享,解决了Redis高可用、可扩展等问题。集群可以将数据自动切分(split)到多个节点,当集群中的某一个节点故障时,redis还可以继续处理客户端的请求。
【切库】:单机情况下用select 2可以切换第2个库,select 1可以切换第1个库。但是集群环境下不支持select。可参考https://yq.aliyun.com/articles/69349
【redis持久化】:持久化通俗来讲就是将内存中的数据写入硬盘中,redis提供了两种持久化的功能(RDB、AOF),默认使用RDB的方式。
RDB:全量写入持久化,而RDB持久化也分两种(SAVE、BGSAVE)。
SAVE是阻塞式的RDB持久化,当执行这个命令时redis的主进程把内存里的数据库状态写入到RDB文件(即上面的dump.rdb)中,直到该文件创建完毕的这段时间内redis将不能处理任何命令请求。
BGSAVE属于非阻塞式的持久化,它会创建一个子进程专门去把内存中的数据库状态写入RDB文件里,同时主进程还可以处理来自客户端的命令请求。但子进程基本是复制的父进程,这等于两个相同大小的redis进程在系统上运行,会造成内存使用率的大幅增加。
AOF:与RDB的保存整个redis数据库状态不同,AOF的持久化是通过命令追加、文件写入和文件同步三个步骤实现的。AOF是通过保存对redis服务端的写命令(如set、sadd、rpush)来记录数据库状态的,即保存你对redis数据库的写操作。
为了大家能够更好的理解redis持久化,笔者建议大家可以看下这两篇文章会比较好理解:
https://www.cnblogs.com/Fairy-02-11/p/6182478.html
http://blog.csdn.net/mishifangxiangdefeng/article/details/48977269
24、你在工作的过程中,遇到过你映像最深的是什么故障问题,你又是如何解决?
笔者回答:这个问题主要也是考你排查故障的思路及用到的相关命令工具,其每个人在工作中都会遇到各种各样的问题(不管是网络问题、应用配置问题、还是APP打开慢/网站打开慢)等等。你只要记住一个你映像最为深刻、最为典型的故障就行。笔者也遇到过各种问题,我在这里就是写出来,怕误导了大家。
25、在linux服务器上,不管是用rz -y命令还是tftp工具上传,我把本地的一个文件上传到服务器完成后,服务器上还是什么都没有,这有可能是什么问题?
笔者回答:根据这种现象有可能是:服务器磁盘满了;文件格式破坏了;或者你用的是普通用户上传,正好上传的目录没有权限;还有可能就是你上传的文件大小超出了该目录空间的范围。
26、你在工作中都写过什么脚本?
笔者回答:这个问题的回答别把话说得太大了,要结合实际情况来回答。写过mysql、redis、mongodb等数据库备份的脚本;服务器文件备份的脚本;日常代码发布的脚本;之前用nagios的时候写过一些nagios插件的脚本。
27、rsync+inotify是实现文件实时同步的,加什么参数才能实现实时同步,--delete参数又是什么意思?
笔者回答:rsync是远程同步工具、inotify是一种强大的异步文件系统系统监控机制。通过inotifywait 中的-m参数可以实现“始终保持事件监听状态”。rsync中的-delete参数是指“ 删除那些DST中SRC没有的文件”。
28、我想查看access.log中哪个IP访问最多?
笔者回答:awk '{print $1}' access.log| sort | uniq -c |sort -rn -k 1 | head -1
上面的具体参数如果有不知道的,大家可以自行百度一下,这里不说参数这么细节的问题
29、在linux系统中,一般都会有swap内存,你觉得使用swap内存有什么好处,在什么情况下swap内存才会被使用?你觉得在生产环境中要不要用swap内存?
笔者回答:好处:在内存不够用的时候,将部分内存上的数据交换到swap空间上,以便让系统不会因为内存不够用而导致oom或者更致命的情况出现。
什么情况下会用swap:当系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间被临时保存到swap空间中,等到那些程序要运行时,再从swap中恢复保存的数据到内存中。这样,系统总是在物理内存不够时,才进行swap交换。
30、怎么查看两台服务器之间的网络是不是正常的,服务器是禁ping的?
笔者回答:不能用ping,那可以用telnet对方服务器的端口、或者互相访问对方打开的服务。其它的测试方法笔者也没想到,要是哪位朋友有好的方法不访在下面留言讨论。
31、比如我访问百度网站,有什么方法可以跟踪经过了哪些网络节点?
笔者回答:这个太简单了吧,干运维必备的网络排查技能。用tracert命令就可以跟踪,主要是查询本机到另一个主机经过的路由跳数及数据延迟情况。然后你也可以把具体跟踪后输出的信息也说出来,你能说出来都是为你加分的。
32、如果你们公司的网站访问很慢,你会如何排查?
笔者回答:看到没有,又问到了这个问题,笔者在上一篇文章 2017年2月14号的面试中面试官也问到同样的问题。其实这种问题都没有具体答案,只是看你回答的内容与面试官契合度有多高,能不能说到他想要的点上,主要是看你排查问题的思路。我是这么说的:问清楚反应的人哪个服务应用或者页面调取哪个接口慢,叫他把页面或相关的URL发给你,首先,最直观的分析就是用浏览器按F12,看下是哪一块的内容过慢(DNS解析、网络加载、大图片、还是某个文件内容等),如果有,就对症下药去解决(图片慢就优化图片、网络慢就查看内网情况等)。其次,看后端服务的日志,其实大多数的问题看相关日志是最有效分析,最好用tail -f 跟踪一下日志,当然你也要点击测试来访问接口日志才会打出来。最后,排除sql,,找到sql去mysql执行一下,看看时间是否很久,如果很久,就要优化SQL问题了,expain一下SQL看看索引情况啥的,针对性优化。数据量太大的能分表就分表,能分库就分库。如果SQL没啥问题,那可能就是写的逻辑代码的问题了,一行行审代码,找到耗时的地方改造,优化逻辑。
33、我需要查看某个时间段的日志(比如access.log日志),如何实现?
笔者回答:方法有很多种,比如我要看查的时间是2018年1月9号--1月10号的日志吧。
比如可以用sed命令,格式为:sed -n '/起始时间/,/结束时间/p' 日志文件,如下:
sed -n '/09/Jan/2018/,/10/Jan/2018/p' access.log
比如可以用grep,格式为:grep -E '起始时间|结束时间' 日志文件,如下:
grep -E '09/Jan/2018|10/Jan/2018' access.log
当然,你还可以结合cat、grep 、awk这些命令一起来使用都行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号