机器学习算法 —— kNN(k-近邻算法)
算法概述
通过测量不同特征值之间的距离进行 [分类]
- 优点:精度高、对异常值不敏感、无数据输入假定。
- 缺点:计算复杂度高、空间复杂度高。
- 适用数据范围: 数值型 和 标称型 。
算法流程
- 数据
- 样本数据(多维多行数据 + 标签)
- 预测数据(多维一行数据)
-
比较预测数据与样本数据的距离
- 欧氏距离
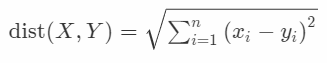
- 欧氏距离
-
将样本数据按照距离从小到大排序
-
选取前 k 个样本数据,取出现次数最多的样本标签作为预测数据的分类标签
代码示例
import collections
import numpy as np
def culEuDistance(x1, x2):
"""
计算欧氏距离
"""
return ((x1 - x2)**2).sum()**0.5
def knn(X, dataSet, labels, k):
"""
比较预测数据与历史数据集的欧氏距离,选距离最小的k个历史数据中最多的分类。
:param X: 需要预测的数据特征
:param dataSet: 历史数据的数据特征
:param labels: 与dataSet对应的标签
:param k: 前k个
:return: label标签
"""
if isinstance(dataSet, list):
dataSet = np.array(dataSet)
rowNum = dataSet.shape[0]
X = np.tile(X,(rowNum,1))
distances = np.empty(rowNum)
for row in range(rowNum):
distances[row] = culEuDistance(X[row], dataSet[row])
sortedIdx = distances.argsort()
candidates = []
for i in range(k):
candidates.append(labels[sortedIdx[i]])
return collections.Counter(candidates).most_common(1)[0][0]
if __name__ == "__main__":
# print(culEuDistance(np.array([3,4]), np.array([2,1])))
X = [101,20]
dataSet = [[3,104],[2,100],[1,81],[101,10],[99,5],[98,2]]
labels = ['爱情片','爱情片','爱情片','动作片','动作片','动作片']
print(knn(X,dataSet,labels,k=3))
# 动作片

