深度学习Deep Learning Tutorial(李宏毅)————————自学笔记
自己接触的一些东西不够深入,整个体系的结构也不够清晰,所以回头从一些入门经典资料进行重新梳理。以下内容图片均来自Deep learning tutorial(李宏毅),其他内容均为本人自己的理解而做的一些记录,不代表原文观点,不保证准确性。
一、深度学习介绍
1.1 深度学习的介绍
先来看看机器学习是什么,可以看做寻找一个能够得到我们期望解的函数。通过训练数据,我们可以找到包含若干函数的集合,在其中找一个对问题有良好响应的函数(对给定的输入,都能得到一个正确的解)。
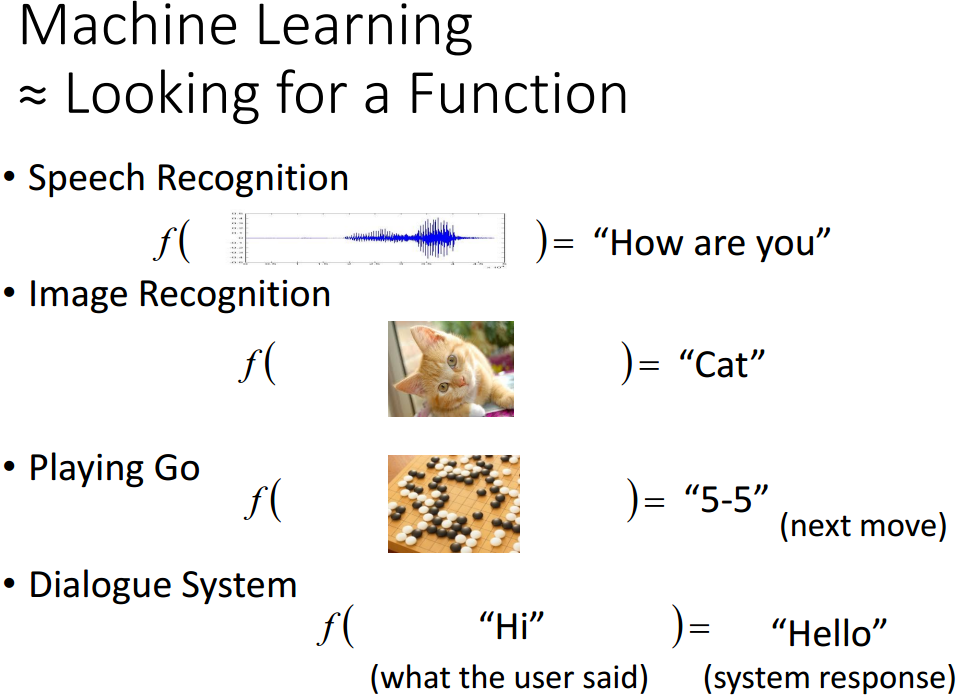
有监督的学习指训练的时候对每一个输入,我们都已知其应该的输出(标签),我们的目的是学到一个函数,能够满足所有训练集的输入,都会得到其对应正确的输出。这么说吧,我们有一组(x,y),我们要找到一个函数,对应每一个x,都会得到其对应的y值。
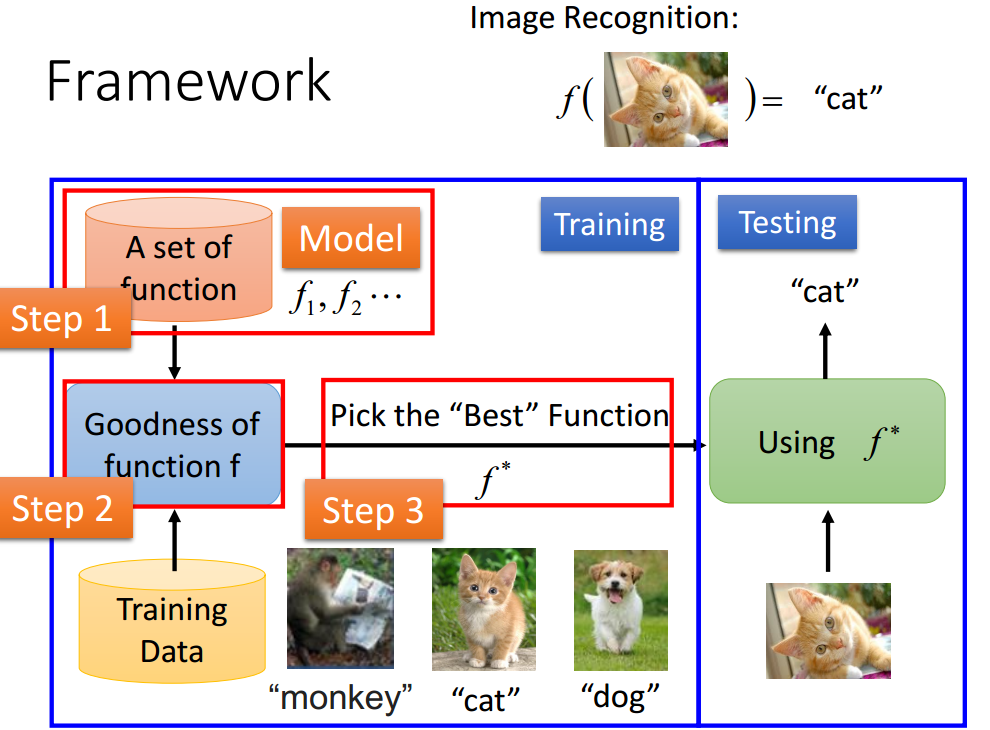
步骤:
- 定义一个函数的集合————-对应神经网络
给出一个参数,来定义一个函数;对应给出一个网路结构,定义一个函数集合(权重和偏置是网络的参数)。
单个神经元
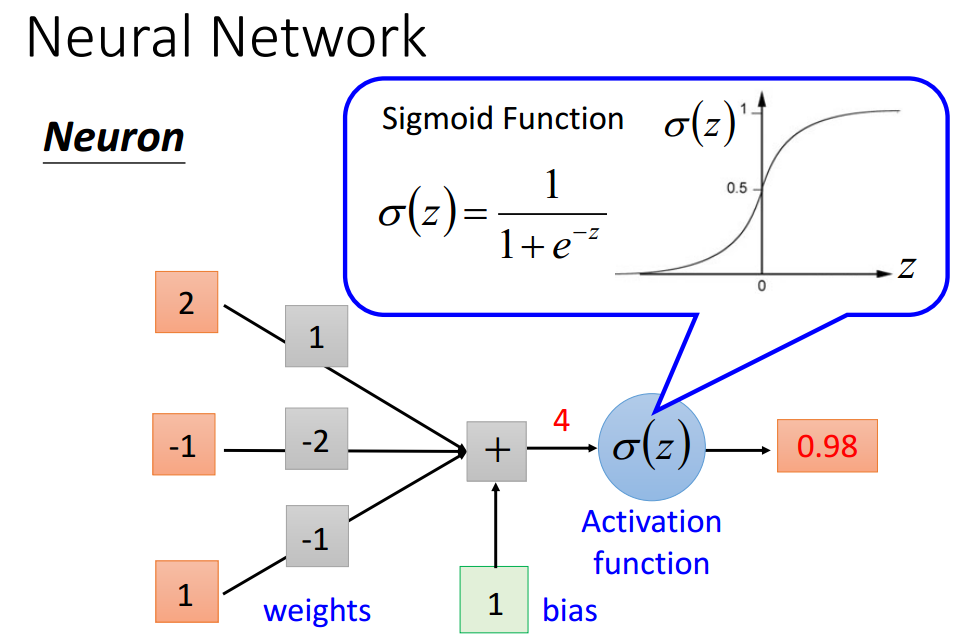
 这里需要重点引入一下softmax layer,文章中指出,一般来说,神经网络的输出可能是任意值,May not be easy to interpret。这里看来似乎是对输出做了一个归一化。
这里需要重点引入一下softmax layer,文章中指出,一般来说,神经网络的输出可能是任意值,May not be easy to interpret。这里看来似乎是对输出做了一个归一化。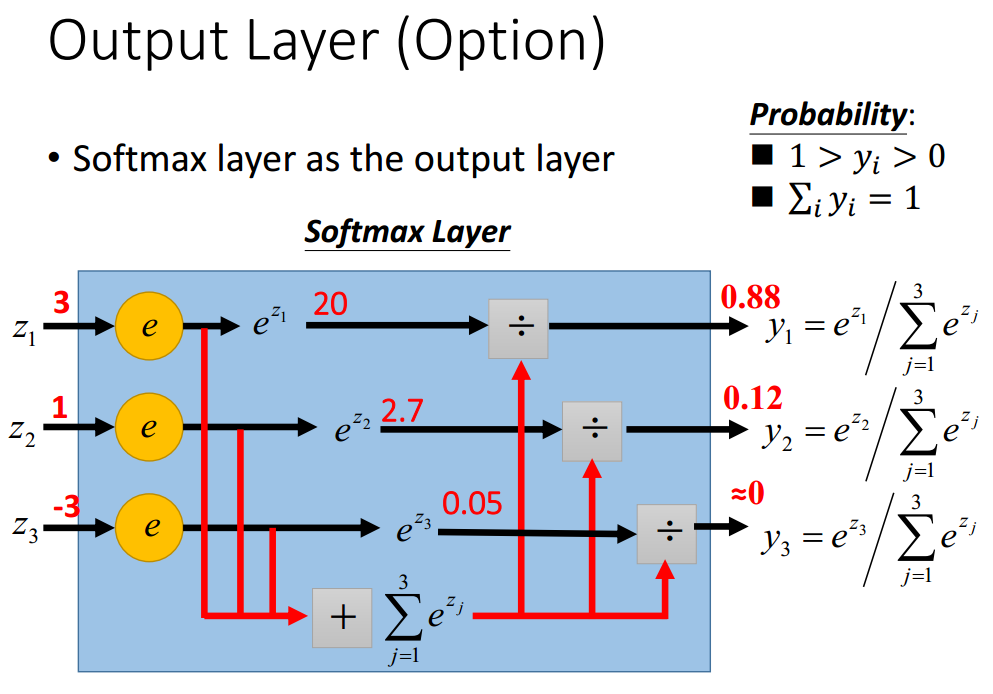

需要找到一个网络结构使得你的函数集合中有一个好的集合
- goodness of function(我想这里就是找一个好的函数集合)
目的:损失最小即网络输出与目标之间的距离最小化,找一组参数最小化整个的损失。
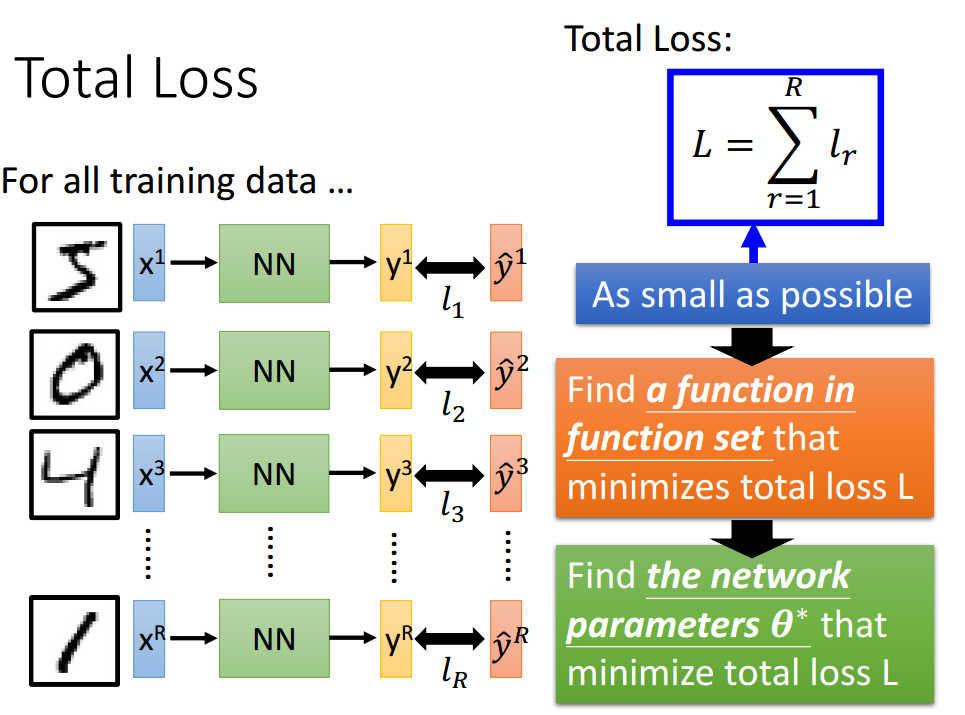
- 找一个最优的函数(去优化函数)
找网络参数使得损失最小化。穷举总是不可能滴。反向传播很经典,居然在推导以后我已经忘记了为什么要选择梯度了。。。。重新温习一下,为什么是负梯度方向。梯度方向是函数变换最快的方向,方向导数推出负梯度方向是函数在该点处减少最多的方向(方向导数最小那部分推导),梯度方向是函数增长最快的方向。所以在设置激活函数时,要求可微,即可求偏导数,即可得到负梯度方向,从而知道该点使函数下降方向,逐步使得损失函数最小的参数。(下图中,对x求偏导数是关于各变量的偏导数,得到的是梯度。而对p求导,则是方向导数。)

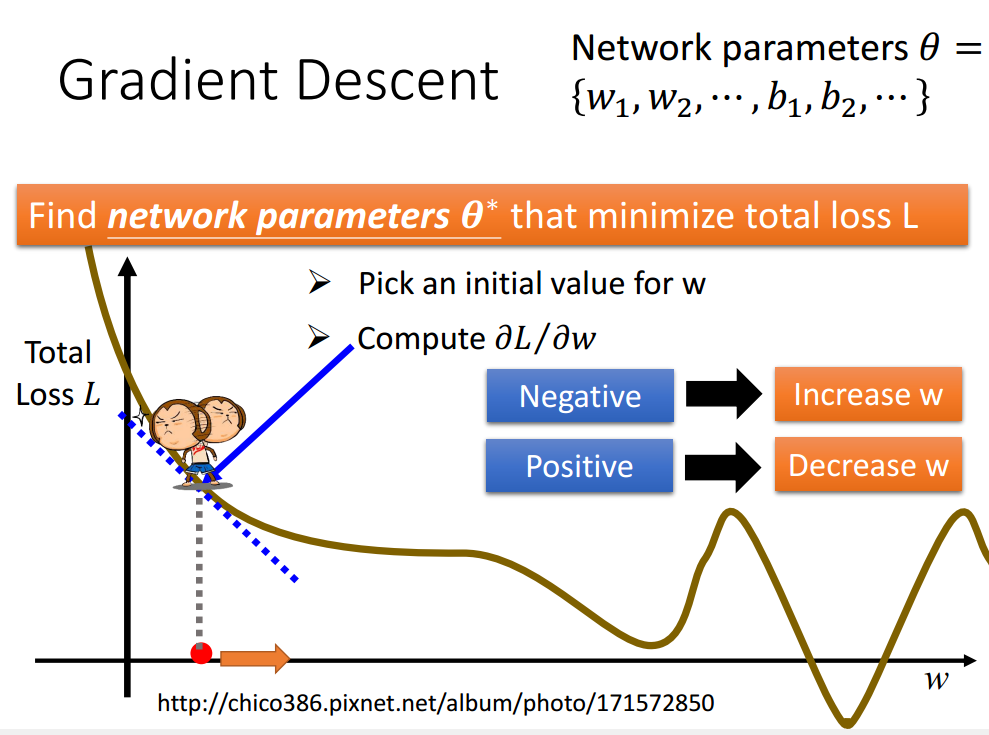
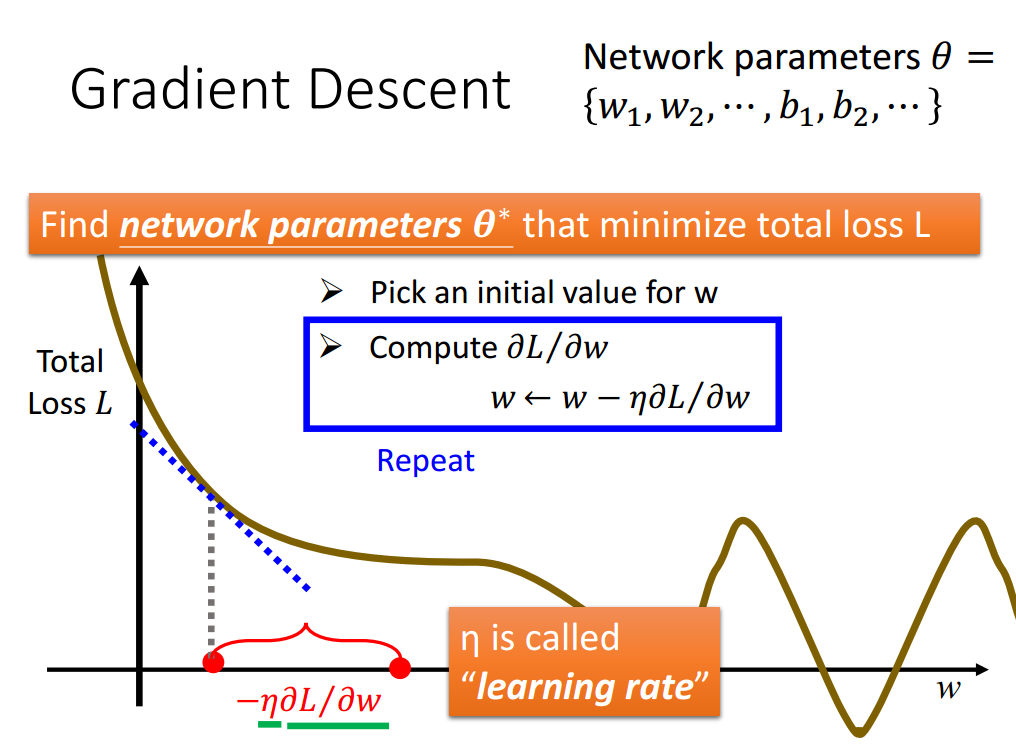
上图中,得到的梯度值本身为负值,负梯度即变成正值,即w增大的方向为函数下降的方向。反向传播是一个有效计算梯度的方法。
1.2 why deep?
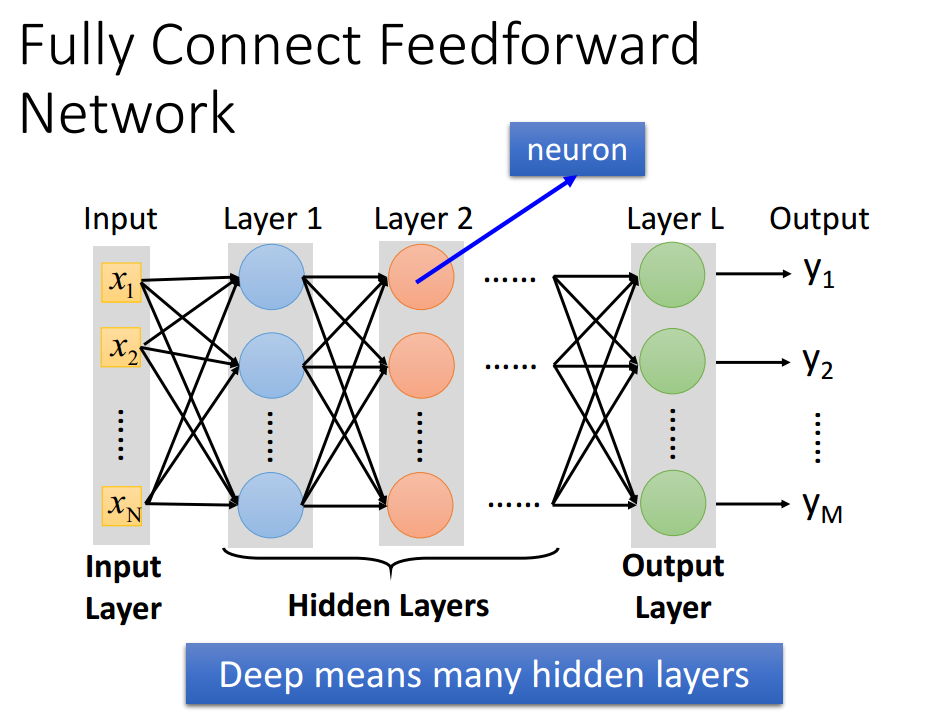
任何一个连续函数都可以用带一个隐含层(足够多隐含神经元)的网络来实现。
为什么网络是要越来越深而不是越来越胖?
基于逻辑电路为背景来说,逻辑电路由门组成,两个逻辑门可以表示任何的布尔函数,使用多层的逻辑门较为简单的建立一些函数(需要更少的门)。神经网络由神经元组成,包含一个隐含层的神经网络可以表示任何连续函数,多层神经元表示函数更加简单(需要更少的参数)。
Deep与Modularization
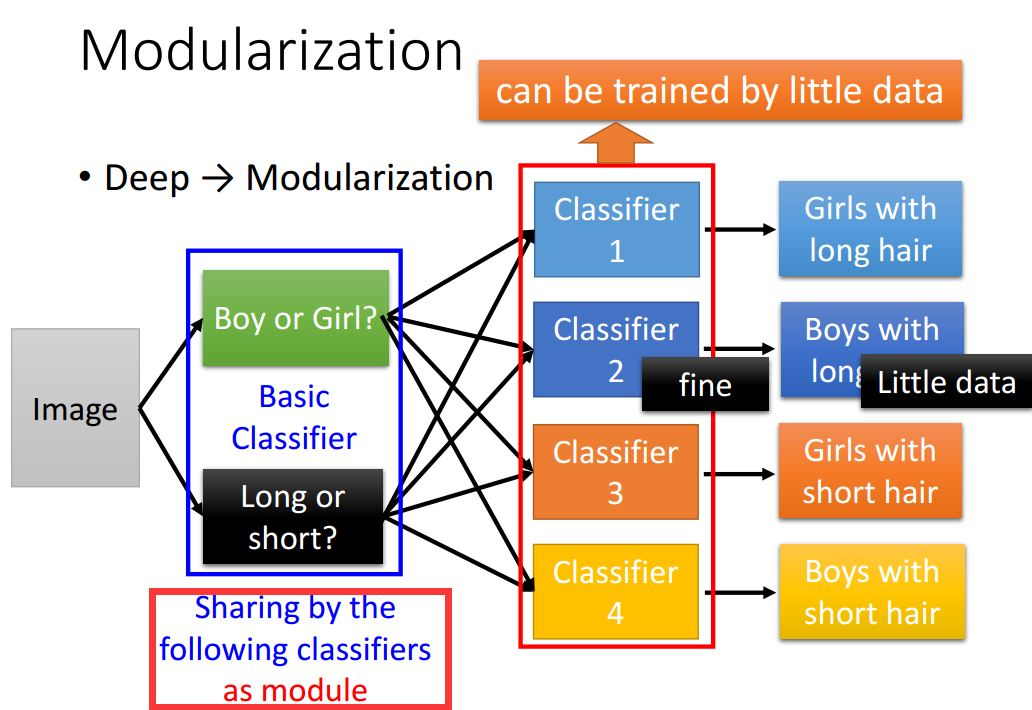
后面层使用前面层作为模块进行建立新的分类器(只需要少量的数据就可以训练获得)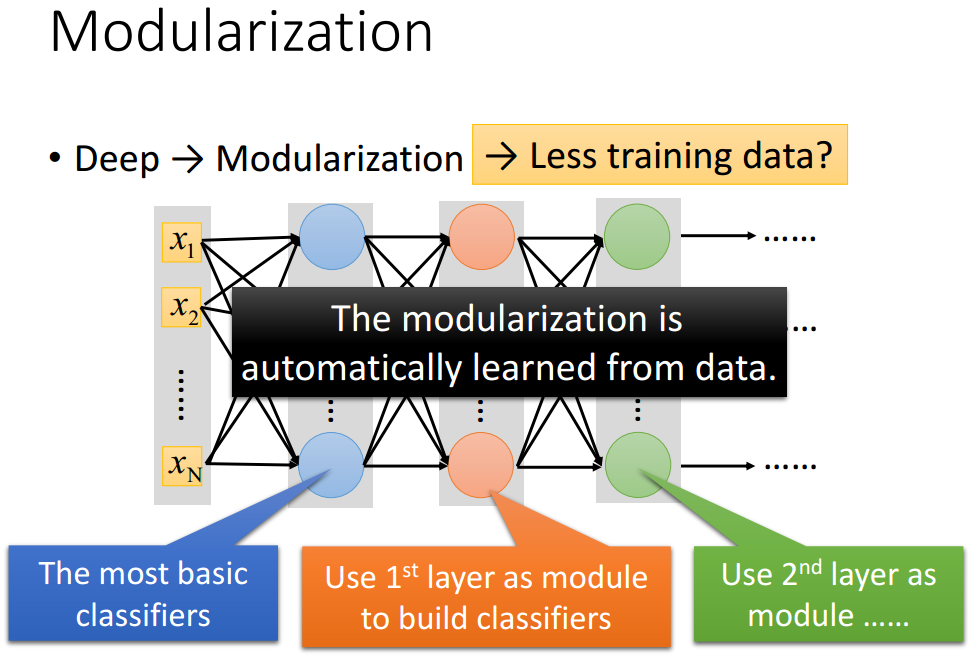
1.3 进入深度学习
这里推荐的keras。
二、 训练DNN的tips
2.1 深度学习的方法
训练数据上取得好的结果
- 选择合适的损失函数(均方误差,交叉熵)
- mini-batch (minimize mini-batches loss 而不是total loss)
- 新的激活函数
网络并不是越深越好,会出现梯度消失的问题,输入端的梯度较小,学习的慢,几乎是随机的;输出点的梯度较大,学习的较快,收敛的快。
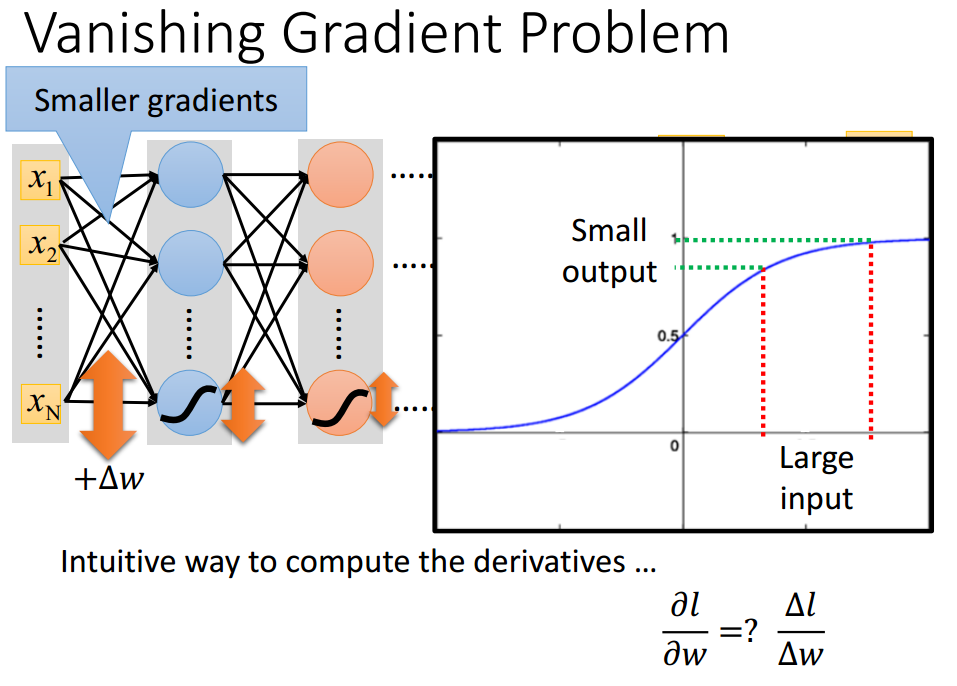
如何去解决这样的问题?在2006年开始,使用RBM做预训练。2015年,开始使用ReLU(Rectified Linear Unit)作为激活函数,原因有:快速计算,生物学原因,无限的激活函数有不同的偏置,尤其是其解决了梯度消失的问题。一张图来解释所有:梯度没有减少,并且得到了一个更瘦的网络。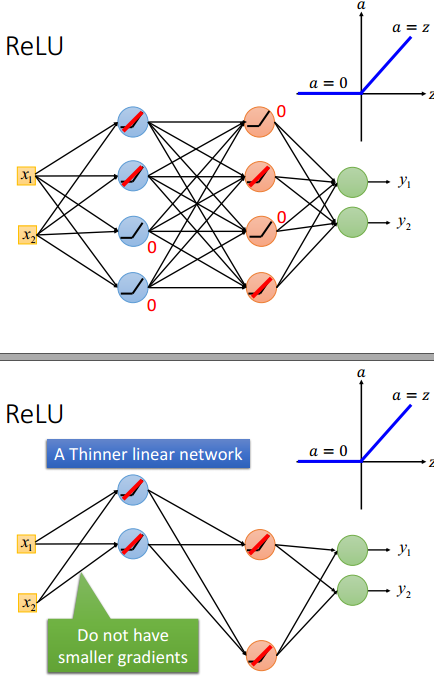
ReLU有多个变形形式,还可以看到ReLU是Maxout的特例,maxout network的激活函数可以是任何分段线性凸函数,一共有多少段,取决于这个网络中有多少个元素。
- 自适应学习率
学习率如果很大,那么可能会一直错过最小极值点(步长太大)。如果设定很小,训练速度会很慢。流行的简单方法是在每隔几个epochs,以一定比例进行减少学习率。在训练开始的时候,我们希望学习率要大一些,在几个epochs以后,我们对学习率进行减少。学习率不太可能能够通用,不同的参数,有不同的学习率。
各种改变学习率的算法(Adagrad、RMSprop、Adadelta、AdaSecant、Adam、Nadam)
- Momentum(动量)
找最优的网络参数是困难的,可能只到近似平坦的地方、鞍点或者陷入局部最优。把物理中的动量现象放到梯度下降找最优点会怎么样呢?
加上动量,能够在平坦的地方或者鞍点继续“运动”“顺势”找最优点,同时在局部最优的地方,会(添加)有一个动量,似乎是在努力看看能不能越过这个小山坡,指不定山坡的另一边才是最优点。
测试数据上能取得好结果
- 及早停止:防止过拟合,防止过拟合的方法:大量的训练数据,创造更多的训练数据。增加验证数据集(validation set)使网络及早停止

- 正则化(权重衰减,weight decay是一种正则化的方式)
大脑的剪掉了神经元之间无用的连接,这里对机器的大脑做同样的事情,去提高性能。

- Dropout
训练时,对于每一次更新参数时,有一定比例的神经元被“抛弃”,也就是说网络结构是改变的,使用新的改变的网络结构去训练,对于每一个mimi-batch,我们对从新采样(选择)要抛弃的神经元。测试时,选用全部的神经元进行预测,在训练时,按照一定比例p舍弃神经元,即保留了(1-p)比例的神经元个数。那么测试的时候,就要将权重乘以(1-p),即保证了最终输出大小一致。
这里的随机Dropout,原文举例类比其作用,在整个团队都工作的,假如每个人都期望小伙伴能把工作做好,那么最后工作必然做不好,如果你知道你的小伙伴已经无法起作用(dropout),那就只能靠自己好好做好,激发每一个人最大的潜力,同时随机性,又能保证一定的适应能力,意思是你和他能把事情做好,没了他,你和她也能把事情做好,消除了神经元之间的依赖关系。还有一些观点从动物的繁殖的基因重组比植物的无性生殖具有更强大的适应环境的能力方面进行类比解释。
dropout是一种ensemble,最后的结果相当于多个网络的输出的平均。
- 网络结构
CNN是一个非常好的例子。
三、神经网络的变体
3.1 卷积神经网络(广泛用在图像处理中)
why CNN for Image?
图片中的一些模式比整张图片要小,一个神经元不需要去看见整个图片来发现这种模式,只用少量的参数来去连接小的区域即可。卷积网络的特性:某些模式比整个图片小,相同的模式出现在不同的区域。下采样像素不会改变目标。
3.2 递归神经网络(Recurrent Neural Network)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号