数据库事务的四大特性以及事务的隔离级别
本篇讲诉数据库中事务的四大特性(ACID),并且将会详细地说明事务的隔离级别与锁机制。
一、事务的四大特性(ACID)
1、 原子性(Atomicity)
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,这和前面两篇博客介绍事务的功能是一样的概念,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
2、 一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
3、隔离性(Isolation)
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
即要达到这么一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。
关于事务的隔离性数据库提供了多种隔离级别,稍后会介绍到。
4、 持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
例如我们在使用JDBC操作数据库时,在提交事务方法后,提示用户事务操作完成,当我们程序执行完成直到看到提示后,就可以认定事务以及正确提交,即使这时候数据库出现了问题,也必须要将我们的事务完全执行完成,否则就会造成我们看到提示事务处理完毕,但是数据库因为故障而没有执行事务的重大错误。
以上介绍完事务的四大特性(简称ACID),现在重点来说明下事务的隔离性,当多个线程都开启事务操作数据库中的数据时,数据库系统要能进行隔离操作,以保证各个线程获取数据的准确性。
Note:
①这里简单理解一个概念:在未提交(commit)前你前面的操作时,更新的都是内存,没有更新到物理文件中。
如果未commit就关掉数据库连接或者后面直接回滚掉,数据库中的数据并没有更新。
②commit的提交针对的是:DML。
DML(Data Manipulation Language) 需要提交,这部分是对数据管理操作,比如Insert(插入)、Update(修改)、Delete(删除);
DDL (Data Definition Language)不需要提交,这部分是对数据结构定义,比如Create(创建)、Alter(修改)、Drop(删除)。
③SQL语言分为五大类:
DDL(数据定义语言) - Create、Alter、Drop 这些语句自动提交,无需用Commit提交。
DQL(数据查询语言) - Select 查询语句不存在提交问题。
DML(数据操纵语言) - Insert、Update、Delete 这些语句需要Commit才能提交。
DTL(事务控制语言) - Commit、Rollback 事务提交与回滚语句。
DCL(数据控制语言) - Grant、Revoke 授予权限与回收权限语句。
二、事务的隔离性
1、我们先看看如果不考虑事务的隔离性,会发生的几种问题:
(1)脏读
脏读是指在一个事务处理过程里读取了另一个未提交的事务中的数据。
当一个事务正在多次修改某个数据,而在这个事务中这多次的修改都还未提交,这时一个并发的事务来访问该数据,就会造成两个事务得到的数据不一致。例如:用户A向用户B转账100元,对应SQL命令如下
update account set money=money+100 where name=’B’; (此时A通知B) update account set money=money - 100 where name=’A’;
当只执行第一条SQL时,A通知B查看账户,B发现确实钱已到账(此时即发生了脏读),而之后无论第二条SQL是否执行,只要该事务不提交,则所有操作都将回滚,那么当B以后再次查看账户时就会发现钱其实并没有转。
(2)不可重复读
不可重复读是指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。
例如事务T1在读取某一数据,而事务T2立马修改了这个数据并且提交事务给数据库,事务T1再次读取该数据就得到了不同的结果,发送了不可重复读。
不可重复读和脏读的区别是,脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
在某些情况下,不可重复读并不是问题,比如我们多次查询某个数据当然以最后查询得到的结果为主。但在另一些情况下就有可能发生问题,例如对于同一个数据A和B依次查询就可能不同,A和B就可能打起来了……
(3)虚读(幻读)
幻读是事务非独立执行时发生的一种现象。例如事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,可以理解为是针对update 与delete操作。而幻读针对的是一批数据整体(比如数据的个数),可以理解为是针对insert操作。
2、现在来看看MySQL数据库为我们提供的四种隔离级别:
① Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
② Repeatable read (可重复读):可避免脏读、不可重复读的发生。
③ Read committed (读已提交):可避免脏读的发生。
④ Read uncommitted (读未提交):最低级别,任何情况都无法保证。
以上四种隔离级别最高的是Serializable级别,最低的是Read uncommitted级别,当然级别越高,执行效率就越低。像Serializable这样的级别,就是以锁表的方式(类似于Java多线程中的锁)使得其他的线程只能在锁外等待,所以平时选用何种隔离级别应该根据实际情况。在MySQL数据库中默认的隔离级别为Repeatable read (可重复读)。
注:在mysql5.6以上版本引入了MVCC,在Repeatable read隔离级别下已经不存在幻读问题了。
在MySQL数据库中,支持上面四种隔离级别,默认的为Repeatable read (可重复读);而在Oracle数据库中,只支持Serializable (串行化)级别和Read committed (读已提交)这两种级别,其中默认的为Read committed级别。
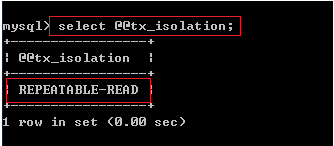
在MySQL数据库中查看当前事务的隔离级别:
select @@tx_isolation;
在MySQL数据库中设置事务的隔离 级别:
set [glogal | session] transaction isolation level 隔离级别名称; set tx_isolation=’隔离级别名称;’
例1:查看当前事务的隔离级别:
例2:将事务的隔离级别设置为Read uncommitted级别:

或:
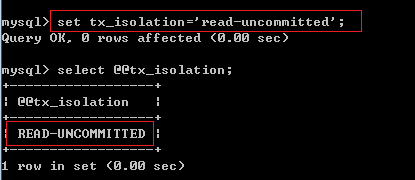
记住:设置数据库的隔离级别一定要是在开启事务之前!
如果是使用JDBC对数据库的事务设置隔离级别的话,也应该是在调用Connection对象的setAutoCommit(false)方法之前。调用Connection对象的setTransactionIsolation(level)即可设置当前链接的隔离级别,至于参数level,可以使用Connection对象的字段:

在JDBC中设置隔离级别的部分代码:

后记:隔离级别的设置只对当前链接有效。对于使用MySQL命令窗口而言,一个窗口就相当于一个链接,当前窗口设置的隔离级别只对当前窗口中的事务有效;对于JDBC操作数据库来说,一个Connection对象相当于一个链接,而对于Connection对象设置的隔离级别只对该Connection对象有效,与其他链接Connection对象无关。
Note:隔离性的实质是通过数据库的锁机制来实现的。
三、Mysql数据库的锁机制
一般可以分为两类,一个是悲观锁,一个是乐观锁,悲观锁一般就是我们通常说的数据库锁机制,乐观锁一般是指用户自己实现的一种锁机制,比如hibernate实现的乐观锁甚至编程语言也有乐观锁的思想的应用。
1、悲观锁
悲观锁:顾名思义,就是很悲观,它对于数据被外界修改持保守态度,认为数据随时会修改,所以整个数据处理中需要将数据加锁。悲观锁一般都是依靠关系数据库提供的锁机制,事实上关系数据库中的行锁,表锁不论是读写锁都是悲观锁。
1)悲观锁按照使用性质划分:
-
共享锁(Share locks简记为S锁):也称读锁,事务A对对象T加s锁,其他事务也只能对T加S,多个事务可以同时读,但不能有写操作,直到其它事务都释放S锁。
-
排它锁(Exclusivelocks简记为X锁):也称写锁,事务A对对象T加X锁以后,其他事务不能对T加任何锁,只有事务A可以读写对象T直到A释放X锁。
-
更新锁(简记为U锁):用来预定要对此对象施加X锁,它允许其他事务读,但不允许再施加U锁或X锁;当被读取的对象将要被更新时,则升级为X锁,主要是用来防止死锁的。因为使用共享锁时,修改数据的操作分为两步,首先获得一个共享锁,读取数据,然后将共享锁升级为排它锁,然后再执行修改操作。这样如果同时有两个或多个事务同时对一个对象申请了共享锁,在修改数据的时候,这些事务都要将共享锁升级为排它锁。这些事务都不会释放共享锁而是一直等待对方释放,这样就造成了死锁。如果一个数据在修改前直接申请更新锁,在数据修改的时候再升级为排它锁,就可以避免死锁。
2)悲观锁按照作用范围划分:
- 行锁:锁的作用范围是行级别,数据库能够确定那些行需要锁的情况下使用行锁,如果不知道会影响哪些行的时候就会使用表锁。举个例子,一个用户表user,有主键id和用户生日birthday当你使用update … where id=?这样的语句数据库明确知道会影响哪一行,它就会使用行锁,当你使用update … where birthday=?这样的的语句的时候因为事先不知道会影响哪些行就可能会使用表锁。
- 表锁:锁的作用范围是整张表。
2、乐观锁
乐观锁:顾名思义,就是很乐观,每次自己操作数据的时候认为没有人回来修改它,所以不去加锁,但是在更新的时候会去判断在此期间数据有没有被修改,需要用户自己去实现。既然都有数据库提供的悲观锁可以方便使用为什么要使用乐观锁呢?对于读操作远多于写操作的时候,大多数都是读取,这时候一个更新操作加锁会阻塞所有读取,降低了吞吐量。最后还要释放锁,锁是需要一些开销的,我们只要想办法解决极少量的更新操作的同步问题。换句话说,如果是读写比例差距不是非常大或者你的系统没有响应不及时,吞吐量瓶颈问题,那就不要去使用乐观锁,它增加了复杂度,也带来了额外的风险。
1)乐观锁实现方式:
- 版本号(记为version):就是给数据增加一个版本标识,在数据库上就是表中增加一个version字段,每次更新把这个字段加1,读取数据的时候把version读出来,更新的时候比较version,如果还是开始读取的version就可以更新了,如果现在的version比老的version大,说明有其他事务更新了该数据,并增加了版本号,这时候得到一个无法更新的通知,用户自行根据这个通知来决定怎么处理,比如重新开始一遍。这里的关键是判断version和更新两个动作需要作为一个原子单元执行,否则在你判断可以更新以后正式更新之前有别的事务修改了version,这个时候你再去更新就可能会覆盖前一个事务做的更新,造成第二类丢失更新,所以你可以使用update … where … and version=”old version”这样的语句,根据返回结果是0还是非0来得到通知,如果是0说明更新没有成功,因为version被改了,如果返回非0说明更新成功。
- 时间戳(timestamp):和版本号基本一样,只是通过时间戳来判断而已,注意时间戳要使用数据库服务器的时间戳不能是业务系统的时间。
- 待更新字段:和版本号方式相似,只是不增加额外字段,直接使用有效数据字段做版本控制信息,因为有时候我们可能无法改变旧系统的数据库表结构。假设有个待更新字段叫count,先去读取这个count,更新的时候去比较数据库中count的值是不是我期望的值(即开始读的值),如果是就把我修改的count的值更新到该字段,否则更新失败。java的基本类型的原子类型对象如AtomicInteger就是这种思想。
-
所有字段:和待更新字段类似,只是使用所有字段做版本控制信息,只有所有字段都没变化才会执行更新。
2)乐观锁几种方式的区别:
新系统设计可以使用version方式和timestamp方式,需要增加字段,应用范围是整条数据,不论那个字段修改都会更新version,也就是说两个事务更新同一条记录的两个不相关字段也是互斥的,不能同步进行。旧系统不能修改数据库表结构的时候使用数据字段作为版本控制信息,不需要新增字段,待更新字段方式只要其他事务修改的字段和当前事务修改的字段没有重叠就可以同步进行,并发性更高。
Note:
第一类丢失更新(Update Lost):此种更新丢失是因为回滚的原因,所以也叫回滚丢失。此时两个事务同时更新count,两个事务都读取到100,事务一更新成功并提交,count=100+1=101,事务二出于某种原因更新失败了,然后回滚,事务二就把count还原为它一开始读到的100,此时事务一的更新就这样丢失了。
第二类丢失更新(Second Update Lost):此种更新丢失是因为更新被其他事务给覆盖了,也可以叫覆盖丢失。举个例子,两个事务同时更新count,都读取100这个初始值,事务一先更新成功并提交,count=100+1=101,事务二后更新成功并提交,count=100+1=101,由于事务二count还是从100开始增加,事务一的更新就这样丢失了。
四、MySql的InnoDB一致性读(快照读)
数据库读,是数据库操作中很常见的一个操作,在数据库事务中也经常出现读取数据的操作,比如先读取是否存在,然后不存在就插入等,想要了解数据库事务,理解“读”这个操作必不可少。
数据库读分为:一致非锁定读、锁定读。这里是mysql官方文档对于一致性读的讲解,翻译一下。
1、首先来个小总结:
- 一致非锁定读,也可以称为快照读,其实就是普通的读取即普通SELECT语句。
- 既然是快照读,故 SELECT 的时候,会生成一个快照。
- 生成快照的时机:事务中第一次调用SELECT语句的时候才会生成快照,在此之前事务中执行的update、insert、delete操作都不会生成快照。
- 不同事务隔离级别下,快照读的区别: READ COMMITTED 隔离级别下,每次读取都会重新生成一个快照,所以每次快照都是最新的,也因此事务中每次SELECT也可以看到其它已commit事务所作的更改;REPEATED READ 隔离级别下,快照会在事务中第一次SELECT语句执行时生成,只有在本事务中对数据进行更改才会更新快照,因此,只有第一次SELECT之前其它已提交事务所作的更改你可以看到,但是如果已执行了SELECT,那么其它事务commit数据,你SELECT是看不到的。
2、对照官方原文翻译理解
下面是翻译正文(原文地址:https://dev.mysql.com/doc/refman/5.7/en/innodb-consistent-read.html)
InnoDB uses multi-versioning to present to a query a snapshot of the database at a point in time. The query sees the changes made by transactions that committed before that point of time, and no changes made by later or uncommitted transactions. The exception to this rule is that the query sees the changes made by earlier statements within the same transaction. This exception causes the following anomaly: If you update some rows in a table, a SELECT sees the latest version of the updated rows, but it might also see older versions of any rows. If other sessions simultaneously update the same table, the anomaly means that you might see the table in a state that never existed in the database.如果更新表中的一些行,SELECT 语句看到更新行的最新版本,但是也可能看到任何行的旧版本(ps:这后半句是什么意思?)
如果有其它会话同时更新了同一张表,这个异常意味着你可能看到数据库中从未存在过的表的脏数据。
If the transaction isolation level is REPEATABLE READ (the default level), all consistent reads within the same transaction read the snapshot established by the first such read in that transaction. You can get a fresher snapshot for your queries by committing the current transaction and after that issuing new queries.
With READ COMMITTED isolation level, each consistent read within a transaction sets and reads its own fresh snapshot.
Consistent read is the default mode in which InnoDB processes SELECT statements in READ COMMITTED and REPEATABLE READ isolation levels. A consistent read does not set any locks on the tables it accesses, and therefore other sessions are free to modify those tables at the same time a consistent read is being performed on the table.
在 READ COMMITTED 和 REPEATED READ 隔离级别下,一致性读是InnoDB 执行 SELECT 语句 的默认方式。一致性读不会对表的访问设置任何锁,因此其它的会话可以同时改变一张正在进行一致性读的表。
Suppose that you are running in the default REPEATABLE READ isolation level. When you issue a consistent read (that is, an ordinary SELECT statement), InnoDB gives your transaction a timepoint according to which your query sees the database. If another transaction deletes a row and commits after your timepoint was assigned, you do not see the row as having been deleted. Inserts and updates are treated similarly.
设想一下事务正在默认的 REPEATABLE READ 隔离级别下运行。当你进行一个一致性读(也就是说,一个普通的 SELECT 语句),InnoDB 会根据这次查询看到的数据库内容设置一个时间点。如果另外一个事务在这个时间点之后删除了其中一行并且提交,你不会看到这样被删除了。插入和更新也是被同样对待。
(ps:就是说你先在事务1中select,然后事务2中进行delete、insert、update操作,然后再次再事务1中进行select 你是看不到delete、insert、update的结果的,因为第一次select已经形成了快照)
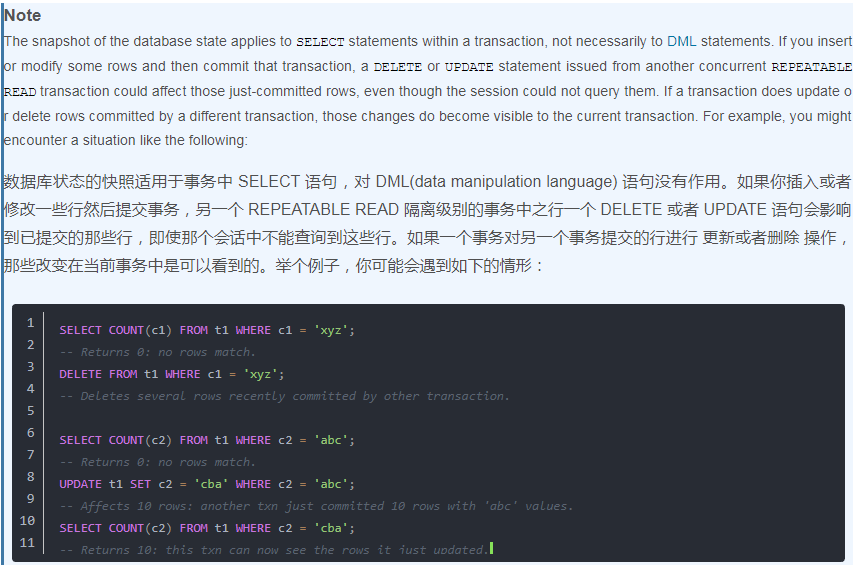
ps:上面这个例子可能没看太明白,解释一下,其实有两个事务作对比就比较好理解了,不过文档上这里只贴出来了事务1,其它事务(比如事务2、事务3等)并没有贴出来作对比。上面第一个例子的意思就是说:查询xyz的时候没有查询到,但是delete的时候却删除了一些行,这是因为有其它事务修改了数据;第二个例子是说:查询abc的时候没有查询到,但是update的时候却更新到了,然后由于是本事务进行的更新,故而后续的查询都可以看到本事务所作的更改。总结下这两个例子想要表达的就是:REPEATED READ 隔离级别下,快照会在事务中第一次SELECT语句执行时生成,只有在本事务中对数据进行更改才会更新快照,因此,只有第一次SELECT之前其它已提交事务所作的更改你可以看到,但是如果已执行了SELECT,那么其它事务commit数据,你SELECT是看不到的。
You can advance your timepoint by committing your transaction and then doing another SELECT or START TRANSACTION WITH CONSISTENT SNAPSHOT.
可以通过提交事务将时间点提前,然后执行另一个 SELECT 或者 START TRANSACTION WITH CONSISTENT SNAPSHOT。
This is called multi-versioned concurrency control.
这被称为 多版本并发控制 (MVCC)。
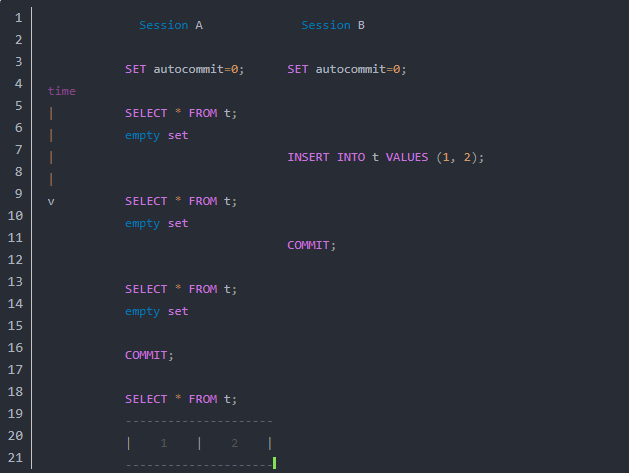
In the following example, session A sees the row inserted by B only when B has committed the insert and A has committed as well, so that the timepoint is advanced past the commit of B.
接下来的例子,会话A可以看到B插入的数据,只有B已经提交了插入的数据并且A也已经提交了事务的时候,这是由于快照生成的时间点在B提交之前。
If you want to see the “freshest” state of the database, use either the READ COMMITTED isolation level or a locking read:
如果想要看到数据库最新的状态,需要使用 READ COMMITTED 隔离级别或者锁定读:
SELECT * FROM TABLE FOR SHARE;
With READ COMMITTED isolation level, each consistent read within a transaction sets and reads its own fresh snapshot. With LOCK IN SHARE MODE, a locking read occurs instead: A SELECT blocks until the transaction containing the freshest rows ends (see Section 14.5.2.4, “Locking Reads”).
READ COMMITTED 隔离级别下,事务中每次一致性读都会设置并读取最新的快照。使用 LOCK IN SHARE MODE 模式,会进行锁定读:SELECT 会阻塞直到事务读取到最新的行 为止。
- 一致性读对 DROP TABLE 无效,因为MySQL不能使用已经被删除的表,InnoDB会销毁表。
- 一致性读对 ALTER TABLE 无效,这是因为这条语句会根据源表产生一个临时副本并且会删除源表当副本被创建时。当你在事务中再次进行一致读的时候,新表中的行对你是不可见的,因为当事务快照创建的时候这些行还不存在。因此,事务会返回错误: ER_TABLE_DEF_CHANGED, “Table definition has changed, please retry transaction”。
五、
1、for update, lock in share mode
for update :是IX锁(意向排它锁),即在符合条件的rows上都加了排它锁,其他session也就无法在这些记录上添加任何的S锁或X锁。如果不存在一致性非锁定读的话,那么其他session是无法读取和修改这些记录的,但是innodb有非锁定读(快照读并不需要加锁),for update之后并不会阻塞其他session的快照读取操作,除了select ...lock in share mode和select ... for update这种显示加锁的查询操作。
lock in share mode :是IS锁(意向共享锁),即在符合条件的rows上都加了共享锁,这样的话,其他session可以读取这些记录,也可以继续添加IS锁,但是无法修改这些记录直到你这个加锁的session执行完成(否则直接锁等待超时)。
ps: 这两种模式加锁的表无数据的情况下,锁不会起作用,必须加锁的表必须有数据(待亲测)。 lock in share mode 也叫间隙锁。
2、事务并发性理解
事务并发性,粗略的理解就是单位时间内能够执行的事务数量,常见的单位是 TPS( transactions per second).
那在数据量和业务操作量一定的情况下,常见的提高事务并发性主要考虑的有哪几点呢?
1)1.提高服务器的处理能力,让事务的处理时间变短。
这样不仅加快了这个事务的执行时间,也降低了其他等待该事务执行的事务执行时间。
2)尽量将事务涉及到的 sql 操作语句控制在合理范围,换句话说就是不要让一个事务包含的操作太多或者太少。
在业务繁忙情况下,如果单个事务操作的表或者行数据太多,其他的事务可能都在等待该事务 commit或者 rollback,这样会导致整体上的 TPS 降低。但是,如果每个 sql 语句都是一个事务也是不太现实的。一来,有些业务本身需要多个sql语句来构成一个事务(比如汇款这种多个表的操作);二来,每个 sql 都需要commit,如果在 mysql 里 innodb_flush_log_at_trx_commit=1 的情况下,会导致 redo log 的刷新过于频繁,也不利于整体事务数量的提高(IO限制也是需要考虑的重要因素)。
3)在操作的时候,尽量控制锁的粒度,能用小的锁粒度就尽量用锁的粒度,用完锁资源后要记得立即释放,避免后面的事务等待。
但是有些情况下,由于业务需要,或者为了保证数据的一致性的时候,必须要增加锁的粒度,这个时候就是下面所说的几种情况。
3、select for update 理解
select col from t where where_clause for update 的目的是在执行这个 select 查询语句的时候,会将对应的索引访问条目进行上排他锁(X 锁),也就是说这个语句对应的锁就相当于update带来的效果。
那这种语法为什么会存在呢?肯定是有需要这种方式的存在啦!!请看下面的案例描述:
案例1:
前提条件:
mysql 隔离级别 repeatable-read ,
事务1:
建表: CREATE TABLE `lockt` ( `id` int(11) NOT NULL, `col1` int(11) DEFAULT NULL, `col2` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `col1_ind` (`col1`), KEY `col2_ind` (`col2`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 插入数据 。。。。。 mysql> set autocommit=0; Query OK, 0 rows affected (0.00 sec) mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 14 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec)
然后另外一个事务2 进行了下面的操作:
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 14 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec) mysql> update lockt set col2= 144 where col2=14; Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> commit; Query OK, 0 rows affected (0.00 sec)
结果:可以看到事务2 将col2=14 的列改为了 col2=144.
可是事务1继续执行的时候根本没有觉察到 lockt 发生了变化,请看 事务1 继续后面的操作:
mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 14 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.01 sec) mysql> update lockt set col2=col2*2 where col2=14; Query OK, 0 rows affected (0.00 sec) Rows matched: 0 Changed: 0 Warnings: 0 mysql> commit; Query OK, 0 rows affected (0.00 sec) mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 144 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec)
结果: 事务1 明明查看到的存在 col2=12 的行数据,可是 update 后,竟然不仅没有改为他想要的col2=28 的值,反而变成了 col2=144 !!!!
这在有些业务情况下是不允许的,因为有些业务希望我通过 select * from lockt; 查询到的数据是此时数据库里面真正存储的最新数据,并且不允许其他的事务来修改只允许我来修改。(这个要求很霸气,但是我喜欢。。)
这种情况就是很牛逼的情况了。具体的细节请参考下面的案例2:
案例2:
mysql 条件和案例1 一样。
事务1操作:
mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from lockt where col2=20 for update; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 8 | 8 | 20 | +----+------+------+ 1 row in set (0.00 sec)
事务2 操作:
mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 144 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec) mysql> update lockt set col2=222 where col2=20;
注意: 事务2 在执行 update lockt set col2=222 where col2=20; 的时候,会发现 sql 语句被 block住了,为什么会发现这种情况呢?
因为事务1 的 select * from lockt where col2=20 for update; 语句会将 col2=20 这个索引的入口给锁住了,(其实有些时候是范围的索引条目也被锁住了,暂时不讨论。),那么事务2虽然看到了所有的数据,但是想去修改 col2=20 的行数据的时候, 事务1 只能说 “不可能也不允许”。
后面只有事务1 commit或者rollback 以后,事务2 的才能够修改 col2=20 的这个行数据。
总结:
这就是 select for update 的使用场景,为了避免自己看到的数据并不是数据库存储的最新数据并且看到的数据只能由自己修改,需要用 for update 来限制。
4、select lock in share mode 理解
如果看了前面的 select *** for update ,就可以很好的理解 select lock in share mode ,in share mode 子句的作用就是将查找到的数据加上一个 share 锁,这个就是表示其他的事务只能对这些数据进行简单的select 操作,并不能够进行 DML 操作。
那它和 for update 在引用场景上究竟有什么实质上的区别呢?
lock in share mode 没有 for update 那么霸道,所以它有时候也会遇到问题,请看案例3
案例3:
mysql 环境和案例1 类似
事务1:
mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 144 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec) mysql> select * from lockt where col2=20 lock in share mode; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 8 | 8 | 20 | +----+------+------+ 1 row in set (0.00 sec)
事务2 接着开始操作
mysql> select * from lockt; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 1 | 1 | 1 | | 2 | 2 | 3 | | 5 | 5 | 5 | | 6 | 6 | 9 | | 7 | 7 | 144 | | 8 | 8 | 20 | +----+------+------+ 6 rows in set (0.00 sec) mysql> select * from lockt where col2=20 lock in share mode; +----+------+------+ | id | col1 | col2 | +----+------+------+ | 8 | 8 | 20 | +----+------+------+ 1 row in set (0.01 sec)
后面的比较蛋疼的一幕出现了,当 事务1 想更新 col2=20 的时候,他发现 block 住了。
mysql> update lockt set col2=22 where col2=20;
解释:因为事务1 和事务2 都对该行上了一个 share 锁,事务1 以为就只有自己一个人上了 S 锁,所以当事务一想修改的时候发现没法修改,这种情况下,事务1 需要使用 for update 子句来进行约束了,而不是使用 for share 来使用。
5、可能用到的情景和对性能的影响
使用情景:
1. select *** for update 的使用场景
为了让自己查到的数据确保是最新数据,并且查到后的数据只允许自己来修改的时候,需要用到 for update 子句。
2. select *** lock in share mode 使用场景
为了确保自己查到的数据没有被其他的事务正在修改,也就是说确保查到的数据是最新的数据,并且不允许其他人来修改数据。但是自己不一定能够修改数据,因为有可能其他的事务也对这些数据 使用了 in share mode 的方式上了 S 锁。
性能影响:
select for update 语句,相当于一个 update 语句。在业务繁忙的情况下,如果事务没有及时的commit或者rollback 可能会造成其他事务长时间的等待,从而影响数据库的并发使用效率。
select lock in share mode 语句是一个给查找的数据上一个共享锁(S 锁)的功能,它允许其他的事务也对该数据上 S锁,但是不能够允许对该数据进行修改。如果不及时的commit 或者rollback 也可能会造成大量的事务等待。
for update 和 lock in share mode 的区别:前一个上的是排他锁(X 锁),一旦一个事务获取了这个锁,其他的事务是没法在这些数据上执行 for update ;后一个是共享锁,多个事务可以同时的对相同数据执行 lock in share mode。
本文整理自:
https://www.cnblogs.com/fjdingsd/p/5273008.html
https://blog.csdn.net/aluomaidi/article/details/52460844
https://blog.csdn.net/cxm19881208/article/details/79415726
https://blog.csdn.net/liangzhonglin/article/details/65438777
https://www.cnblogs.com/liushuiwuqing/p/3966898.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架