面试题目:手写一个LRU算法实现
一、常见的内存淘汰算法
-
FIFO 先进先出
-
在这种淘汰算法中,先进⼊缓存的会先被淘汰
-
命中率很低
-
-
LRU
-
-
Least recently used,最近最少使⽤get
-
-
-
根据数据的历史访问记录来进⾏淘汰数据,其核⼼思想是“如果数据最近被访问过,那么将来被访问的⼏率也更⾼”
-
-
-
LRU算法原理剖析
-

-
LFU
- Least Frequently Used
-
算法根据数据的历史访问频率来淘汰数据,其核⼼思想是“如果数据过去被访问多次,那么将来被访问的频率也更⾼”
-
-
LFU算法原理剖析
-
-
-
-
新加⼊数据插⼊到队列尾部(因为引⽤计数为1)
-
-
-
-
-
队列中的数据被访问后,引⽤计数增加,队列重新排序;
-
当需要淘汰数据时,将已经排序的列表最后的数据块删除。
-
-
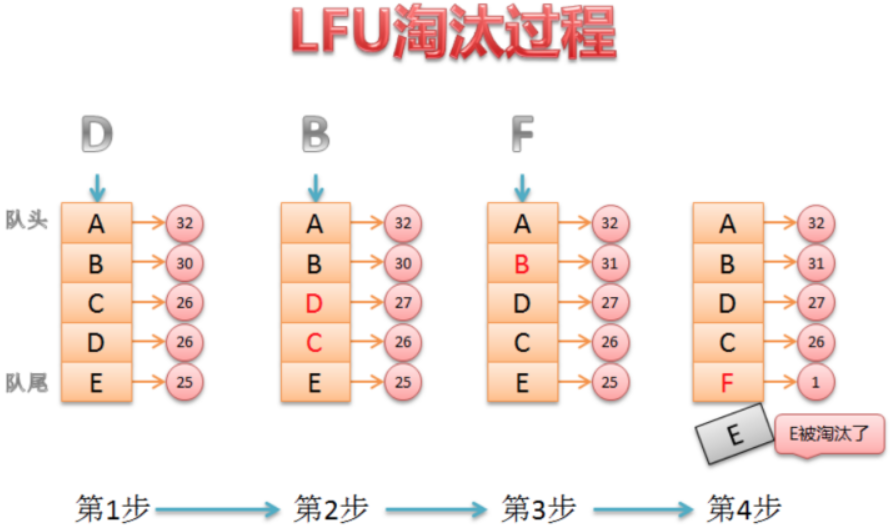
- LFU的缺点
- 复杂度
- 存储成本
- 尾部容易被淘汰
二、手写LRU算法实现
利用了LinkedHashMap双向链表插入可排序
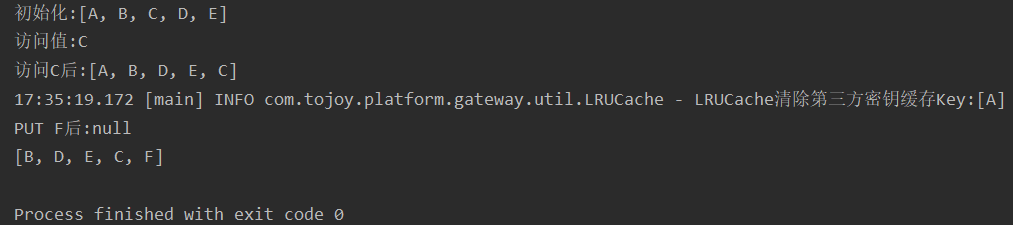
@Slf4j public class LRUCache<K, V> extends LinkedHashMap<K, V> { private int cacheSize; public LRUCache(int cacheSize) { super(16, 0.75f, true); this.cacheSize = cacheSize; } @Override public synchronized V get(Object key) { return super.get(key); } @Override public synchronized V put(K key, V value) { return super.put(key, value); } @Override protected boolean removeEldestEntry(Map.Entry<K, V> eldest) { boolean f = size() > cacheSize; if (f) { log.info("LRUCache清除第三方密钥缓存Key:[{}]", eldest.getKey()); } return f; } public static void main(String[] args) { LRUCache<String, Object> cache = new LRUCache<>(5); cache.put("A","A"); cache.put("B","B"); cache.put("C","C"); cache.put("D","D"); cache.put("E","E"); System.out.println("初始化:" + cache.keySet()); System.out.println("访问值:" + cache.get("C")); System.out.println("访问C后:" + cache.keySet()); System.out.println("PUT F后:" + cache.put("F","F")); System.out.println(cache.keySet()); } }
main函数执行效果:
三、注意事项
LinkedHashMap有五个构造函数
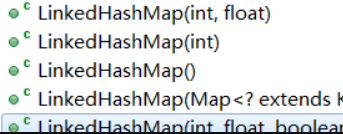


//使用父类中的构造,初始化容量和加载因子,该初始化容量是指数组大小。 public LinkedHashMap(int initialCapacity, float loadFactor) { super(initialCapacity, loadFactor); accessOrder = false; } //一个参数的构造 public LinkedHashMap(int initialCapacity) { super(initialCapacity); accessOrder = false; } //无参构造 public LinkedHashMap() { super(); accessOrder = false; } //这个不用多说,用来接受map类型的值转换为LinkedHashMap public LinkedHashMap(Map<? extends K, ? extends V> m) { super(m); accessOrder = false; } //真正有点特殊的就是这个,多了一个参数accessOrder。存储顺序,LinkedHashMap关键的参数之一就在这个, //true:指定迭代的顺序是按照访问顺序(近期访问最少到近期访问最多的元素)来迭代的。 false:指定迭代的顺序是按照插入顺序迭代,也就是通过插入元素的顺序来迭代所有元素 //如果你想指定访问顺序,那么就只能使用该构造方法,其他三个构造方法默认使用插入顺序。 public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; }
参数accessOrder。存储顺序,LinkedHashMap关键的参数之一就在这个, true:指定迭代的顺序是按照访问顺序(近期访问最少到近期访问最多的元素)来迭代的。 false:指定迭代的顺序是按照插入顺序迭代,也就是通过插入元素的顺序来迭代所有元素。
如果你想指定访问顺序,那么就只能使用该构造方法,其他三个构造方法默认使用插入顺序。
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; }
LinkedHashMap是非线程安全的,需要加互斥锁解决并发问题。
四、思考
需要根据应用场景确定cacheSize大小,如果实际缓存数量过小,会导致缓存中的数据长期得不到刷新,为防止这种或偶发情况的发生,可配合定时任务如起一个newSingleThreadScheduledExecutor,将上面存储的value修改封装为一个对象,里面增加一个时间戳储存,每次访问实时更新,定时扫描该队列将最近30分钟未访问的key删除;还需增加一个初始进入队列的历史时间记录,将超过1小时的数据清除。

