ArrayList与LinkedList的区别
1、先来看看ArrayList与LinkedList 在JDK中所在的位置
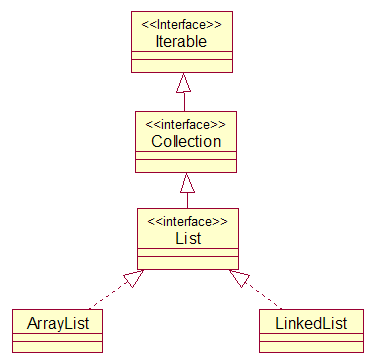
从图中可以看出,ArrayList与LinkedList都是List接口的实现类,因此都实现了List的所有未实现的方法,只是实现的方式有所不同,(编程思想: 从中可以看出面向接口的好处, 对于不同的需求就有不同的实现!),而List接口继承了Collection接口,Collection接口又继承了Iterable接口,因此可以看出List同时拥有了Collection与Iterable接口的特性。
2、认识ArrayList
ArrayList和Vector使用了数组的实现,可以认为ArrayList或者Vector封装了对内部数组的操作,比如向数组中添加,删除,插入新的元素或者数据的扩展和重定向。
数组的特性是可以使用索引的方式来快速定位对象的位置,因此对于快速的随机取得对象的需求,使用ArrayList实现执行效率上会比较好。
2、认识LinkedList
LinkedList使用了循环双向链表数据结构。与基于数组ArrayList相比,这是两种截然不同的实现技术,这也决定了它们将适用于完全不同的工作场景。
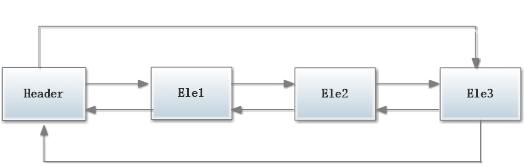
LinkedList链表由一系列表项连接而成。一个表项总是包含3个部分:元素内容,前驱表和后驱表,如图所示:

在下图展示了一个包含3个元素的LinkedList的各个表项间的连接关系。在JDK的实现中,无论LikedList是否为空,链表内部都有一个header表项,它既表示链表的开始,也表示链表的结尾。表项header的后驱表项便是链表中第一个元素,表项header的前驱表项便是链表中最后一个元素。
3、ArrayList和LinkedList的区别
下面以增加和删除元素为例比较ArrayList和LinkedList的不同之处:
(1)增加元素到列表尾端:
在ArrayList中增加元素到队列尾端的代码如下:
public boolean add(E e){ ensureCapacity(size+1);//确保内部数组有足够的空间 elementData[size++]=e;//将元素加入到数组的末尾,完成添加 return true; }
ArrayList中add()方法的性能决定于ensureCapacity()方法。ensureCapacity()的实现如下:
public vod ensureCapacity(int minCapacity){ modCount++; int oldCapacity=elementData.length; if(minCapacity>oldCapacity){ //如果数组容量不足,进行扩容 Object[] oldData=elementData; int newCapacity=(oldCapacity*3)/2+1; //扩容到原始容量的1.5倍 if(newCapacitty<minCapacity) //如果新容量小于最小需要的容量,则使用最小 //需要的容量大小 newCapacity=minCapacity ; //进行扩容的数组复制 elementData=Arrays.copyof(elementData,newCapacity); } }
可以看到,只要ArrayList的当前容量足够大,add()操作的效率非常高的。只有当ArrayList对容量的需求超出当前数组大小时,才需要进行扩容。扩容的过程中,会进行大量的数组复制操作。而数组复制时,最终将调用System.arraycopy()方法,因此add()操作的效率还是相当高的。
LinkedList 的add()操作实现如下,它也将任意元素增加到队列的尾端:
public boolean add(E e){ addBefore(e,header);//将元素增加到header的前面 return true; }
其中addBefore()的方法实现如下:
private Entry<E> addBefore(E e,Entry<E> entry){ Entry<E> newEntry = new Entry<E>(e,entry,entry.previous); newEntry.provious.next=newEntry; newEntry.next.previous=newEntry; size++; modCount++; return newEntry; }
可见,LinkeList由于使用了链表的结构,因此不需要维护容量的大小。从这点上说,它比ArrayList有一定的性能优势,然而,每次的元素增加都需要新建一个Entry对象,并进行更多的赋值操作。在频繁的系统调用中,对性能会产生一定的影响。
(2)增加元素到列表任意位置
除了提供元素到List的尾端,List接口还提供了在任意位置插入元素的方法:void add(int index,E element);
由于实现的不同,ArrayList和LinkedList在这个方法上存在一定的性能差异,由于ArrayList是基于数组实现的,而数组是一块连续的内存空间,如果在数组的任意位置插入元素,必然导致在该位置后的所有元素需要重新排列,因此,其效率相对会比较低。
以下代码是ArrayList中的实现:
public void add(int index,E element){ if(index>size||index<0) throw new IndexOutOfBoundsException( "Index:"+index+",size: "+size); ensureCapacity(size+1); System.arraycopy(elementData,index,elementData,index+1,size-index); elementData[index] = element; size++; }
可以看到每次插入操作,都会进行一次数组复制。而这个操作在增加元素到List尾端的时候是不存在的,大量的数组重组操作会导致系统性能低下。并且插入元素在List中的位置越是靠前,数组重组的开销也越大。
而LinkedList此时显示了优势:
public void add(int index,E element){ addBefore(element,(index==size?header:entry(index))); }
可见,对LinkedList来说,在List的尾端插入数据与在任意位置插入数据是一样的,不会因为插入的位置靠前而导致插入的方法性能降低。
(3)删除任意位置元素
对于元素的删除,List接口提供了在任意位置删除元素的方法:
public E remove(int index);
对ArrayList来说,remove()方法和add()方法是雷同的。在任意位置移除元素后,都要进行数组的重组。ArrayList的实现如下:
public E remove(int index){ RangeCheck(index); modCount++; E oldValue=(E) elementData[index]; int numMoved=size-index-1; if(numMoved>0) System.arraycopy(elementData,index+1,elementData,index,numMoved); elementData[--size]=null; return oldValue; }
可以看到,在ArrayList的每一次有效的元素删除操作后,都要进行数组的重组。并且删除的位置越靠前,数组重组时的开销越大。
public E remove(int index){ return remove(entry(index)); } private Entry<E> entry(int index){ if(index<0 || index>=size) throw new IndexOutBoundsException("Index:"+index+",size:"+size); Entry<E> e= header; if(index<(size>>1)){//要删除的元素位于前半段 for(int i=0;i<=index;i++) e=e.next; }else{ for(int i=size;i>index;i--) e=e.previous; } return e; }
在LinkedList的实现中,首先要通过循环找到要删除的元素。如果要删除的位置处于List的前半段,则从前往后找;若其位置处于后半段,则从后往前找。因此无论要删除较为靠前或者靠后的元素都是非常高效的;但要移除List中间的元素却几乎要遍历完半个List,在List拥有大量元素的情况下,效率很低。
(4)容量参数
容量参数是ArrayList和Vector等基于数组的List的特有性能参数。它表示初始化的数组大小。当ArrayList所存储的元素数量超过其已有大小时。它便会进行扩容,数组的扩容会导致整个数组进行一次内存复制。因此合理的数组大小(创建时初始化容量大小)有助于减少数组扩容的次数,从而提高系统性能。
public ArrayList(){ this(10); } public ArrayList (int initialCapacity){ super(); if(initialCapacity<0) throw new IllegalArgumentException("Illegal Capacity:"+initialCapacity) this.elementData=new Object[initialCapacity]; }
ArrayList提供了一个可以制定初始数组大小的构造函数:
public ArrayList(int initialCapacity)
现以构造一个拥有100万元素的List为例,当使用默认初始化大小时,其消耗的相对时间为125ms左右,当直接制定数组大小为100万时,构造相同的ArrayList仅相对耗时16ms。
(5)删除和插入对象的动作时,为什么ArrayList的效率会比较低呢?
因为ArrayList是使用数组实现的,若要从数组中删除或插入某一个对象,需要移动后段的数组元素,从而会重新调整索引顺序,调整索引顺序会消耗一定的时间,所以速度上就会比LinkedList要慢许多. 相反,LinkedList是使用链表实现的,若要从链表中删除或插入某一个对象,只需要改变前后对象的引用即可!
(6)遍历列表
遍历列表操作是最常用的列表操作之一,在JDK1.5之后,至少有3中常用的列表遍历方式:forEach操作,迭代器和for循环。
String tmp; long start=System.currentTimeMills(); //ForEach for(String s:list){ tmp=s; } System.out.println("foreach spend:"+(System.currentTimeMills()-start)); start = System.currentTimeMills(); for(Iterator<String> it=list.iterator();it.hasNext();){ tmp=it.next(); } System.out.println("Iterator spend;"+(System.currentTimeMills()-start)); start=System.currentTimeMills(); int size=;list.size(); for(int i=0;i<size;i++){ tmp=list.get(i); } System.out.println("for spend;"+(System.currentTimeMills()-start));
构造一个拥有100万数据的ArrayList和等价的LinkedList,使用以上代码进行测试,测试结果的相对耗时如下表所示:

可以看到,最简便的ForEach循环并没有很好的性能表现,综合性能不如普通的迭代器,而是用for循环通过随机访问遍历列表时,ArrayList表项很好,但是LinkedList的表现却无法让人接受,甚至没有办法等待程序的结束。这是因为对LinkedList进行随机访问时,总会进行一次列表的遍历操作。性能非常差,应避免使用。
ArrayList的get方法只是从数组里面拿一个位置上的元素罢了。我们有结论,ArrayList的get方法的时间复杂度是O(1),O(1)的意思也就是说时间复杂度是一个常数,和数组的大小并没有关系,只要给定数组的位置,直接就能定位到数据。
再看一下LinkedList的get方法做了什么:
public E get(int index) { return entry(index).element; }
private Entry<E> entry(int index) { if (index < 0 || index >= size) throw new IndexOutOfBoundsException("Index: "+index+ ", Size: "+size); Entry<E> e = header; if (index < (size >> 1)) { for (int i = 0; i <= index; i++) e = e.next; } else { for (int i = size; i > index; i--) e = e.previous; } return e; }
由于LinkedList是双向链表,因此第6行的意思是算出i在一半前还是一半后,一半前正序遍历、一半后倒序遍历,这样会快很多,当然,先不管这个,分析一下为什么使用普通for循环遍历LinkedList会这么慢。
1、get(0),直接拿到0位的Node0的地址,拿到Node0里面的数据
2、get(1),直接拿到0位的Node0的地址,从0位的Node0中找到下一个1位的Node1的地址,找到Node1,拿到Node1里面的数据
3、get(2),直接拿到0位的Node0的地址,从0位的Node0中找到下一个1位的Node1的地址,找到Node1,从1位的Node1中找到下一个2位的Node2的地址,找到Node2,拿到Node2里面的数据。
后面的以此类推。
也就是说,LinkedList在get任何一个位置的数据的时候,都会把前面的数据走一遍。假如我有10个数据,那么将要查询1+2+3+4+5+5+4+3+2+1=30次数据,相比ArrayList,却只需要查询10次数据就行了,随着LinkedList的容量越大,差距会越拉越大。其实使用LinkedList到底要查询多少次数据,大家应该已经很明白了,来算一下:按照前一半算应该是(1 + 0.5N) * 0.5N / 2,后一半算上即乘以2,应该是(1 + 0.5N) * 0.5N = 0.25N2 + 0.5N,忽略低阶项和首项系数,得出结论,LinikedList遍历的时间复杂度为O(N2),N为LinkedList的容量。
时间复杂度有以下经验规则:
O(1) < O(log2N) < O(n) < O(N * log2N) < O(N2) < O(N3) < 2N < 3N < N!
前四个比较好、中间两个一般、后3个很烂。也就是说O(N2)是相对糟糕的一种时间复杂度了,N大一点,程序就会执行得比较慢。
4、两者应用场景
(1) ArrayList由于具有数组特性,所以访问数据速度要快,尤其是随机访问数据(指定数组index下标即可)。此时如果用LinkedList效率低,因为如果你需要LinkedList中的第n个元素的时候,你需要从第一个元素顺序数到第n个数据,然后读取数据。
(2) 当更多的插入和删除元素,更少的读取数据时使用LinkedList优。因为插入和删除元素不涉及重排数据,所以它要比ArrayList要快。
5、LinkedList的其他应用场景
LinkedList是采用链表的方式来实现List接口的,它本身有自己特定的方法,如: addFirst(),addLast(),getFirst(),removeFirst()等. 由于是采用链表实现的,因此在进行insert和remove动作时在效率上要比ArrayList要好得多!适合用来实现Stack(堆栈)与Queue(队列),前者先进后出,后者是先进先出。
堆栈(实现队列类似):
public class StringStack { private LinkedList<String> linkedList = new LinkedList<String>(); /** * 将元素加入LinkedList容器 * (即插入到链表的第一个位置) */ public void push(String name){ linkedList.addFirst(name); } /** * 取出堆栈中最上面的元素 * (即取出链表linkedList的第一个元素) * @return */ public String getTop(){ return linkedList.getFirst(); } /** * 取出并删除最上面的元素 * (即移出linkedList的第一个元素) * @return */ public String pop(){ return linkedList.removeFirst(); } /** * 获取元素个数 * @return */ public int size(){ return linkedList.size(); } /** * 判断堆栈是否为空 * (即判断 linkedList是否为空) * @return */ public boolean isEmpty(){ return linkedList.isEmpty(); } //测试 public static void main(String[] args) { StringStack stack = new StringStack(); stack.push("yulon"); stack.push("xiaoyun"); stack.push("羽龙共舞"); System.out.print("第一个元素是:\t"); System.out.println(stack.getTop()); System.out.println(); System.out.println("全部元素:"); while(!stack.isEmpty()){ System.out.println("\t"+stack.pop()); } } }
输出结果:


第一个元素是: 羽龙共舞
全部元素:
羽龙共舞
xiaoyun
提示: LinkedList的特有方法(本身定义的方法)如:addFirst()、addLast()、getFirst()、getLast()、removeFirst()、removeLast()等。
6、LinkedList和ArrayList之间互相转换
ArrayList与类LinkedList不能强制数据类型转换。
1.通过构造方法转换
ArrayList arrayList = new ArrayList();
LinkedList linkedList = new LinkedList(arrayList);
LinkedList linkedList = new LinkedList();
ArrayList arrayList = new ArrayList(linkedList);
2.通过list的add方法
参考文章:
https://www.cnblogs.com/sierrajuan/p/3639353.html
https://blog.csdn.net/bjzhuhehe/article/details/72230559

