LinkedHashMap原理
一、HashMap和LinkedHashMap的区别
LinkedHashMap是HashMap的一个子类,其特殊实现的仅仅是保存了记录的插入顺序,所以在Iterator迭代器遍历LinkedHashMap时先得到的键值是先插入的(也可以在构造时用带参构造方法来改变顺序为按照使用进行排序),其存储沿用了HashMap结构外还多了一个双向链表,具备HashMap的所有特性和缺点。总结:唯一的区别就是LinkedHashMap多了一个双向循环链表也因此多了插入排序的功能。
所以一般情况下,我们用的最多的是HashMap,如果需要按照插入或者读取顺序来排列时就使用LinkedHashMap。
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
LinkedHashMap的成员变量
private static final long serialVersionUID = 3801124242820219131L; // 用于指向双向链表的头部 transient LinkedHashMap.Entry<K,V> head; //用于指向双向链表的尾部 transient LinkedHashMap.Entry<K,V> tail; /** * 用来指定LinkedHashMap的迭代顺序, * true则表示按照基于访问的顺序来排列,意思就是最近使用的entry,放在链表的最末尾 * false则表示按照插入顺序来 */ final boolean accessOrder;
二、LinkedHashMap的特点
1、能够保证插入元素的顺序
深入一点讲,有两种迭代元素的方式,一种是按照插入元素时的顺序迭代,比如,插入A,B,C,那么迭代也是A,B,C,另一种是按照访问顺序,比如,在迭代前,访问了B,那么迭代的顺序就是A,C,B,比如在迭代前,访问了B,接着又访问了A,那么迭代顺序为C,B,A,比如,在迭代前访问了B,接着又访问了B,然后在访问了A,迭代顺序还是C,B,A。要说明的意思就是不是近期访问的次数最多,就放最后面迭代,而是看迭代前被访问的时间长短决定。
2、内部存储的元素的模型
entry是下面这样的,相比HashMap,多了两个属性,一个before,一个after。next和after有时候会指向同一个entry,有时候next指向null,而after指向entry。这个具体后面分析。
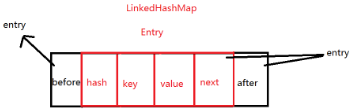
linkedHashMap和HashMap在存储操作上是一样的,但是LinkedHashMap多的东西是会记住在此之前插入的元素,这些元素不一定是在一个桶中
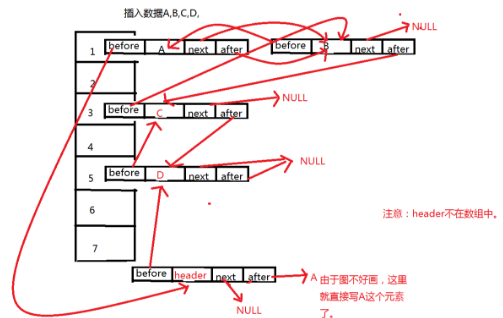
也就是说,对于linkedHashMap的基本操作还是和HashMap一样,在其上面加了两个属性,也就是为了记录前一个插入的元素和记录后一个插入的元素。也就是只要和hashmap一样进行操作之后把这两个属性的值设置好,就OK了。可以说LinkedHashMap就是HashMap+双向链表。注意一点,会有一个header的实体,目的是为了记录第一个插入的元素是谁,在遍历的时候能够找到第一个元素。
实际上的存储方式是和hashMap一样,但是同时增加了一个新的东西就是 双向循环链表。就是因为有了这个双向循环链表,LinkedHashMap才和HashMap不一样。
三、源码分析
1、内部存储元素的存储结构源码和理解LinkedHashMap双向循环链表
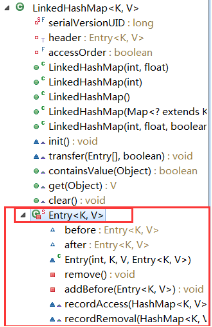
//LinkedHashMap的entry继承自HashMap的Entry。 private static class Entry<K,V> extends HashMap.Entry<K,V> { // These fields comprise the doubly linked list used for iteration. //通过上面这句源码的解释,我们可以知道这两个字段,是用来给迭代时使用的,相当于一个双向链表,实际上用的时候,操作LinkedHashMap的entry和操作HashMap的Entry是一样的,只操作相同的四个属性,这两个字段是由linkedHashMap中一些方法所操作。所以LinkedHashMap的很多方法度是直接继承自HashMap。 //before:指向前一个entry元素。after:指向后一个entry元素 Entry<K,V> before, after; //使用的是HashMap的Entry构造 Entry(int hash, K key, V value, HashMap.Entry<K,V> next) { super(hash, key, value, next); } //下面是维护这个双向循环链表的一些操作。在HashMap中没有这些操作,因为HashMap不需要维护, /** * Removes this entry from the linked list. */ //我们知道在双向循环链表时移除一个元素需要进行哪些操作把,比如有A,B,C,将B移除,那么A.next要指向c,c.before要指向A。下面就是进行这样的操作,但是会有点绕,他省略了一些东西。 //有的人会问,要是删除的是最后一个元素呢,那这个方法还适用吗?有这个疑问的人应该注意一下这个是双向循环链表,双向,删除哪个度适用。 private void remove() { //this.before.after = this.after; //this.after.before = this.before; 这样看可能会更好理解,this指的就是要删除的哪个元素。 before.after = after; after.before = before; } /** * Inserts this entry before the specified existing entry in the list. */ //插入一个元素之后做的一些操作,就是将第一个元素,和最后一个元素的一些指向改变。传进来的existingEntry就是header。 private void addBefore(Entry<K,V> existingEntry) { after = existingEntry; before = existingEntry.before; before.after = this; after.before = this; } /** * This method is invoked by the superclass whenever the value * of a pre-existing entry is read by Map.get or modified by Map.set. * If the enclosing Map is access-ordered, it moves the entry * to the end of the list; otherwise, it does nothing. */ //这个方法就是我们一开始说的,accessOrder为true时,就是使用的访问顺序,访问次数最少到访问次数最多,此时要做特殊处理。处理机制就是访问了一次,就将自己往后移一位,这里就是先将自己删除了,然后在把自己添加, //这样,近期访问的少的就在链表的开始,最近访问的元素就会在链表的末尾。如果为false。那么默认就是插入顺序,直接通过链表的特点就能依次找到插入元素,不用做特殊处理。 void recordAccess(HashMap<K,V> m) { LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m; if (lm.accessOrder) { lm.modCount++; remove(); addBefore(lm.header); } } void recordRemoval(HashMap<K,V> m) { remove(); } }
2、构造方法
有五个构造方法:
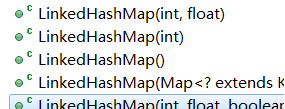
//使用父类中的构造,初始化容量和加载因子,该初始化容量是指数组大小。 public LinkedHashMap(int initialCapacity, float loadFactor) { super(initialCapacity, loadFactor); accessOrder = false; } //一个参数的构造 public LinkedHashMap(int initialCapacity) { super(initialCapacity); accessOrder = false; } //无参构造 public LinkedHashMap() { super(); accessOrder = false; } //这个不用多说,用来接受map类型的值转换为LinkedHashMap public LinkedHashMap(Map<? extends K, ? extends V> m) { super(m); accessOrder = false; } //真正有点特殊的就是这个,多了一个参数accessOrder。存储顺序,LinkedHashMap关键的参数之一就在这个, //true:指定迭代的顺序是按照访问顺序(近期访问最少到近期访问最多的元素)来迭代的。 false:指定迭代的顺序是按照插入顺序迭代,也就是通过插入元素的顺序来迭代所有元素 //如果你想指定访问顺序,那么就只能使用该构造方法,其他三个构造方法默认使用插入顺序。 public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); this.accessOrder = accessOrder; }
3、验证header的存在
//linkedHashMap中的init()方法,就使用header,hash值为-1,其他度为null,也就是说这个header不放在数组中,就是用来指示开始元素和标志结束元素的。 void init() { header = new Entry<>(-1, null, null, null); //一开始是自己指向自己,没有任何元素。HashMap中也有init()方法是个空的,所以这里的init()方法就是为LinkedHashMap而写的。 header.before = header.after = header; } //在HashMap的构造方法中就会使用到init(), public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; threshold = initialCapacity; init(); }
4、LinkedHashMap是如何和其父类HashMap共享一些方法的。比如,put操作等
LinkedHashMap构造方法完成后,调用put往其中添加元素,查看父类中的put源码
//这个方法应该挺熟悉的,如果看了HashMap的解析的话 public V put(K key, V value) { //刚开始其存储空间啥也没有,在这里初始化 if (table == EMPTY_TABLE) { inflateTable(threshold); } //key为null的情况 if (key == null) return putForNullKey(value); //通过key算hash,进而算出在数组中的位置,也就是在第几个桶中 int hash = hash(key); int i = indexFor(hash, table.length); //查看桶中是否有相同的key值,如果有就直接用新植替换旧值,而不用在创建新的entry了 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; //上面度是熟悉的东西,最重要的地方来了,就是这个方法,LinkedHashMap执行到这里,addEntry()方法不会执行HashMap中的方法,而是执行自己类中的addEntry方法,这里就要 提一下LinkedHashMap重写HashMap中两个个关键的方法了。看下面的分析。 addEntry(hash, key, value, i); return null; }
重写了void addEntry(int hash, K key, V value, int bucketIndex) 和void createEntry(int hash, K key, V value, int bucketIndex)
//重写的addEntry。其中还是会调用父类中的addEntry方法,但是此外会增加额外的功能, void addEntry(int hash, K key, V value, int bucketIndex) { super.addEntry(hash, key, value, bucketIndex); // Remove eldest entry if instructed Entry<K,V> eldest = header.after; if (removeEldestEntry(eldest)) { removeEntryForKey(eldest.key); } } //HashMap的addEntry,就是在将元素加入桶中前判断桶中的大小或者数组的大小是否合适,总之就是做一些数组容量上的判断和hash值的问题。 void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } //这里就是真正创建entry的时候了。也被LinkedHashMap重写了。 createEntry(hash, key, value, bucketIndex); } //重写的createEntry,这里要注意的是,新元素放桶中,是放第一位,而不是往后追加,所以下面方法中前面三行应该知道了 void createEntry(int hash, K key, V value, int bucketIndex) { HashMap.Entry<K,V> old = table[bucketIndex]; Entry<K,V> e = new Entry<>(hash, key, value, old); table[bucketIndex] = e; //这个方法的作用就是将e放在双向循环链表的末尾,需要将一些指向进行修改的操作。。 e.addBefore(header); size++; }
到这里,应该就对LinkedHashMap的存储过程有一定的了解了。并且也应该知道是如何存储的了。存储时有何特殊之处。
四、关于json序列化
Map<String,String> linkedMap = new LinkedHashMap<String,String>(); linkedMap.put("b","2"); linkedMap.put("a","1"); linkedMap.put("c","3"); String jsonStr = JSON.toJSONString(linkedMap); System.out.println(jsonStr); //输出:jsonStr={"a":"1","b":"2","c":"1"} Map<String,String> linkedMap1 = new LinkedHashMap<String,String>(); linkedMap1.put("b","2"); linkedMap1.put("a","1"); linkedMap1.put("c","3"); Gson gson = new Gsonbuilder.enableComplexMapKeySerialization().create(); String json1 = gson.toJson(linkedMap1); System.out.println(json1) //输出jsonStr1={"b":"2","a":"1","c":"3"}
上面两段代码的输出均正确。
虽然LinkedHashMap是有序的,但是使用JDK自带的JSON序列化类或者fastJson进行默认设置的JSON,序列化后默认是无序的,如果想要有序就需要特殊设置,而代码段2中有序是GSON保证的。
五、附加:注意LinkedHashMap的get()方法
这是一个来自实际项目的例子,在这个案例中,有同事基于jdk中的LinkedHashMap设计了一个LRUCache,为了提高性能,使用了 ReentrantReadWriteLock 读写锁:写锁对应put()方法,而读锁对应get()方法,期望通过读写锁来实现并发get()。
private ReentrantReadWriteLock lock = new ReentrantReadWriteLock (); lruMap = new LinkedHashMap<K, V>(initialCapacity, loadFactor, true) public V get(K key) { lock.readLock().lock(); try { return lruMap.get(key); } finally { lock.readLock().unlock(); } } public int entries() { lock.readLock().lock(); try { return lruMap.size(); } finally { lock.readLock().unlock(); } } public void put(K key, V value) { ... lock.writeLock().lock(); try { ... lruMap.put(key, value); ... } finally { lock.writeLock().unlock(); } }
在测试中发现问题,跑了几个小时系统就会hung up,无法接收http请求。在将把线程栈打印出来检查后,发现很多http的线程都在等读锁。有一个 runnable的线程hold了写锁,但一直停在LinkedHashMap.transfer方法里。线程栈信息如下:
"http-0.0.0.0-8081-178" daemon prio=3 tid=0x0000000004673000 nid=0x135 waiting on condition [0xfffffd7f5759c000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0xfffffd7f7cc86928> (a java.util.concurrent.locks.ReentrantReadWriteLock$NonfairSync) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:156) at java.util.concurrent.locks.AbstractQueuedSynchronizer.parkAndCheckInterrupt(AbstractQueuedSynchronizer.java:811) at java.util.concurrent.locks.AbstractQueuedSynchronizer.doAcquireShared(AbstractQueuedSynchronizer.java:941) at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireShared(AbstractQueuedSynchronizer.java:1261) at java.util.concurrent.locks.ReentrantReadWriteLock$ReadLock.lock(ReentrantReadWriteLock.java:594) ...... "http-0.0.0.0-8081-210" daemon prio=3 tid=0x0000000001422800 nid=0x155 runnable [0xfffffd7f5557c000] java.lang.Thread.State: RUNNABLE at java.util.LinkedHashMap.transfer(LinkedHashMap.java:234) at java.util.HashMap.resize(HashMap.java:463) at java.util.LinkedHashMap.addEntry(LinkedHashMap.java:414) at java.util.HashMap.put(HashMap.java:385) ......
大家都知道HashMap不是线程安全的,因此如果HashMap在多线程并发下,需要加互斥锁,如果put()不加锁,就很容易破坏内部链表,造成get()死循 环,一直hung住。这里有一个来自淘宝的例子,有对此现象的详细分析:https://gist.github.com/1081908
但是在MSDP的这个例子中,由于ReentrantReadWriteLock 读写锁的存在,put()和get()方法是互斥,不会有上述读写竞争的问题。
Google后发现这是个普遍存在的问题,其根结在于LinkedHashMap的get()方法会改变数据链表。我们来看一下LinkedHashMap的实现代码:
public V get(Object key) { Entry<K,V> e = (Entry<K,V>)getEntry(key); if (e == null) return null; e.recordAccess(this); return e.value; } void recordAccess(HashMap<K,V> m) { LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m; if (lm.accessOrder) { lm.modCount++; remove(); addBefore(lm.header); } } void transfer(HashMap.Entry[] newTable) { int newCapacity = newTable.length; for (Entry<K,V> e = header.after; e != header; e = e.after) { int index = indexFor(e.hash, newCapacity); e.next = newTable[index]; newTable[index] = e; } }
前面LRUCache的代码中,是这样初始化LinkedHashMap的:
lruMap = new LinkedHashMap<K, V>(initialCapacity, loadFactor, true)
LinkedHashMap构造函数中的参数true表明LinkedHashMap按照访问的次序来排序。这里所谓的按照访问的次序来排序的含义是:当调用LinkedHashMap 的get(key)或者put(key, value)时,如果key在map中被包含,那么LinkedHashMap会将key对象的entry放在线性结构的最后。正是因为LinkedHashMap提 供按照访问的次序来排序的功能,所以它才需要改写HashMap的get(key)方法(HashMap不需要排序)和HashMap.Entry的recordAccess(HashMap)方法。注 意addBefore(lm.header)是将该entry放在header线性表的最后。(参考LinkedHashMap.Entry extends HashMap.Entry 比起HashMap.Entry多了before, after两个域,是双向的)
在上面的LRUCache中,为了提供性能,通过使用ReentrantReadWriteLock读写锁实现了并发get(),结果导致了并发问题。解决问题的方式很简单, 去掉读写锁,让put()/get()都使用普通互斥锁就可以了。当然,这样get()方法就无法实现并发读了,对性能有所影响。
总结,在使用LinkedHashMap时,请小心LinkedHashMap的get()方法。
参考文章:
https://www.cnblogs.com/whgk/p/6169622.html
https://blog.csdn.net/zxw9202/article/details/79022010
https://blog.csdn.net/wawmg/article/details/19482041

