阿里规定超过三张表禁止join
一、 问题提出
《阿里巴巴JAVA开发手册》里面写超过三张表禁止join,这是为什么?

二、问题分析
对这个结论,你是否有怀疑呢?也不知道是哪位先哲说的不要人云亦云,今天我设计sql,来验证这个结论。(实验没有从代码角度分析,目前达不到。可以把mysql当一个黑盒,使用角度来验证这个结论) 验证结论的时候,会有很多发现,各位往后看。
三、 实验环境
vmware10+centos7.4+mysql5.7.22
-
centos7内存4.5G,4核,50G硬盘。
-
mysql配置为2G,特别说明硬盘是SSD。
四、我概述下我的实验
有4张表,student学生表,teacher老师表,course课程表,sc中间关系表,记录了学生选修课程以及分数。具体sql脚本,看文章结尾,我附上。中间我自己写了造数据的脚本,也在结尾。
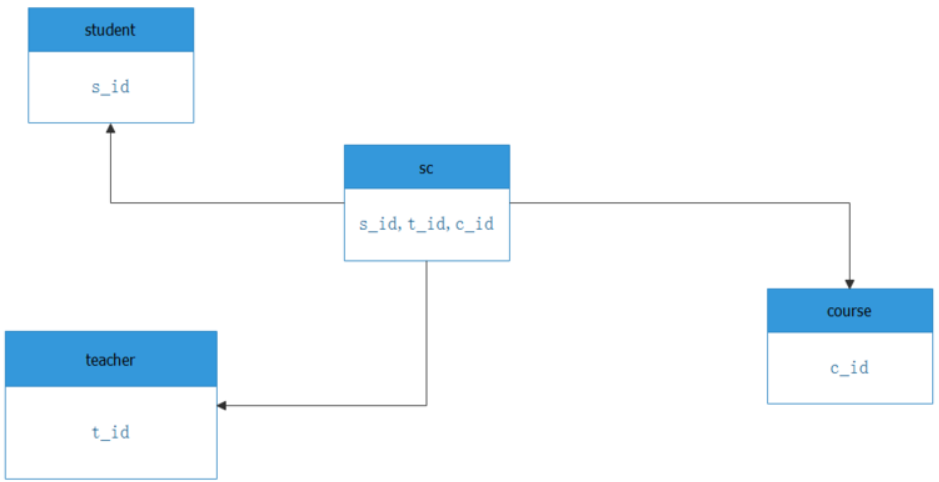
实验是为解决一个问题的:查询选修“tname553”老师所授课程的学生中,成绩最高的学生姓名及其成绩。
查询sql是:
select Student.Sname,course.cname,score from Student,SC,Course ,Teacher where Student.s_id=SC.s_id and SC.c_id=Course.c_id and sc.t_id=teacher.t_id and Teacher.Tname='tname553' and SC.score=(select max(score)from SC where sc.t_id=teacher.t_Id);
我来分析一下这个语句:4张表等值join,还有一个子查询。算是比较简单的sql语句了(相比ERP动就10张表的哦,已经很简单了)。我 还会分解这个语句成3个简单的sql:

select max(score) from SC ,Teacher where sc.t_id=teacher.t_Id and Teacher.Tname='tname553';
select sc.t_id,sc.s_id,score from SC ,Teacher where sc.t_id=teacher.t_Id and score=590 and Teacher.Tname='tname553';
select Student.Sname,course.cname,score from Student,SC ,course where Student.s_id=SC.s_id and sc.s_id in (20769800,48525000,26280200) and course.c_id = sc.c_id;
我来分析下:第一句,就是查询最高分,得到最高分590分。第二句就是查询出最高分的学生id,得到
20769800,48525000,26280200
第三句就是查询出学生名字和分数。这样这3个语句的就可以查询出来 成绩最高的学生姓名及其成绩 。
接下来我会分别造数据:1千万选课记录(一个学生选修2门课),造500万学生,100万老师(一个老师带5个学生,挺高端的吧),1000门课,。用上面查询语句查询。其中sc表我测试了下有索引和没有索引情况,具体见下表。
再接下来,我会造1亿选课记录(一个学生选修2门课),5000万学生,1000万老师,1000门课。然后分别执行上述语句。最后我会在oracle数据库上执行上述语句。
五、下面两张表是测试结果
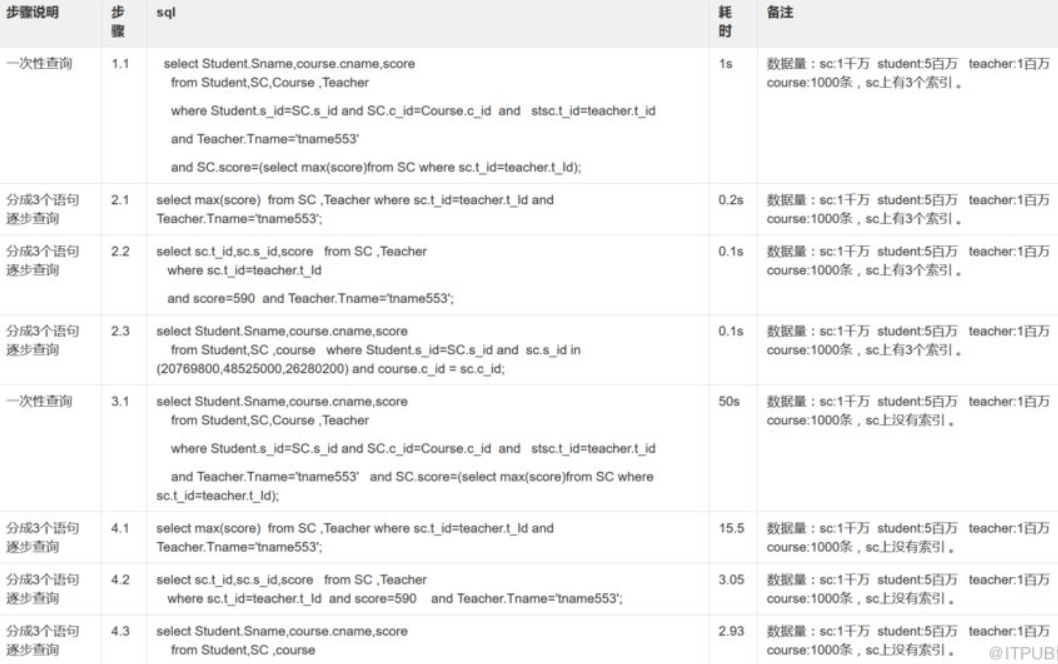

六、仔细看上表,可以发现
1.步骤3.1没有在连接键上加索引,查询很慢,说明:“多表关联查询时,保证被关联的字段需要有索引”;
2.步骤6.1,6.2,6.3,换成简单sql,在数据量1亿以上, 查询时间还能勉强接受。此时说明mysql查询有些吃力了,但是仍然嫩查询出来。
3.步骤5.1,mysql查询不出来,4表连接,对我本机mysql来说,1.5亿数据超过极限了(我调优过这个SQL,执行计划和索引都走了,没有问题,show profile显示在sending data.这个问题另外文章详谈。)
4.对比1.1 和5.1 步骤sql查询,4表连接,对我本机mysql来说 ,1.5千万数据查询很流利,是一个mysql数据量流利分水岭。(这个只是现象,不太准确,需要同时计算表的容量)。
5.步骤5.1对比6.1,6.2,6.3,多表join对mysql来说,处理有些吃力。
6.超过三张表禁止join,这个规则是针对mysql来说的。后续会看到我用同样机器,同样数据量,同样内存,可以完美计算 1.5亿数据量join。针对这样一个规则,对开发来说 ,需要把一些逻辑放到应用层去查询。
总结: 这个规则 超过三张表禁止join ,由于数据量太大的时候,mysql根本查询不出来,导致阿里出了这样一个规定。(其实如果表数据量少,10张表也不成问题,你自己可以试试)而我们公司支付系统朝着大规模高并发目标设计的,所以,遵循这个规定。
在业务层面来讲,写简单sql,把更多逻辑放到应用层,我的需求我会更了解,在应用层实现特定的join也容易得多。
参考文章:
https://mp.weixin.qq.com/s/9l2r1vWsIKxG3FIPuSlVHg



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架