JDK的运行时常量池、字符串常量池、静态常量池
首先汇总一下JDK的运行时常量池、字符串常量池、静态常量池的功能及存储结构。
一、JVM运行时内存结构
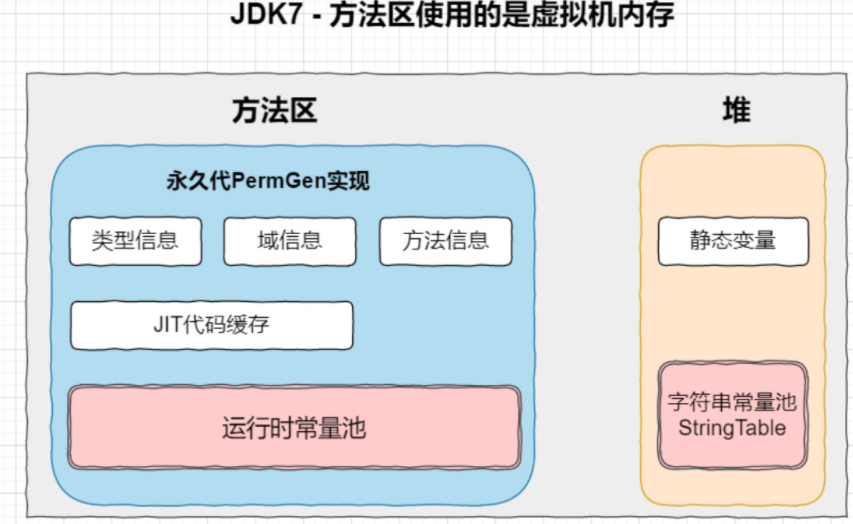
在了解常量池之前我们先通过一张图了解一下JVM的整个内存分布图。下图为JDK7的内存结构:
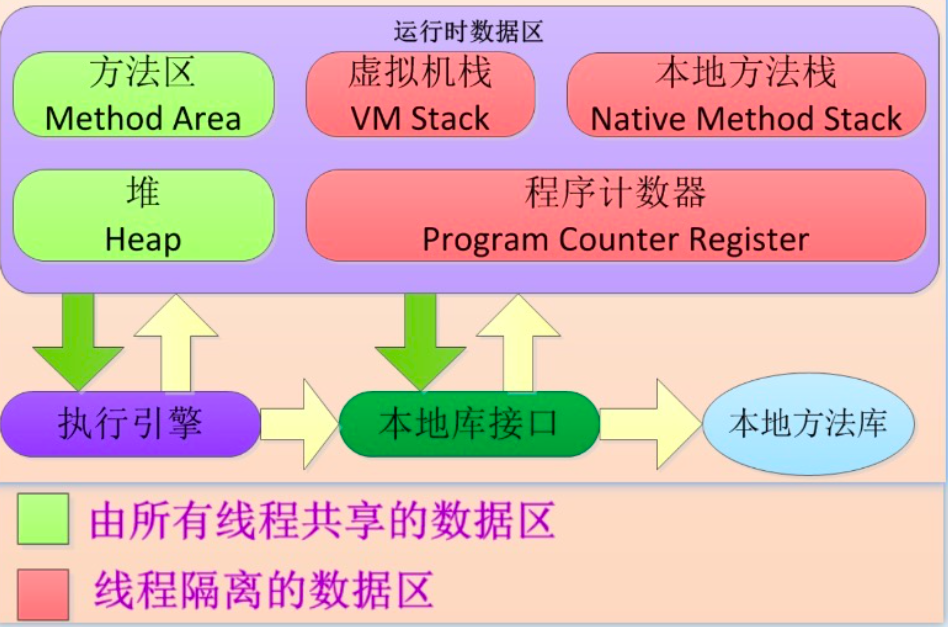
在上图中JVM所管理的内存主要包括以下区域:程序计数器(Program Counter Register)、虚拟机栈(VM Stack)、本地方法栈(Native Method Stack)、方法区(Method Area)、堆(Heap)。
不同版本的JVM的内存结构有不同的变化,这些变化对我们今天要讲的三个概念会有所影响,后面我们会逐一讲解。
了解了JVM内存结构,那么运行时常量池、字符串常量池、静态常量池对于的都位于JVM的什么区域呢?先来看看它们的定义及功能。
二、静态常量池
Java程序要运行时,需要编译器先将源代码文件编译成字节码(.class)文件,然后在由JVM解释执行。
class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池(Constant pool table),用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入运行时常量池中存放。
静态常量池就是上面说的class文件中的常量池。class常量池是在编译时每个class文件中都存在。不同的符号信息放置在不同标志的常量表中。
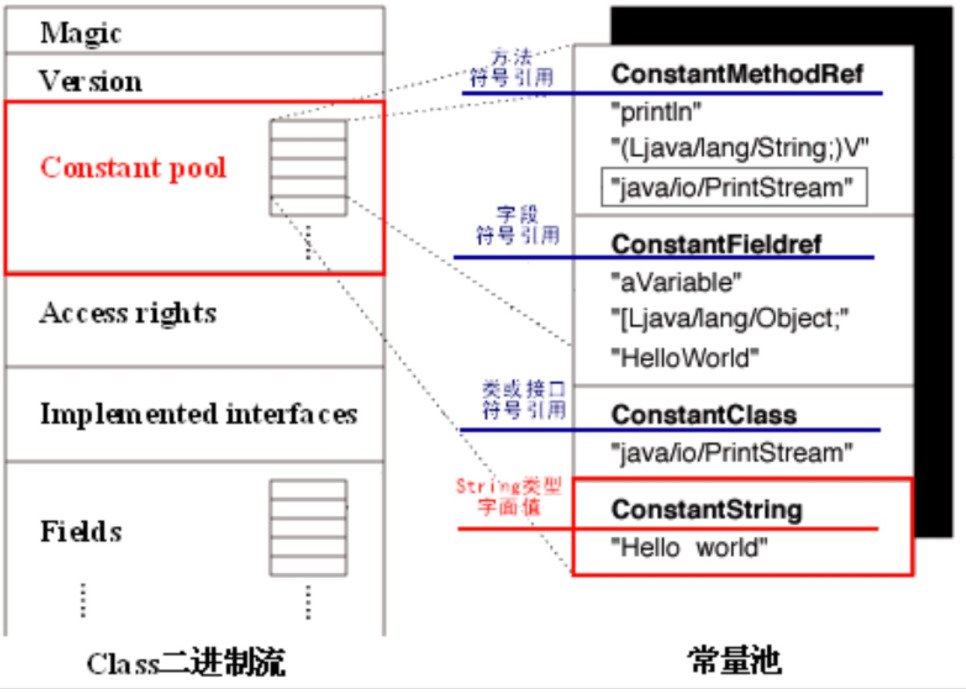
常量池中存放的符号信息,在JVM执行指令时需要依赖使用。常量池中的所有项都具有如下通用格式:
cp_info { u1 tag; //表示cp_info的单字节标记位 u1 info[]; //两个或更多的字节表示这个常量的信息,信息格式由tag的值确定 }
支持的类型信息如下:
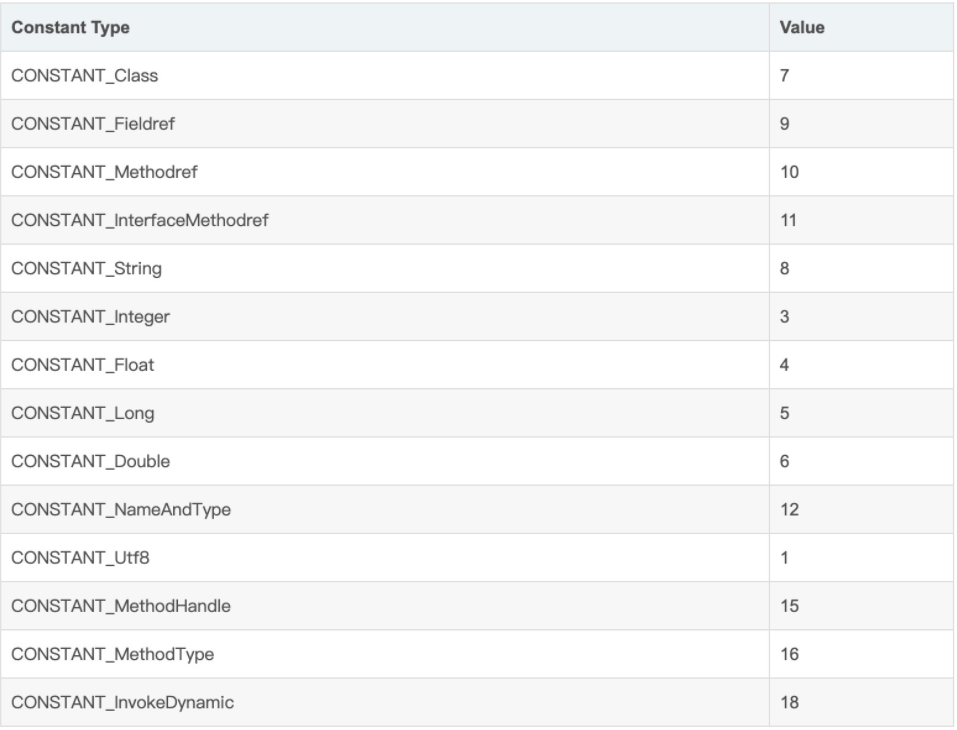
以CONSTANT_Class为例,它用于表示类或者接口,格式如下:
CONSTANT_Class_info { u1 tag; //这个值为CONSTANT_Class (7) u2 name_index;//一个index,表示一个索引,引用的是CONSTANT_UTF8_info }
CONSTANT_Class_info类型是由一个tag和一个name_index组成。name_index中的index表示它是一个索引,引用的是CONSTANT_UTF8_info。
CONSTANT_Utf8_info用于表示字符常量的值,结构如下所示:
CONSTANT_Utf8_info {
u1 tag;
u2 length;
u1 bytes[length];
}
tag表示为:CONSTANT_Utf8(1);length指明了bytes[]数组的长度;bytes[]数组引用了上一个length作为其长度。字符常量采用改进过的UTF-8编码表示。
对于静态常量池我们需要知道它存在于编译器,如果说与运行时有关的话,可以说运行时中的常量是JVM加载class文件之后进行分配的。
三、运行时常量池
运行时常量池就是将编译后的类信息放入方法区中,也就是说它是方法区的一部分。
运行时常量池用来动态获取类信息,包括:class文件元信息描述、编译后的代码数据、引用类型数据、类文件常量池等。
运行时常量池是在类加载完成之后,将每个class常量池中的符号引用值转存到运行时常量池中。每个class都有一个运行时常量池,类在解析之后将符号引用替换成直接引用,与全局常量池中的引用值保持一致。
运行时常量池相对于class文件常量池的另外一个特性是具备动态性,java语言并不要求常量一定只有编译器才产生,也就是并非预置入class文件中常量池的内容才能进入方法区运行时常量池,运行期间也可能将新的常量放入池中。
四、字符串常量池
字符串池里的内容是在类加载完成,经过验证、准备阶段之后存放在字符串常量池中。关于字符串常量池的具体实现我们这里先不展开,后面用专门的文章来进行讲解。
字符串常量池的处理机制我们前面文章已经讲到,只会存储一份,被所有的类共享。基本流程是:创建字符串之前检查常量池中是否存在,如果存在则获取其引用,如果不存在则创建并存入,返回新对象引用。
字符串常量池随着JDK版本的演化所在的位置也在不断的变化,下面我们会专门用图讲解一下。
五、常量池内存位置演化
在JDK1.7之前运行时常量池逻辑包含字符串常量池存放在方法区, 此时hotspot虚拟机对方法区的实现为永久代。
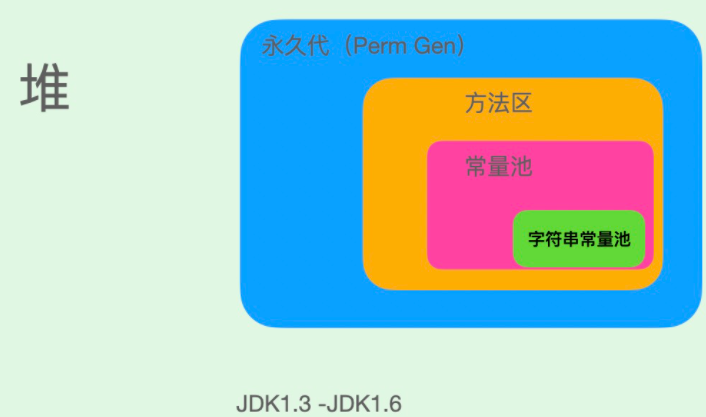
在JDK1.7字符串常量池和静态变量被从方法区拿到了堆中,运行时常量池剩下的还在方法区, 也就是hotspot中的永久代。
在JDK8 hotspot移除了永久代用元空间(Metaspace)取而代之, 这时候字符串常量池还在堆,运行时常量池还在方法区,只不过方法区的实现从永久代变成了元空间(Metaspace)。
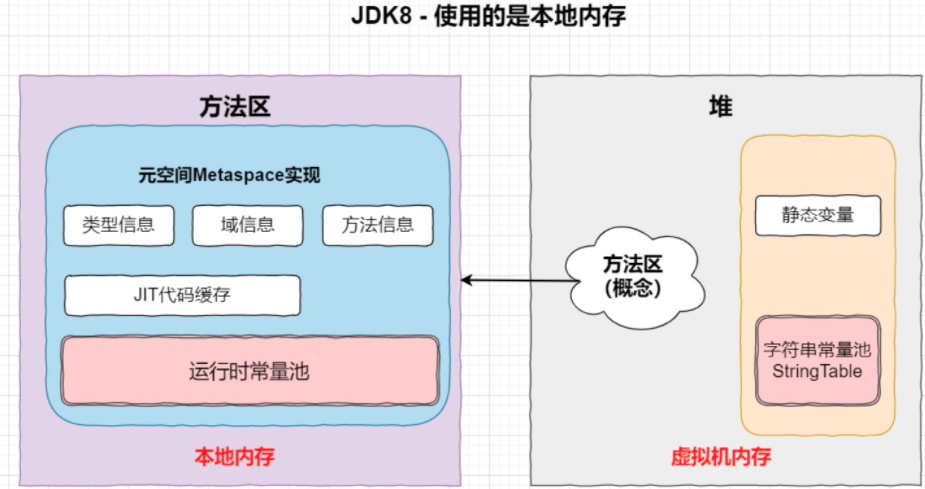
通过上面的图解,我们可以轻易得知在不同的版本中方法区及内部组成部分是在不断变化的。
总结一下就是:
静态变量处于编译器,存在于class文件内,可通过javap verbose命令查看字符串合并时查看的是静态常量池里面的内容;字符串常量池曾经属于运行时常量池的一部分,位于方法区,但随着JVM版本的演变,二者已经分开。在JDK8以后字符串常量池位于堆中,而运行时常量池位于方法区。
六、字符串常量池介绍
在 Java 世界中,构造一个 Java 对象是一个相对比较重的活,而且还需要垃圾回收,而缓存池就是为了缓解这个问题的。
我们来看下基础类型的包装类的缓存,Integer 默认缓存 -128 ~ 127 区间的值,Long 和 Short 也是缓存了这个区间的值,Byte 只能表示 -127 ~ 128 范围的值,全部缓存了,Character 缓存了 0 ~ 127 的值。Float 和 Double 没有缓存的意义。
Integer 可通过设置 java.lang.Integer.IntegerCache.high 扩大缓存区间
String 不是基础类型,但是它也有同样的机制,通过 String Pool 来缓存 String 对象。假设 “Java” 这个字符串我们会在应用程序中使用多次,我们肯定不希望在每次使用到的时候,都重新在堆中创建一个新的对象。
当然,之所以 Integer、Long、String 这些类的对象可以缓存,是因为它们是不可变类
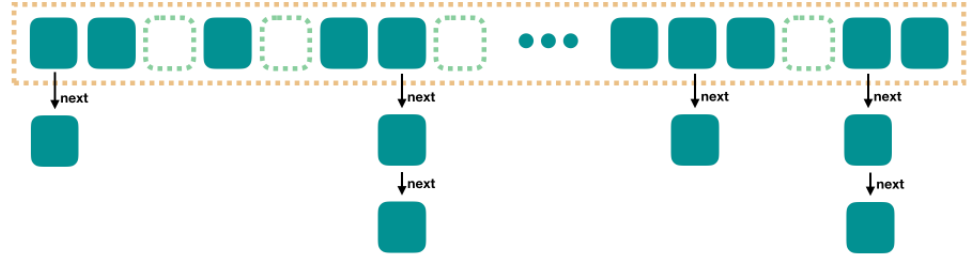
基础类型包装类的缓存池使用一个数组进行缓存,而 String 类型,JVM 内部使用 HashTable 进行缓存,我们知道,HashTable 的结构是一个数组,数组中每个元素是一个链表。和我们平时使用的 HashTable 不同,JVM 内部的这个 HashTable 是不可以动态扩容的。
1、创建和回收
当我们在程序中使用双引号来表示一个字符串时,这个字符串就会进入到 String Pool 中。当然,这里说的是已被加载到 JVM 中的类。
另外,就是 String#intern() 方法,这个方法的作用就是:
- 如果字符串未在 Pool 中,那么就往 Pool 中增加一条记录,然后返回 Pool 中的引用。
- 如果已经在 Pool 中,直接返回 Pool 中的引用。
只要 String Pool 中的 String 对象对于 GC Roots 来说不可达,那么它们就是可以被回收的。
如果 Pool 中对象过多,可能导致 YGC 变长,因为 YGC 的时候,需要扫描 String Pool,可以看看笨神大佬的文章《JVM源码分析之String.intern()导致的YGC不断变长》。
2、讨论 String Pool 的实现
1、首先,我们先考虑 String Pool 的空间问题。
在 Java 6 中,String Pool 置于 PermGen Space 中,PermGen 有一个问题,那就是它是一个固定大小的区域,虽然我们可以通过 -XX:MaxPermSize=N 来设置永久代的空间大小,但是不管我们设置成多少,它终归是固定的。
所以,在 Java 6 中,我们应该尽量小心使用 String.intern() 方法,否则容易导致 OutOfMemoryError。
到了 Java 7,大佬们已经着手去掉 PermGen Space 了,首先,就是将 String Pool 移到了堆中。
把 String Pool 放到堆中,即使堆的大小也是固定的,但是这个时候,对于应用调优工作,只需要调整堆大小就行了。
到了 Java 8,PermGen 已经被彻底废弃,出现了堆外内存区域 MetaSpace,String Pool 相应的从堆转移到了 MetaSpace 中。
在 Java 8 中,String Pool 依然还是在 Heap Space 中。感谢评论区的读者指出错误。大家可以看一下我后面写的关于 MetaSpace 的文章,那篇文章深入分析了 MetaSpace 的构成。
2、其次,我们再讨论 String Pool 的实现问题。
前面我们说了 String Pool 使用一个 HashTable 来实现,这个 HashTable 不可以扩容,也就意味着极有可能出现单个 bucket 中的链表很长,导致性能降低。
在 Java 6 中,这个 HashTable 固定的 bucket 数量是 1009,后来添加了选项(-XX:StringTableSize=N)可以配置这个值。到 Java 7(7u40),大佬们提高了这个默认值到 60013,Java 8 依然也是使用这个值,对于绝大部分应用来说,这个值是足够用的。当然,如果你会在代码中大量使用 String#intern(),那么有必要手动设置一下这个值。
为什么是 1009,而不是 1000 或者 1024?因为 1009 是质数,有利于达到更好的散列。60013 同理。
JVM 内部的 HashTable 是不扩容的,但是不代表它不 rehash,它会在发现散列不均匀的时候进行 rehash,这里不展开介绍。
3、观察 String Pool 的使用情况。
JVM 提供了 -XX:+PrintStringTableStatistics 启动参数来帮助我们获取统计数据。
遗憾的是,只有在 JVM 退出的时候,JVM 才会将统计数据打印出来,JVM 没有提供接口给我们实时获取统计数据。
SymbolTable statistics: Number of buckets : 20011 = 160088 bytes, avg 8.000 Number of entries : 10923 = 262152 bytes, avg 24.000 Number of literals : 10923 = 425192 bytes, avg 38.926 Total footprint : = 847432 bytes Average bucket size : 0.546 Variance of bucket size : 0.545 Std. dev. of bucket size: 0.738 Maximum bucket size : 6 ## 看下面这部分: StringTable statistics: Number of buckets : 60003 = 480024 bytes, avg 8.000 Number of entries : 4000774 = 96018576 bytes, avg 24.000 Number of literals : 4000774 = 1055252184 bytes, avg 263.762 Total footprint : = 1151750784 bytes Average bucket size : 66.676 Variance of bucket size : 19.843 Std. dev. of bucket size: 4.455 Maximum bucket size : 84
统计数据中包含了 buckets 的数量,总的 String 对象的数量,占用的总空间,单个 bucket 的链表平均长度和最大长度等。
上面的数据是在 Java 8 的环境中打印出来的,Java 7 的信息稍微少一些,主要是没有 footprint 的数据:
StringTable statistics: Number of buckets : 60003 Average bucket size : 67 Variance of bucket size : 20 Std. dev. of bucket size: 4 Maximum bucket size : 84
3、测试 String Pool 的性能
接下来,我们来跑个测试,测试下 String Pool 的性能问题,并讨论 -XX:StringTableSize=N 参数的作用。
我们将使用 String#intern() 往字符串常量池中添加 400万 个不同的长字符串。
package com.javadoop; import java.lang.ref.WeakReference; import java.util.ArrayList; import java.util.List; import java.util.WeakHashMap; public class StringTest { public static void main(String[] args) { test(4000000); } private static void test(int cnt) { final List<String> lst = new ArrayList<String>(1024); long start = System.currentTimeMillis(); for (int i = 0; i < cnt; ++i) { final String str = "Very very very very very very very very very very very very very very " + "very long string: " + i; lst.add(str.intern()); if (i % 200000 == 0) { System.out.println(i + 200000 + "; time = " + (System.currentTimeMillis() - start) / 1000.0 + " sec"); start = System.currentTimeMillis(); } } System.out.println("Total length = " + lst.size()); } }
我们每插入 20万 条数据,输出一次耗时。
# 编译 javac -d . StringTest.java # 使用默认 table size (60013) 运行一次 java -Xms2g -Xmx2g com.javadoop.StringTest # 设置 table size 为 400031,再运行一次 java -Xms2g -Xmx2g -XX:StringTableSize=400031 com.javadoop.StringTest
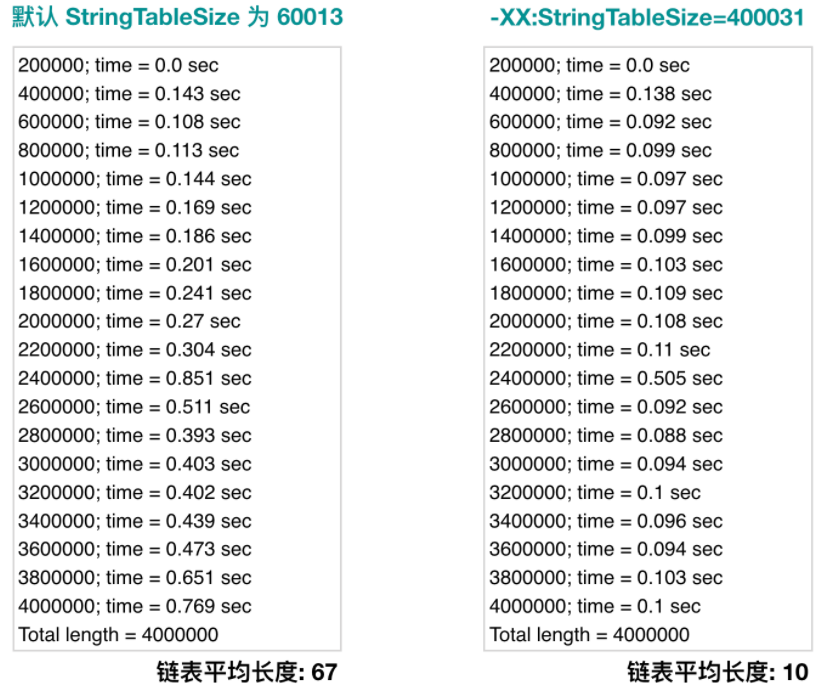
从左右两部分数据可以很直观看出来,插入的性能主要取决于链表的平均长度。当链表平均长度为 10 的时候,我们看到性能是几乎没有任何损失的。
还是那句话,根据自己的实际情况,考虑是否要设置 -XX:StringTableSize=N,还是使用默认值。
4、讨论自建 String Pool
这一节我们来看下自己使用 HashMap 来实现 String Pool。
这里我们需要使用 WeakReference:
private static final WeakHashMap<String, WeakReference<String>> pool = new WeakHashMap<String, WeakReference<String>>(1024); private static String manualIntern(final String str) { final WeakReference<String> cached = pool.get(str); if (cached != null) { final String value = cached.get(); if (value != null) { return value; } } pool.put(str, new WeakReference<String>(str)); return str; }
我们使用 1000 * 1000 * 1000 作为入参 cnt 的值进行测试,分别测试 [1] 和 [2]:
private static void test(int cnt) { final List<String> lst = new ArrayList<String>(1024); long start = System.currentTimeMillis(); for (int i = 0; i < cnt; ++i) { // [1] lst.add(String.valueOf(i).intern()); // [2] // lst.add(manualIntern(String.valueOf(i))); if (i % 200000 == 0) { System.out.println(i + 200000 + "; time = " + (System.currentTimeMillis() - start) / 1000.0 + " sec"); start = System.currentTimeMillis(); } } System.out.println("Total length = " + lst.size()); }
测试结果,2G 的堆大小,如果使用 String#intern(),大概在插入 3000万 数据的时候,开始进入大量的 FullGC。
而使用自己写的 manualIntern(),大概到 1400万 的时候,就已经不行了。
没什么结论,如果要说点什么的话,那就是不要自建 String Pool,没必要。
5、小结
记住有两个 JVM 参数可以设置:-XX:StringTableSize=N、-XX:+PrintStringTableStatistics
StringTableSize,在 Java 6 中,是 1009;在 Java 7 和 Java 8 中,默认都是 60013,如果有必要请自行扩大这个值。
七、NEW STRING()创建几个对象问题探讨
1、常见面试问题
下面代码中创建了几个对象?
new String("abc");
答案众说纷纭,有说创建了1个对象,也有说创建了2个对象。答案对,也不对,关键是要学到问题底层的原理。
2、底层原理分析
String的两种初始化形式是有本质区别的
String str1 = "abc"; // 在常量池中 String str2 = new String("abc"); // 在堆上
当直接赋值时,字符串“abc”会被存储在常量池中,只有1份,此时的赋值操作等于是创建0个或1个对象。如果常量池中已经存在了“abc”,那么不会再创建对象,直接将引用赋值给str1;如果常量池中没有“abc”,那么创建一个对象,并将引用赋值给str1。
那么,通过new String(“abc”);的形式又是如何呢?答案是1个或2个。
当JVM遇到上述代码时,会先检索常量池中是否存在“abc”,如果不存在“abc”这个字符串,则会先在常量池中创建这个一个字符串。然后再执行new操作,会在堆内存中创建一个存储“abc”的String对象,对象的引用赋值给str2。此过程创建了2个对象。
当然,如果检索常量池时发现已经存在了对应的字符串,那么只会在堆内创建一个新的String对象,此过程只创建了1个对象。
在上述过程中检查常量池是否有相同Unicode的字符串常量时,使用的方法便是String中的intern()方法。
public native String intern();
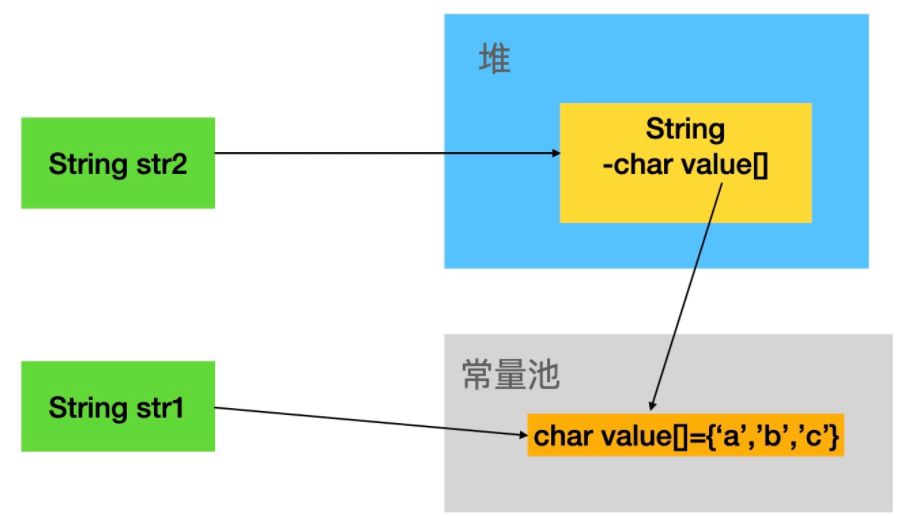
下面通过一个简单的示意图看一下String在内存中的两种存储模式。
上面的示意图我们可以看到在堆内创建的String对象的char value[]属性指向了常量池中的char value[]。
还是上面的示例,如果我们通过debug模式也能够看到String的char value[]的引用地址。
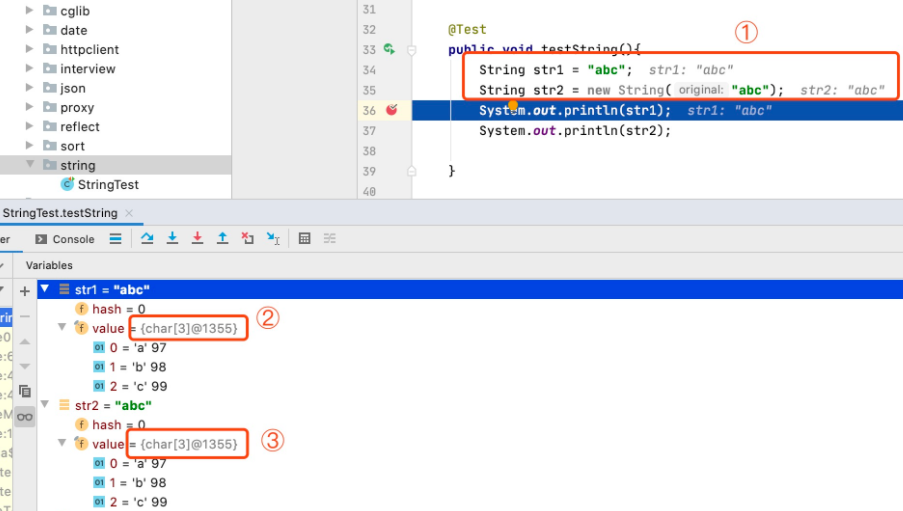
图中两个String对象的value值的引用均为{char[3]@1355},也就是说,虽然是两个对象,但它们的value值均指向常量池中的同一个地址。当然,大家还可以拿一个复杂对象(Person)的字符串属性(name)相同时的debug结果进行比对,结果是一样的。
3、深入问法
如果面试官说程序的代码只有下面一行,那么会创建几个对象?
new String("abc");
答案是2个?
还真不一定。之所以单独列出这个问题是想提醒大家一点:没有直接的赋值操作(str=”abc”),并不代表常量池中没有“abc”这个字符串。也就是说衡量创建几个对象、常量池中是否有对应的字符串,不仅仅由你是否创建决定,还要看程序启动时其他类中是否包含该字符串。
4、升级加码
以下实例我们暂且不考虑常量池中是否已经存在对应字符串的问题,假设都不存在对应的字符串。
以下代码会创建几个对象:
String str = "abc" + "def";
上面的问题涉及到字符串常量重载“+”的问题,当一个字符串由多个字符串常量拼接成一个字符串时,它自己也肯定是字符串常量。字符串常量的“+”号连接Java虚拟机会在程序编译期将其优化为连接后的值。
就上面的示例而言,在编译时已经被合并成“abcdef”字符串,因此,只会创建1个对象。并没有创建临时字符串对象abc和def,这样减轻了垃圾收集器的压力。
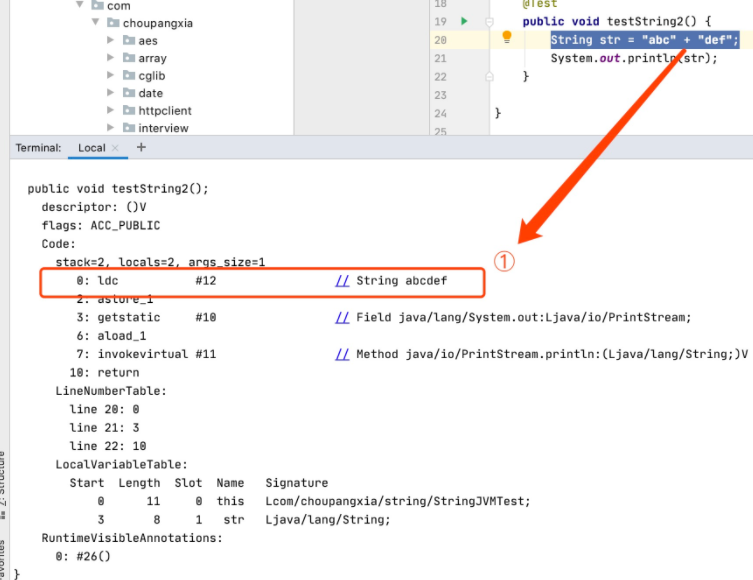
我们通过javap查看class文件可以看到如下内容。
很明显,字节码中只有拼接好的abcdef。
针对上面的问题,我们再次升级一下,下面的代码会创建几个对象?
String str = "abc" + new String("def");
创建了4个,5个,还是6个对象?
4个对象的说法:常量池中分别有“abc”和“def”,堆中对象new String(“def”)和“abcdef”。
这种说法对吗?不完全对,如果说上述代码创建了几个字符串对象,那么可以说是正确的。但上述的代码Java虚拟机在编译的时候同样会优化,会创建一个StringBuilder来进行字符串的拼接,实际效果类似:
String s = new String("def"); new StringBuilder().append("abc").append(s).toString();
很显然,多出了一个StringBuilder对象,那就应该是5个对象。
那么创建6个对象是怎么回事呢?有同学可能会想了,StringBuilder最后toString()之后的“abcdef”难道不在常量池存一份吗?
这个还真没有存,我们来看一下这段代码:
@Test public void testString3() { String s1 = "abc"; String s2 = new String("def"); String s3 = s1 + s2; String s4 = "abcdef"; System.out.println(s3==s4); // false }
按照上面的分析,如果s1+s2的结果在常量池中存了一份,那么s3中的value引用应该和s4中value的引用是一样的才对。下面我们看一下debug的效果。
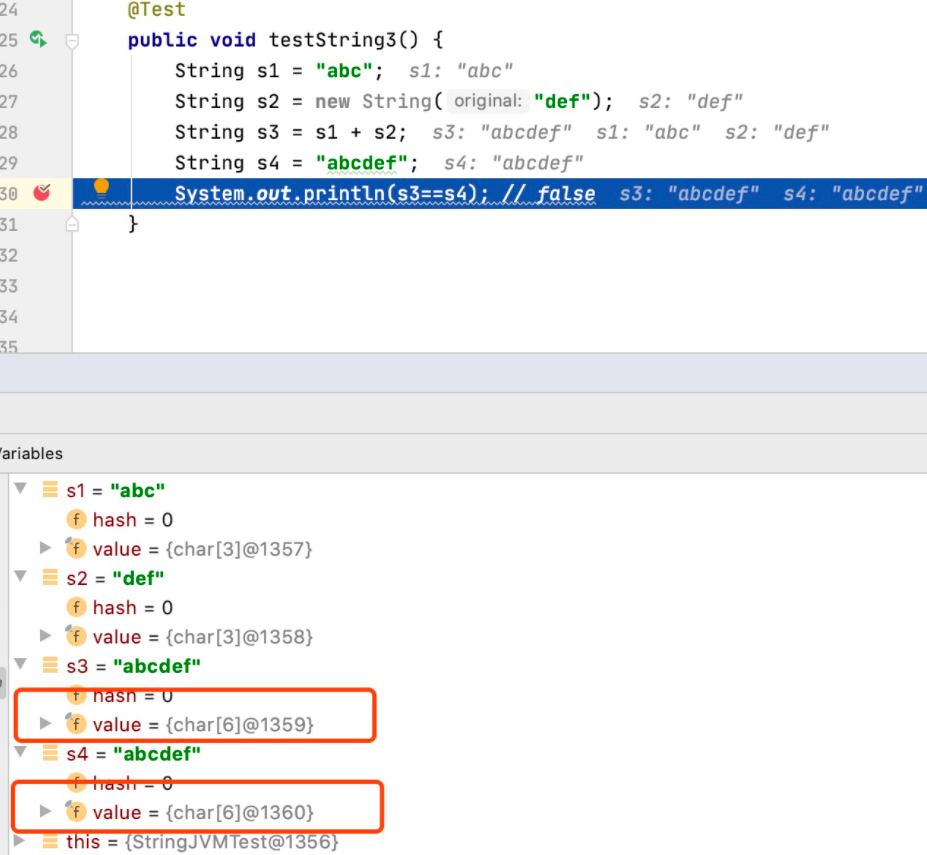
很明显,s3和s4的值相同,但value值的地址并不相同。即便是将s3和s4的位置调整一下,效果也一样。s4很明确是存在于常量池中,那么s3对应的值存储在哪里呢?很显然是在堆对象中。
我们来看一下StringBuilder的toString()方法是如何将拼接的结果转化为字符串的:
@Override public String toString() { // Create a copy, don't share the array return new String(value, 0, count); }
很显然,在toString方法中又新创建了一个String对象,而该String对象传递数组的构造方法来创建的:
public String(char value[], int offset, int count)
也就是说,String对象的value值直接指向了一个已经存在的数组,而并没有指向常量池中的字符串。
因此,上面的准确回答应该是创建了4个字符串对象和1个StringBuilder对象。
参考文章:
http://www.choupangxia.com/2020/08/28/jvm-string-pool
http://www.choupangxia.com/2020/08/28/java-string
http://www.choupangxia.com/2020/08/25/new-string

