Redis为什么是单线程,高并发快的3大原因详解
一、Redis的高并发和快速原因
1.redis是基于内存的,内存的读写速度非常快;
2.redis是单线程的,省去了很多上下文切换线程的时间;
3.redis使用多路复用技术,可以处理并发的连接。非阻塞IO 内部实现采用epoll,采用了epoll+自己实现的简单的事件框架。epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特性,绝不在io上浪费一点时间。
下面重点介绍单线程设计和IO多路复用核心设计快的原因。
1、为什么Redis是单线程的
1.官方答案
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
2.性能指标
关于redis的性能,官方网站也有,普通笔记本轻松处理每秒几十万的请求。
3.详细原因
1)不需要各种锁的性能消耗
Redis的数据结构并不全是简单的Key-Value,还有list,hash等复杂的结构,这些结构有可能会进行很细粒度的操作,比如在很长的列表后面添加一个元素,在hash当中添加或者删除
一个对象。这些操作可能就需要加非常多的锁,导致的结果是同步开销大大增加。
总之,在单线程的情况下,就不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。
2)单线程多进程集群方案
单线程的威力实际上非常强大,每核心效率也非常高,多线程自然是可以比单线程有更高的性能上限,但是在今天的计算环境中,即使是单机多线程的上限也往往不能满足需要了,需要进一步摸索的是多服务器集群化的方案,这些方案中多线程的技术照样是用不上的。
所以单线程、多进程的集群不失为一个时髦的解决方案。
3)CPU消耗
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU。
但是如果CPU成为Redis瓶颈,或者不想让服务器其他CUP核闲置,那怎么办?
可以考虑多起几个Redis进程,Redis是key-value数据库,不是关系数据库,数据之间没有约束。只要客户端分清哪些key放在哪个Redis进程上就可以了。
2、Redis单线程的优劣势
单线程模型
Redis客户端对服务端的每次调用都经历了发送命令,执行命令,返回结果三个过程。其中执行命令阶段,由于Redis是单线程来处理命令的,所有每一条到达服务端的命令不会立刻执行,所有的命令都会进入一个队列中,然后逐个被执行。并且多个客户端发送的命令的执行顺序是不确定的。但是可以确定的是不会有两条命令被同时执行,不会产生并发问题,这就是Redis的单线程基本模型。
单进程单线程优势
- 代码更清晰,处理逻辑更简单
- 不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
- 不存在多进程或者多线程导致的切换而消耗CPU
单进程单线程弊端
- 无法发挥多核CPU性能,不过可以通过在单机开多个Redis实例来完善;
2、IO多路复用技术
redis 采用网络IO多路复用技术来保证在多连接的时候, 系统的高吞吐量。
多路-指的是多个socket连接,复用-指的是复用一个线程。多路复用主要有三种技术:select,poll,epoll。epoll是最新的也是目前最好的多路复用技术。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的吞吐量。
二、Redis高并发快总结
1. Redis是纯内存数据库,一般都是简单的存取操作,线程占用的时间很多,时间的花费主要集中在IO上,所以读取速度快。
2. 再说一下IO,Redis使用的是非阻塞IO,IO多路复用,使用了单线程来轮询描述符,将数据库的开、关、读、写都转换成了事件,减少了线程切换时上下文的切换和竞争。
3. Redis采用了单线程的模型,保证了每个操作的原子性,也减少了线程的上下文切换和竞争。
4. 另外,数据结构也帮了不少忙,Redis全程使用hash结构,读取速度快,还有一些特殊的数据结构,对数据存储进行了优化,如压缩表,对短数据进行压缩存储,再如,跳表,使用有序的数据结构加快读取的速度。
5. 还有一点,Redis采用自己实现的事件分离器,效率比较高,内部采用非阻塞的执行方式,吞吐能力比较大。
以上就是redis高并发快的详解。
三、IO多路复用探讨
1、基础知识
操作系统
内核和用户空间
首先,内核和用户空间都在内存中
IO
2、举例说明
假设你是一个机场的空管, 你需要管理到你机场的所有的航线, 包括进港,出港, 有些航班需要放到停机坪等待,有些航班需要去登机口接乘客。
你会怎么做?
最简单的做法,就是你去招一大批空管员,然后每人盯一架飞机, 从进港,接客,排位,出港,航线监控,直至交接给下一个空港,全程监控。
那么问题就来了:- 很快你就发现空管塔里面聚集起来一大票的空管员,交通稍微繁忙一点,新的空管员就已经挤不进来了。
- 空管员之间需要协调,屋子里面就1, 2个人的时候还好,几十号人以后 ,基本上就成菜市场了。
- 空管员经常需要更新一些公用的东西,比如起飞显示屏,比如下一个小时后的出港排期,最后你会很惊奇的发现,每个人的时间最后都花在了抢这些资源上。
他们用这个东西

这个东西现在还没有淘汰哦,只是变成电子的了而已。。
是不是觉得一下子效率高了很多,一个空管塔里可以调度的航线可以是前一种方法的几倍到几十倍。
如果你把每一个航线当成一个Sock(I/O 流), 空管当成你的服务端Sock管理代码的话.
第一种方法就是最传统的多进程并发模型 (每进来一个新的I/O流会分配一个新的进程管理。)
第二种方法就是I/O多路复用 (单个线程,通过记录跟踪每个I/O流(sock)的状态,来同时管理多个I/O流 。)
其实“I/O多路复用”这个坑爹翻译可能是这个概念在中文里面如此难理解的原因。所谓的I/O多路复用在英文中其实叫 I/O multiplexing. 如果你搜索multiplexing啥意思,基本上都会出这个图:
重要的事情再说一遍: I/O multiplexing 这里面的 multiplexing 指的其实是在单个线程通过记录跟踪每一个Sock(I/O流)的状态(对应空管塔里面的Fight progress strip槽)来同时管理多个I/O流. 发明它的原因,是尽量多的提高服务器的吞吐能力。
是不是听起来好拗口,看个图就懂了.
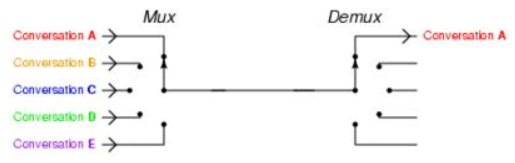
什么,你还没有搞懂“一个请求到来了,nginx使用epoll接收请求的过程是怎样的”, 多看看这个图就了解了。提醒下,ngnix会有很多链接进来, epoll会把他们都监视起来,然后像拨开关一样,谁有数据就拨向谁,然后调用相应的代码处理。
------------------------------------------
了解这个基本的概念以后,其他的就很好解释了。
select, poll, epoll 都是I/O多路复用的具体的实现,之所以有这三个鬼存在,其实是他们出现是有先后顺序的。
I/O多路复用这个概念被提出来以后, select是第一个实现 (1983 左右在BSD里面实现的)。
select 被实现以后,很快就暴露出了很多问题。- select 会修改传入的参数数组,这个对于一个需要调用很多次的函数,是非常不友好的。
- select 如果任何一个sock(I/O stream)出现了数据,select 仅仅会返回,但是并不会告诉你是那个sock上有数据,于是你只能自己一个一个的找,10几个sock可能还好,要是几万的sock每次都找一遍,这个无谓的开销就颇有海天盛筵的豪气了。
- select 只能监视1024个链接, 这个跟草榴没啥关系哦,linux 定义在头文件中的,参见FD_SETSIZE。
- select 不是线程安全的,如果你把一个sock加入到select, 然后突然另外一个线程发现,尼玛,这个sock不用,要收回。对不起,这个select 不支持的,如果你丧心病狂的竟然关掉这个sock, select的标准行为是。。呃。。不可预测的, 这个可是写在文档中的哦.
“If a file descriptor being monitored by select() is closed in another thread, the result is unspecified”
霸不霸气
- poll 去掉了1024个链接的限制,于是要多少链接呢, 主人你开心就好。
- poll 从设计上来说,不再修改传入数组,不过这个要看你的平台了,所以行走江湖,还是小心为妙。
其实拖14年那么久也不是效率问题, 而是那个时代的硬件实在太弱,一台服务器处理1千多个链接简直就是神一样的存在了,select很长段时间已经满足需求。
但是poll仍然不是线程安全的, 这就意味着,不管服务器有多强悍,你也只能在一个线程里面处理一组I/O流。你当然可以那多进程来配合了,不过然后你就有了多进程的各种问题。
于是5年以后, 在2002, 大神 Davide Libenzi 实现了epoll.
epoll 可以说是I/O 多路复用最新的一个实现,epoll 修复了poll 和select绝大部分问题, 比如:- epoll 现在是线程安全的。
- epoll 现在不仅告诉你sock组里面数据,还会告诉你具体哪个sock有数据,你不用自己去找了。
epoll 当年的patch,现在还在,下面链接可以看得到:
/dev/epoll Home Page
可是epoll 有个致命的缺点。。只有linux支持。比如BSD上面对应的实现是kqueue。
其实有些国内知名厂商把epoll从安卓里面裁掉这种脑残的事情我会主动告诉你嘛。什么,你说没人用安卓做服务器,尼玛你是看不起p2p软件了啦。
而ngnix 的设计原则里面, 它会使用目标平台上面最高效的I/O多路复用模型咯,所以才会有这个设置。一般情况下,如果可能的话,尽量都用epoll/kqueue吧。
PS: 上面所有这些比较分析,都建立在大并发下面,如果你的并发数太少,用哪个,其实都没有区别。 如果像是在欧朋数据中心里面的转码服务器那种动不动就是几万几十万的并发,不用epoll我可以直接去撞墙了。链接:https://www.zhihu.com/question/32163005/answer/255238636
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
IO 多路复用是5种I/O模型中的第3种,对各种模型讲个故事,描述下区别:
故事情节为:老李去买火车票,三天后买到一张退票。参演人员(老李,黄牛,售票员,快递员),往返车站耗费1小时。
1.阻塞I/O模型
老李去火车站买票,排队三天买到一张退票。
耗费:在车站吃喝拉撒睡 3天,其他事一件没干。
2.非阻塞I/O模型
老李去火车站买票,隔12小时去火车站问有没有退票,三天后买到一张票。
耗费:往返车站6次,路上6小时,其他时间做了好多事。
3.I/O复用模型
1.select/poll
老李去火车站买票,委托黄牛,然后每隔6小时电话黄牛询问,黄牛三天内买到票,然后老李去火车站交钱领票。
耗费:往返车站2次,路上2小时,黄牛手续费100元,打电话17次
2.epoll
老李去火车站买票,委托黄牛,黄牛买到后即通知老李去领,然后老李去火车站交钱领票。
耗费:往返车站2次,路上2小时,黄牛手续费100元,无需打电话
4.信号驱动I/O模型
老李去火车站买票,给售票员留下电话,有票后,售票员电话通知老李,然后老李去火车站交钱领票。
耗费:往返车站2次,路上2小时,免黄牛费100元,无需打电话
5.异步I/O模型
老李去火车站买票,给售票员留下电话,有票后,售票员电话通知老李并快递送票上门。
耗费:往返车站1次,路上1小时,免黄牛费100元,无需打电话
1同2的区别是:自己轮询
2同3的区别是:委托黄牛
3同4的区别是:电话代替黄牛
4同5的区别是:电话通知是自取还是送票上门
epoll应用
- redis
- nginx
select/poll/epoll之间的区别
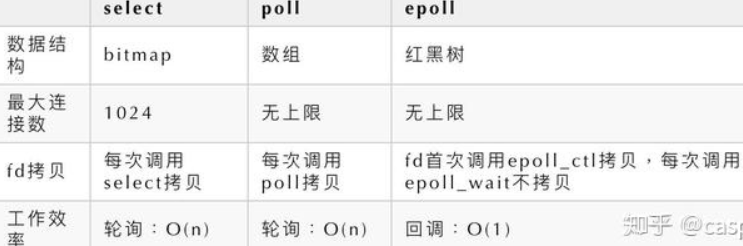
3、多路分离函数select
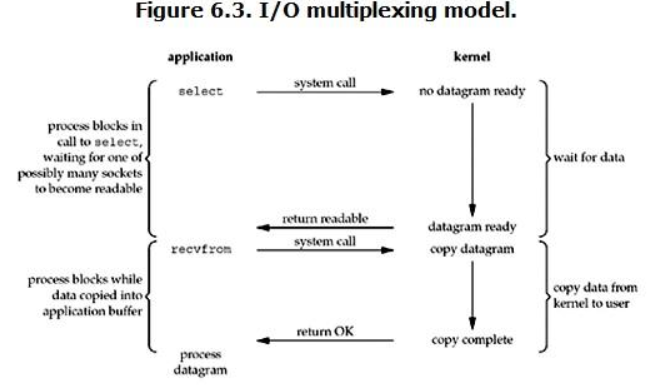
IO多路复用模型是建立在内核提供的多路分离函数select基础之上的,使用select函数可以避免同步非阻塞IO模型中轮询等待的问题。

如上图所示,用户线程发起请求的时候,首先会将socket添加到select中,这时阻塞等待select函数返回。当数据到达时,select被激活,select函数返回,此时用户线程才正式发起read请求,读取数据并继续执行。
从流程上来看,使用select函数进行I/O请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的I/O请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket,即可达到在同一个线程内同时处理多个I/O请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
Reactor(反应器模式)
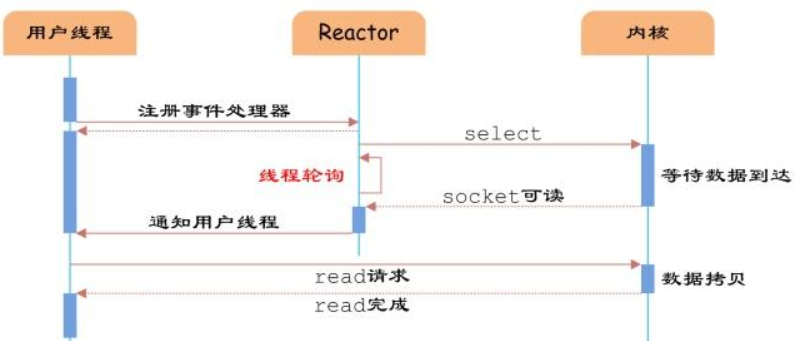
如上图,I/O多路复用模型使用了Reactor设计模式实现了这一机制。通过Reactor的方式,可以将用户线程轮询I/O操作状态的工作统一交给handle_events事件循环进行处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时,则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。由于select函数是阻塞的,因此多路I/O复用模型也被称为异步阻塞I/O模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。一般在使用I/O多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起I/O请求时,数据已经到达了,用户线程一定不会被阻塞。
4、总结
I/O 多路复用模型是利用select、poll、epoll可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有I/O事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll是只轮询那些真正发出了事件的流),依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的吞吐量。
参考文章:
https://zhuanlan.zhihu.com/p/58038188
https://blog.csdn.net/diweikang/article/details/90346020
https://www.zhihu.com/question/32163005



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架