Mysql 关联查询
一、先说下查询sql格式
sql格式: select 列名/* from 表名 where 条件 group by 列 having 条件 order by 列 asc/desc;
这里牵涉到一个查询执行顺序的问题.
单表查询执行顺序:
select sex, count(Sex) as count from tch_teacher where id > 15 group by Sex having count > 5 order by Sex asc limit 1;
1-> from 表 : 首先拿到表tch_teacher
2-> where 条件 : 根据where后面的条件筛选一遍数据集合A
3-> group by 分组 : 对筛选出的数据A, 根据group by后面的列进行分组, 得到数据集B
4-> having 筛选 : 对数据集B进行进一步筛选, 得到数据集C
5-> select 数据 : 这里有四步
第一步 : 根据select后面的列名, 去数据集C中取数据. 得到数据集D
第二步 : 对数据集D中的数据进行去重操作(这一步是建立在 sql中有distinct 情况下), 得到数据集E
第三步 : 对数据集E进行排序操作, 得到数据集F
第四步 : 对数据集F进行截取数据操作, 得到最终的数据集(执行 limit 10 操作)
二、多表关联查询
1、cross join 交叉连接 -- 笛卡尔乘积
select * from tch_teacher cross join tch_contact
这种连接方式, 没见人用过. 如果tch_teacher,tch_contact表各有10条数据, 那么连接的结果, 就是 10 x 10 = 100 条数据。
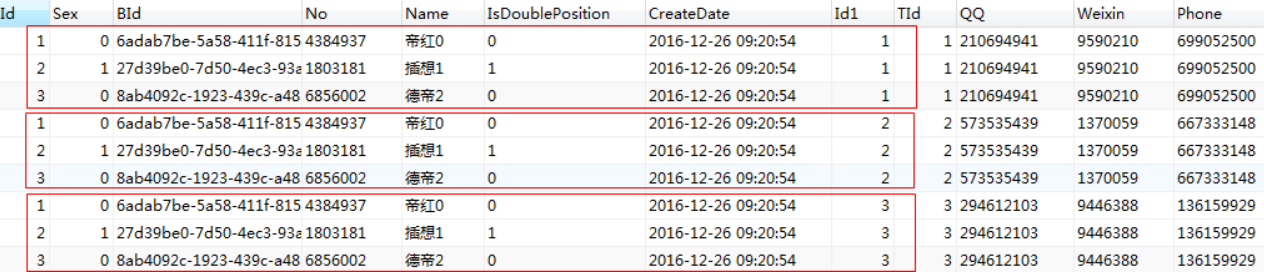
在mysql 中, cross join 后面是可以跟 on 和 where 的, 加上之后, 其实跟 inner join 是一样的。
2、inner join 内连接
内连接在不加on的情况下, 也是去求笛卡尔乘积。 不加on的用法并不推荐使用, 容易造成内存溢出的情况. 加on的时候, 在连表的时候, 就会对数据进行筛选, 以此来缩减有效数据范围。
select * from tch_teacher inner join tch_contact

从上面的sql和图片来看, inner join 的时候, 可以不加on, 也能得到一个结果, 而且这个结果和交叉连接的结果是一样的.
这里还有另外两种写法:
select * from tch_teacher,tch_contact select * from tch_teacher join tch_contact
得到的结果是一样的。
注意:
select * from tch_teacher inner join tch_contact on tch_teacher.Id = tch_contact.TId; select * from tch_teacher, tch_contact where tch_teacher.Id = tch_contact.TId; --上面等效。 --on 连接时就做的关联动作,where 是全部关联完以后,再根据条件过滤。 --有说前者比后者执行要快,待验证 TODO
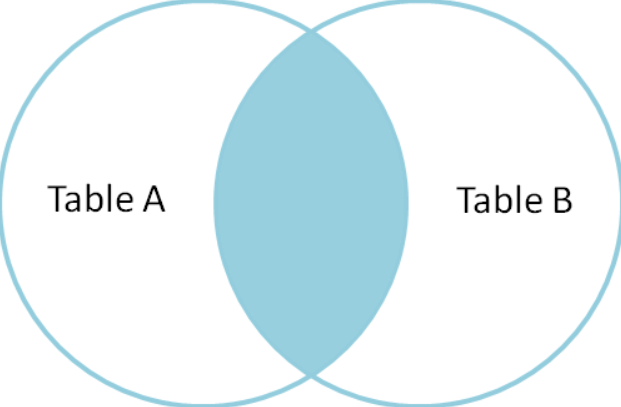
ps:以上图示就是其生成临时表的数据范围。
3、left/right join on 外连接
这里我特意加了一个on在上面, 因为不加on是会报错的.
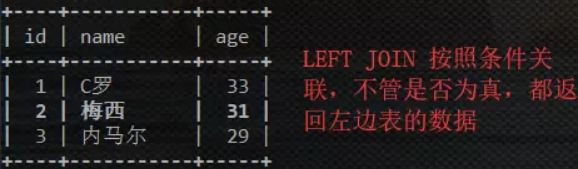
left join 称之为左连接, 连接以左侧表数据为准, 当右表没有数据与之匹配的时候, 则会用null填补
right join 称之为右连接, 与 left join 相反, 这个是以右表为准
先看下效果吧:
select * from tch_teacher left join tch_contact on tch_teacher.Id = tch_contact.TId;

select * from tch_teacher right join tch_contact on tch_teacher.Id = tch_contact.TId;

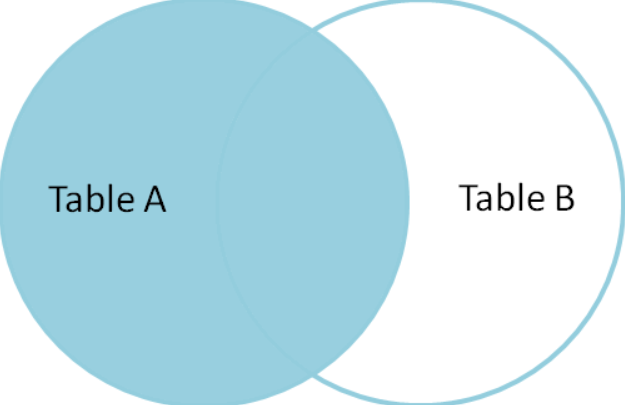
ps:以上图示就是其生成临时表的数据范围。
注意:不管是inner join 还是left/right join,当以驱动表去loop遍历另一张表时,如:主从表 一对多,(一left/inner join 多),那么重叠的数据,会以多条数据行数为准,主表会冗余行数跟从,要注意数据查重的问题(如果页面主要显示主表数据那么就会有重复),可先对子表进行关联字段查重处理后的临时表再进行关联查询。
4、full join 全外连接
把两张表的字段都查出来,没有对应的值就显示null,但是注意:mysql是没有全外连接的(mysql中没有full outer join关键字),想要达到全外连接的效果,可以使用union关键字连接左外连接和右外连接。例如:
select * from tch_teacher left join tch_contact on tch_teacher.Id = tch_contact.TId UNION select * from tch_teacher right join tch_contact on tch_teacher.Id = tch_contact.TId
5、自己连自己
mysql支持一个功能, 就是自己连自己,我再tch_teacher表里面加入一列, CreateBy, 存放的是这个表的Id值。
select a.*, b.Name as CreateByName from tch_teacher a left join tch_teacher b on a.createby = b.id
能得到以下结果:

三、union查询
除了把几个表通过内部关系拼成一个表结果, 还可以, 把多个表的查询表结果拼成一个表结果. 所使用的方法就是union。
这里要注意的是, 列的顺序. 如果害怕列的顺序不一致不好排查, 可以把表结果的列名都重命名为相同的。
select Id, Sex, BId, `No`, Name, CreateDate from tch_teacher union select 0 as Id, Sex, BId, `No`, Name, CreateDate from tch_teacher_temp
union是会对最后的表结果进行去重操作的, 如果我不想去重, 只想快速得到拼接的结果, 可以使用 union all 来拼接。
四、ON 与 WHERE 的区别
很多同学在学习 Mysql 表关联的时候弄不清ON和WHERE的区别,不知道条件应该写在on里面还是where里面,今天简单易懂的总结一下他们的区别,大家共同学习。
这里以left join为例(right join 同理)
- on的条件是在连接生成临时表时使用的条件,on后的条件来生成左右表关联的临时表。以左表为基准 ,不管on中的条件真否,都会返回左表中的记录。
- where条件是在临时表生成好后,再对临时表过滤。此时 和left join(返回左表全部记录)有区别,条件不为真就全部过滤掉,where后的条件是生成临时表后对临时表过滤。
当然如果你使用的是 inner join 则on后条件过滤效果对两边的表都会生效,效果等同于where后跟的过滤条件。
准备工作
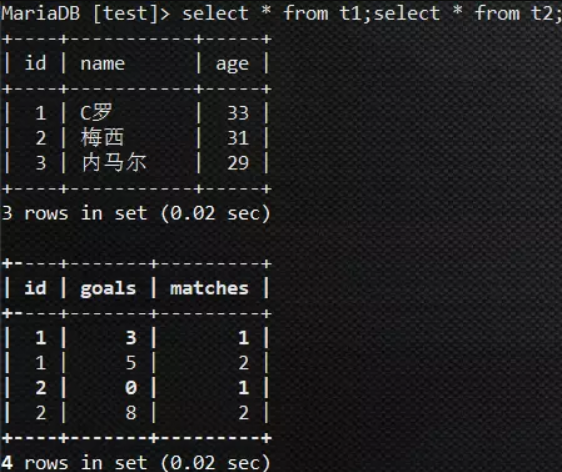
我们先准备两个表,并造一些数据:
-- t1 create table t1 ( id bigint default '0' not null comment '主键id', name char(100) default '' not null comment '姓名', age int default '0' not null ); -- t2 create table t2 ( id bigint default '0' not null comment '主键id', goals int default '0' not null comment '进球数', matches int default '0' not null comment '比赛编号' );
探究
口诀:先执行 ON,后执行 WHERE;ON 是建立关联关系,WHERE 是对关联关系的筛选。记住这句话就可以准确地判断查询结果了,我们通过两个 sql 来进行分析:
SELECT t1.id, t1.name, t1.age FROM t1 LEFT JOIN t2 ON t1.id = t2.id WHERE matches = 2; -- 条件放在 WHERE SELECT t1.id, t1.name, t1.age FROM t1 LEFT JOIN t2 ON t1.id = t2.id AND matches = 2; -- 条件放在 ON
执行第一个 sql 时,前提是 LEFT JOIN,所以左边的数据在创建关联关系时会保留,根据口诀,先执行 ON 建立关联关系,然后通过 WHERE 筛选,过程如下:
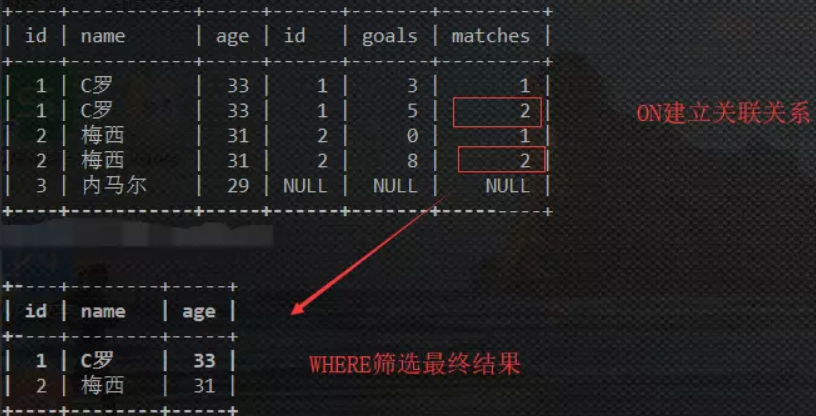
第二个 sql 没有 WHERE,那么 ON 建立的关联关系就是最终结果:
注意:
在使用inner join时,不管是对左表还是右表进行筛选,on and和on where都会对生成的临时表进行过滤。on and和on where结果一致。
五、and 与 or优先级
MySQL中,AND的执行优先级高于OR。也就是说,在没有小括号()的干预下,总是先执行AND语句,再执行OR语句。
例:
select * from table where 条件1 AND 条件2 OR 条件3
等价于
select * from table where ( 条件1 AND 条件2 ) OR 条件3
select * from table where 条件1 AND 条件2 OR 条件3 AND 条件4
等价于
select * from table where ( 条件1 AND 条件2 ) OR ( 条件3 AND 条件4 )
如果要把条件2与条件3作为一个整体,需要加括号
select * from table where 条件1 AND (条件2 OR 条件3) AND 条件4
六、其他
1、《阿里巴巴JAVA开发手册》里面写超过三张表禁止join,这是为什么?

这个规则 超过三张表禁止join ,由于数据量太大的时候,mysql根本查询不出来,导致阿里出了这样一个规定。(其实如果表数据量少,10张表也不成问题,你自己可以试试)而我们公司支付系统朝着大规模高并发目标设计的,所以,遵循这个规定。
在业务层面来讲,写简单sql,把更多逻辑放到应用层,我的需求我会更了解,在应用层实现特定的join也容易得多。
参考文章:
https://www.cnblogs.com/elvinle/p/6214894.html
https://www.cnblogs.com/HKUI/p/8536969.html
https://www.jianshu.com/p/d923cf8ae25f

