Mysql 驱动表查询优化
一、需要优化的查询:使用explain
二、驱动表的含义
MySQL 表关联的算法是 Nest Loop Join,是通过驱动表的结果集作为循环基础数据,然后一条一条地通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果:
- EXPLAIN 结果中,第一行出现的表就是驱动表
- 对驱动表可以直接排序,对非驱动表(的字段排序)需要对循环查询的合并结果(临时表)进行排序(Important!),即using temporary;
- [驱动表] 的定义为:1)满足查询条件的记录行数少的表为[驱动表];2)未指定查询条件时,行数少的表为[驱动表](Important!)。
- 优化的目标是尽可能减少JOIN中Nested Loop的循环次数,以此保证:永远用小结果集驱动大结果集(Important!)!:A JOIN B,A为驱动,A中每一行和B进行循环JOIN,看是否满足条件,所以当A为小结果集时,越快。
- NestedLoopJoin实际上就是通过驱动表的结果集作为循环基础数据,然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。如果还有第三个参与Join,则再通过前两个表的Join结果集作为循环基础数据,再一次通过循环查询条件到第三个表中查询数据,如此往复。
MySQL的 Join 都是通过嵌套循环来实现的。驱动结果集越大,所需要循环就越多,那么被驱动表的访问次数自然也就越多,而每次访问被驱动表,即使需要的逻辑 IO 很少,循环次数多了,总量也不可能小,而且每次循环都不能避免消耗CPU,所以 CPU 运算量也会跟着增加。
当有order by条件时,如select * from a inner join b where 1=1 and other condition order by a.col;使用explain解释语句;
- 如果第一行的驱动表为a,则效率会非常高,无需优化;
- 否则,因为只能对驱动表字段直接排序的缘故,会出现using temporary,所以此时需要使用STRAIGHT_JOIN明确a为驱动表,来达到使用a.col上index的优化目的;或者使用left join,而STRAIGHT_JOIN为inner join且使用a作为驱动表。
三、Mysql的STRAIGHT_JOIN
STRAIGHT_JOIN,在数据量大的联表查询中灵活运用的话,能大大缩短查询时间。
首先来解释下STRAIGHT_JOIN到底是用做什么的:
STRAIGHT_JOIN is similar to JOIN, except that the left table is always read before the right table. This can be used for those (few) cases for which the join optimizer puts the tables in the wrong order.
意思就是说STRAIGHT_JOIN功能同join类似,但能让左边的表来驱动右边的表,能改表优化器对于联表查询的执行顺序。
需要注意的是:
- STRAIGHT_JOIN只适用于inner join,并不使用与left join,right join。(因为left join,right join已经代表指定了表的执行顺序)
- 尽可能让优化器去判断,因为大部分情况下mysql优化器是比人要聪明的。而且你可能不能确定未来表的大小变化。使用STRAIGHT_JOIN一定要慎重。
下面拿例子说明:
SELECT post.* FROM post INNER JOIN post_tag ON post.id = post_tag.post_id WHERE post.status = 1 AND post_tag.tag_id = 123 ORDER BY post.created DESC LIMIT 100
说明:因为post和tag是多对多的关系,所以存在一个关联表post_tag。
试着用EXPLAIN查询一下SQL执行计划(篇幅所限,结果有删减):
+----------+---------+-------+-----------------------------+ | table | key | rows | Extra | +----------+---------+-------+-----------------------------+ | post_tag | tag_id | 71220 | Using where; Using filesort | | post | PRIMARY | 1 | Using where | +----------+---------+-------+-----------------------------+
SELECT post.* FROM post STRAIGHT_JOIN post_tag ON post.id = post_tag.post_id WHERE post.status = 1 AND post_tag.tag_id = 123 ORDER BY post.created DESC LIMIT 100
试着用EXPLAIN查询一下SQL执行计划(篇幅所限,结果有删减):
+----------+----------------+--------+-------------+ | table | key | rows | Extra | +----------+----------------+--------+-------------+ | post | status_created | 119340 | Using where | | post_tag | post_id | 1 | Using where | +----------+----------------+--------+-------------+
对比优化前后两次EXPLAIN的结果来看,优化后的SQL虽然「rows」更大了,但是没有了「Using filesort」,综合来看,性能依然得到了提升。
提醒:注意两次EXPLAIN结果中各个表出现的先后顺序,稍后会解释。
解释:
对第一条SQL而言,为什么MySQL优化器选择了一个耗时的执行方案?对第二条SQL而言,为什么把连接方式改成STRAIGHT_JOIN之后就提升了性能?
这一切还得从MySQL对多表连接的处理方式说起,首先MySQL优化器要确定以谁为驱动表,也就是说以哪个表为基准,在处理此类问题时,MySQL优化器采用了简单粗暴的解决方法:哪个表的结果集小,就以哪个表为驱动表,当然MySQL优化器实际的处理方式会复杂许多。
说明:在EXPLAIN结果中,第一行出现的表就是驱动表。
继续post连接post_tag的例子,MySQL优化器有如下两个选择,分别是:
- 以post为驱动表,通过status_created索引过滤,结果集119340行
- 以post_tag为驱动表,通过tag_id索引过滤,结果集71220行
显而易见,post_tag过滤的结果集更小,所以MySQL优化器选择它作为驱动表,可悲催的是我们还需要以post表中的created字段来排序,也就是说排序字段不在驱动表里,于是乎不可避免的出现了「Using filesort」,甚至「Using temporary」。
知道了来龙去脉,优化起来就容易了,要尽可能的保证排序字段在驱动表中,所以必须以post为驱动表,于是乎必须借助「STRAIGHT_JOIN」强制连接顺序。
实际上在某些特殊情况里,排序字段可以不在驱动表里,比如驱动表结果集只有一行记录,并且在连接其它表时,索引除了连接字段,还包含了排序字段,此时连接表后,索引中的数据本身自然就是排好序的。
四、msyql join语句执行原理
该章节是后续补充进来的,可对照上面的知识点来看。
首先,我建了一个表t2,里面有1000条数据,有id,a,b三个字段,a字段加了索引
然后我又建立一个t1表,里面有100条数据,和t2表的前一百条数据一致,也是只有id,a,b三个字段,a字段加了索引
如下图
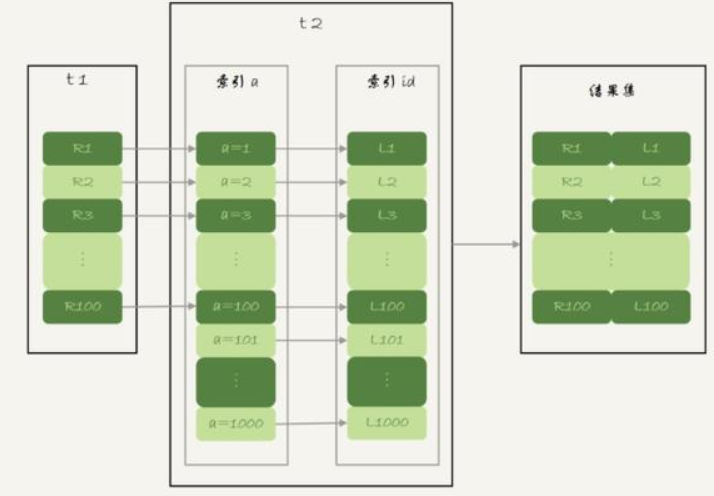
然后我们看这条语句,为了不影响效果,这里我用了STRAIGHT_JOIN ,也就是在这条语句里会把t1当做驱动表
select * from t1 STRAIGHT_JOIN t2 on t1.a=t2.a
那么这条语句的执行流程就是这样的
1.从t1表查询出一行数据R
2.查出R这行数据的a字段的值到t2表中去查询
3.查询符合条件的数据和R组成一行,组装成结果集返回到客户端
4.重复执行步骤1-3,知道查到t1表的末尾
总结:由于我们在t2表上的a字段建立了索引,所以在第二步的时候不需要做全表扫描,也就是说,我们执行这条语句的扫描行数是200行,
首先t1表是扫描了100行,当和t2表每行去匹配的时候又扫描了t2表100行,所以这条语句总共扫描行数是200行,这种算法的扫描行数还是可以的。
对应的流程图如下图所示,这种算法叫作"Index Nested-Loop Join",简称NLJ
select * from t1 STRAIGHT_JOIN t2 on t1.a=t2.b
然后我们在看这条语句,由于b字段没有索引,所以在执行这条语句的时候,去t2表匹配的时候就要进行全表扫描
所以这条语句执行后的扫描行数就是100*1000=10万行
这个算法也有个名字叫做
Simple Nested-Loop Join
但是mysql没有使用这个算法,而是使用了另一种算法,叫做
Block Nested-Loop Join,简称BNL
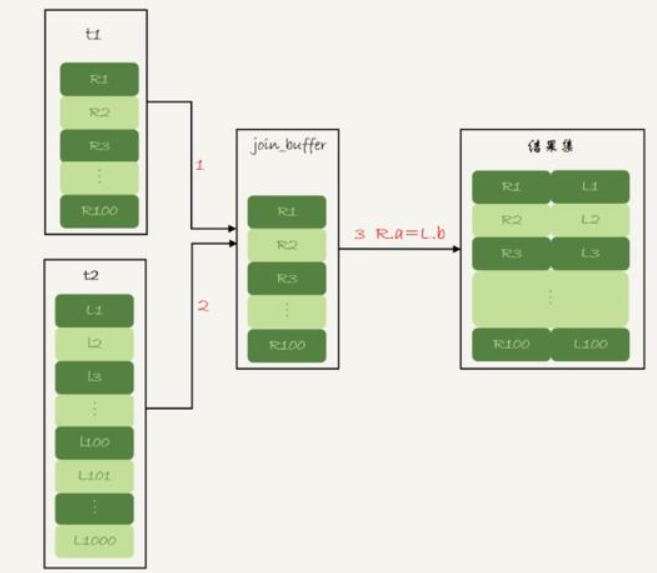
内存中
2.扫描表t2,将t2表的每一行数据和join_buffer中的数据进行匹配(全表扫描),符合条件的数据作为结果集的一部分返回
这里有个问题,如果join_buffer的大小不够存储t1表的数据怎么办呢?
其实也很简单,就是分成多部分查询放入join_buffer中
举个例子:
比如说join_buffer中只够存储50行数据,但是t1表有100行,那么就先查出t1表的50行数据放入join_buffer中,然后和t2表进行匹配
但是这样就带来了一个问题,也就是说我们要分两次放入join_buffer中,那么也就是说要对表t2进行两次全表扫描
这样扫描行数就是2200行了,不知道大家发现一个问题了没有,这个时候影响扫描行数的因素有哪些??
第一个因素就是这个join_buffer_size这个参数,如果他足够大,那么我们就只需要扫描表t2一次了,所以说有的时候我们发现了这个问题,
可以通过调大join_buffer_size这个参数来提高性能,当然不是说这个参数越大越好,要根据各方面情况来衡量。
第二个因素就是驱动表的大小,如果驱动表的数据小,那么要么不分段存入join_buffer中,那就只扫描了一次表t2,要么分段存入join_buffer中,这个时候,分段越少,那么扫描次数就越少
也就是说驱动表的数据越小越好
所以我们要使用小表来做驱动表,小表不是说某个表的真实的数据,而是说通过当前执行的语句中条件以及查询的字段而算出来的数据
例如
select t1.b,t2.* from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=100;
select t1.b,t2.* from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=100;
在这个例子中表t1只查询出b字段放入join_buffer中
而表t2要把所有字段都放入join_buffer中,所以这个时候表t1是小表
这两种算法显然第一种算法也就是NLJ的性能要好,所以我们在写sql语句的时候要尽量让mysql使用这种算法
也就是要对连接的字段加上索引,如果该字段确实不适合加索引,没办法只能使用第二种算法,那么这个时候我们就要尽量使用小表来当做驱动表。
参考文章:
https://www.aliyun.com/jiaocheng/1106139.html
https://blog.csdn.net/u012246342/article/details/51083026
https://huoding.com/2013/06/04/261

