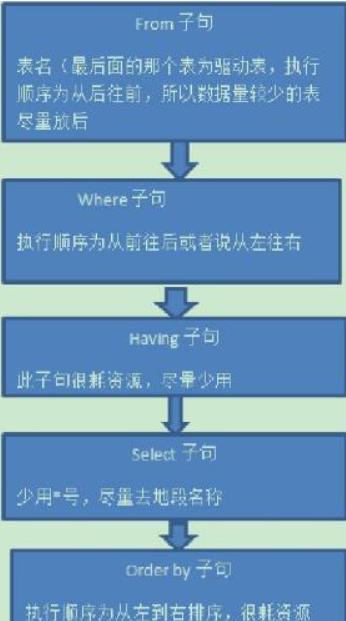
sql语句执行顺序
案例:查询语句中select from where group by having order by的执行顺序
1.查询中用到的关键词主要包含六个,并且他们的顺序依次为
select--from--where--group by--having--order by
其中select和from是必须的,其他关键词是可选的,这六个关键词的执行顺序
与sql语句的书写顺序并不是一样的,而是按照下面的顺序来执行
from--where--group by--having--select--order by,
from:需要从哪个数据表检索数据
where:过滤表中数据的条件
group by:如何将上面过滤出的数据分组
having:对上面已经分组的数据进行过滤的条件
select:查看结果集中的哪个列,或列的计算结果
order by :按照什么样的顺序来查看返回的数据

SQL Select语句完整的执行顺序【从DBMS使用者角度】:
1、from子句组装来自不同数据源的数据;
2、where子句基于指定的条件对记录行进行筛选;
3、group by子句将数据划分为多个分组;
4、使用聚集函数进行计算;
5、使用having子句筛选分组;
6、计算所有的表达式;
7、使用order by对结果集进行排序。
where子句--执行顺序为自下而上、从右到左
ORACLE 采用自下而上从右到左的顺序解析Where 子句,根据这个原理,表之间的连接必须写在其他Where 条件之前, 可以过滤掉最大数量记录的条件必须写在Where 子句的末尾。
group by--执行顺序从左往右分组
提高GROUP BY 语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉。即在GROUP BY前使用WHERE来过虑,而尽量避免GROUP BY后再HAVING过滤。
having 子句----很耗资源,尽量少用
避免使用HAVING 子句, HAVING 只会在检索出所有记录之后才对结果集进行过滤. 这个处理需要排序,总计等操作.
如果能通过Where 子句在GROUP BY前限制记录的数目,那就能减少这方面的开销.
(非oracle 中)on、where、having 这三个都可以加条件的子句中,on 是最先执行,where 次之,having 最后,因为on 是先把不符合条件的记录过滤后才进行统计,它就可以减少中间运算要处理的数据,按理说应该速度是最快的,
where 也应该比having 快点的,因为它过滤数据后才进行sum,在两个表联接时才用on 的,所以在一个表的时候,就剩下where 跟having比较了。
在这单表查询统计的情况下,如果要过滤的条件没有涉及到要计算字段,那它们的结果是一样的,只是where 可以使用rushmore 技术,而having 就不能,在速度上后者要慢。
如果要涉及到计算的字段,就表示在没计算之前,这个字段的值是不确定的,where 的作用时间是在计算之前就完成的,而having 就是在计算后才起作用的,所以在这种情况下,两者的结果会不同。
在多表联接查询时,on 比where 更早起作用。系统首先根据各个表之间的联接条件,把多个表合成一个临时表后,再由where 进行过滤,然后再计算,计算完后再由having 进行过滤。
由此可见,要想过滤条件起到正确的作用,首先要明白这个条件应该在什么时候起作用,然后再决定放在那里。
select子句--少用*号,尽量取字段名称。
ORACLE 在解析的过程中, 会将依次转换成所有的列名, 这个工作是通过查询数据字典完成的, 使用列名意味着将减少消耗时间。
sql 语句用大写的;因为 oracle 总是先解析 sql 语句,把小写的字母转换成大写的再执行
order by子句--执行顺序为从左到右排序,很耗资源。

