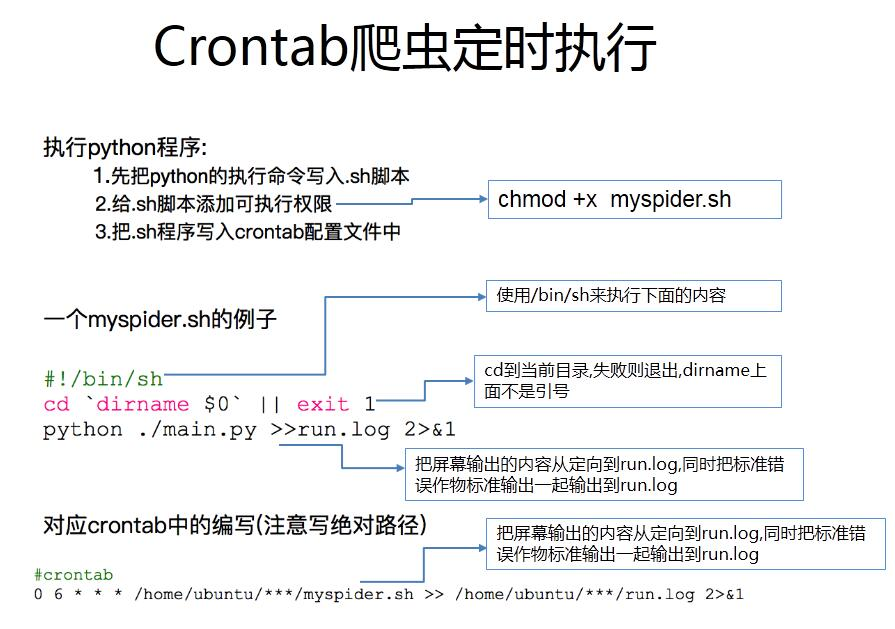
定时爬取海丝财经网站新闻内容
1、定时器
1.1一直执行程序
直接在python脚本中加入几行代码,让这个脚本一直运行
scheduler = BlockingScheduler()
scheduler.add_job(mainAll, 'cron', second='*/50', hour='*/8')
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
scheduler.shutdown()
此处调用mainAll()函数,运行完一次阻塞8小时50秒
1.2定点触发并执行程序
(1) windows系统可以直接配置, 详情见博客
(2)Linux系统非常的简单
首先crontab -e打开文件 ,输入指令 30 12 * * * python2.7 /x/test.py
注意在test.py脚本上必须叫上一行
30 12 * * * /usr/local/bin/python2.7 /x/test.py

2、现在来看看网页长什么样子
网址:http://fjrb.fjsen.com/nasb/html/2017-09/18/node_122.htm
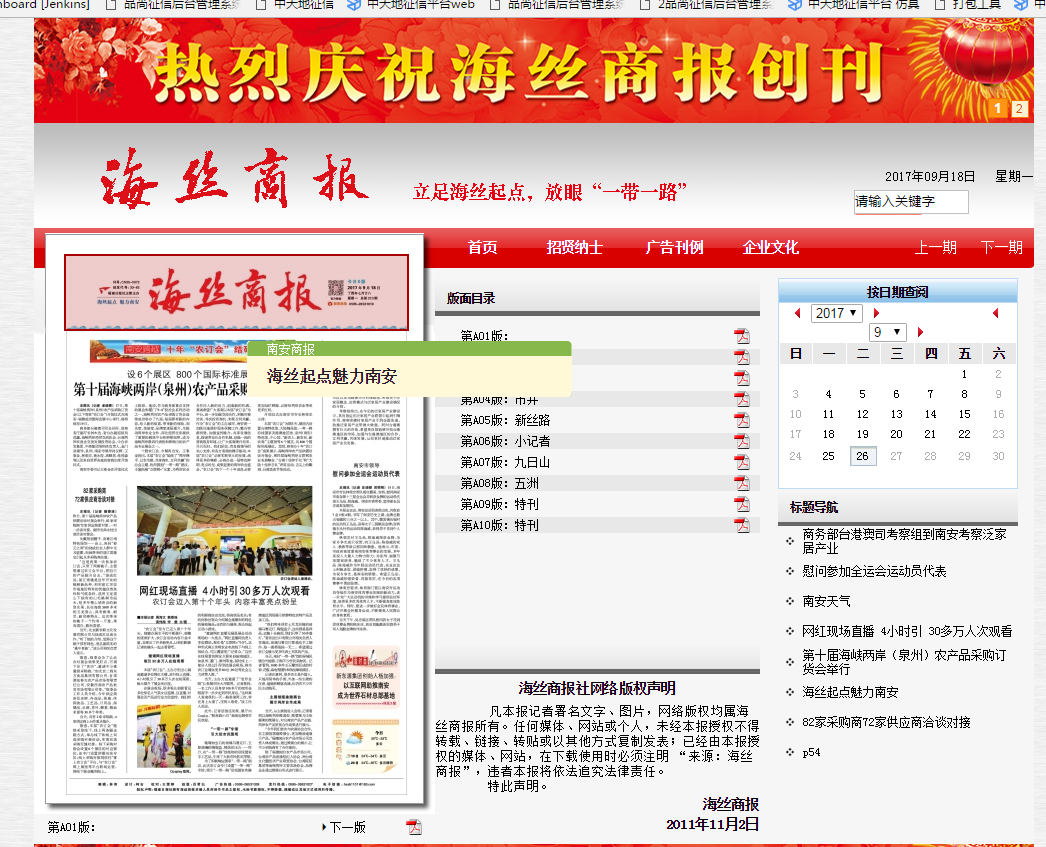

网址很容易获取,都是有规律的 url = 'http://fjrb.fjsen.com/nasb/html/%s-%s/%s/node_122.htm' % (y, m, d)
我现在的思路就是点击到首页计算有多少版sheet_len,每次点击一版再计算右下角有多少篇文章titles_len,在每一版下模拟点击第一篇文章后然后得到第二章图,点击下一篇共titles_len-1次,获取每一版的所有文章的内容
代码如下:
# -*-coding:utf-8-*-
'''# 9.18
url = 'http://fjrb.fjsen.com/nasb/html/2017-09/18/node_122.htm' # 第一版
urlend = 'http://fjrb.fjsen.com/nasb/html/2017-09/18/node_131.htm' # 第十版
# 9.20
url = 'http://fjrb.fjsen.com/nasb/html/2017-09/20/node_122.htm' # 第一版
url = 'http://fjrb.fjsen.com/nasb/html/2017-09/20/node_129.htm' # 第十版
'''
import time
from selenium import webdriver
import pymysql
import uuid
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
import os
class mainAll(object):
def __init__(self):
self.conn = pymysql.connect(host='localhost', user='root', passwd='123', db='tianyan', port=3306, charset='utf8')
self.cur = self.conn.cursor() # 获取一个游标
self.main()
self.cur.close()
self.conn.close()
print('Tick! The time is: %s' % datetime.now())
def main(self):
# 获取当前年月日
y = time.strftime('%Y', time.localtime(time.time())) # 年
m = time.strftime('%m', time.localtime(time.time())) # 月
d = time.strftime('%d', time.localtime(time.time())) # 日
data_time = time.strftime('%Y-%m-%d', time.localtime(time.time())) # 抓取时间
data_time_now = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
website = '海丝商报'
# 创建相应时间的url地址
url = 'http://fjrb.fjsen.com/nasb/html/%s-%s/%s/node_122.htm' % (y, m, d)
driver = webdriver.Chrome()
driver.get(url)
# 找到版面数
sheets = driver.find_element_by_xpath("//table[@cellpadding='2']")
sheets_len = len(sheets.find_elements_by_tag_name('tr'))
# 找到每个版面的标题数量
for sheet in range(3):
titles = driver.find_element_by_xpath("//table[@cellpadding='1']")
titles_len = int(len(titles.find_elements_by_tag_name('tr')) / 2)
content_type = driver.find_element_by_xpath("//table[@cellpadding='2']").find_elements_by_tag_name('tr')
content_type = content_type[sheet].text.split(':')[-1] # 以冒号为分隔符切开版面的文字
# 点击版面的第一篇文章
title_button = driver.find_element_by_xpath("//*[@id='demo']/table[1]/tbody/tr[3]/td[2]/table/tbody/"
"tr[4]/td/table/tbody/tr/td[2]/table/tbody/tr[1]/td/table/"
"tbody/tr[4]/td/div/table/tbody/tr[1]/td[2]/a")
title_button.click()
for title in range(titles_len):
# 找到主标题和子标题的table表
title_table = driver.find_element_by_xpath(
"//*[@id='demo']/table/tbody/tr[3]/td[2]/table/tbody/tr[4]//tr")
content_title = title_table.find_elements_by_tag_name('p')[0].text
content_subtitle = title_table.find_elements_by_tag_name('p')[1].text
content = driver.find_element_by_xpath("//table[@class='content_tt']").text
# 获取左下角每一版的所有标题的链接
content_id = driver.find_elements_by_xpath("//*[@id='demo']/table/tbody/tr[3]/td[1]/table/tbody/tr[3]/"
"td/table//a")
content_id = content_id[title].get_attribute('href')
content_id = content_id.split('content_')[-1].split('.')[0] # 正则表达式没有处理成功!!!!!
# content_id = driver.current_url
# 'http://fjrb.fjsen.com/nasb/html/2017-09/21/content_1055929.htm?div=-1'
idd = str(uuid.uuid1())
idd.replace('-', '')
# 新闻时间和爬取时间是一个时候 sentiment_source 和sentiment_website是同一处理的
lists = (idd, content_title, content_subtitle, website, data_time, url, website, data_time_now, content,
content_id, content_type)
driver.find_elements_by_xpath("//a[@class='preart']")[-1].click() # 点击下一篇章
# 当把一版的所有标题都走完以后,点击下一版,回到外层循环的页面
if title == titles_len - 1 and sheet == 0:
# 如果走到第一版的最后一篇,那么点击下一版
driver.find_elements_by_xpath("//a[@class='preart']")[0].click()
elif title == titles_len - 1 and sheet > 0:
# 如果走到除第一版的最后一篇,同样点击下一版,此时页面上还有上一版,所以
driver.find_elements_by_xpath("//a[@class='preart']")[1].click()
# 只找第一版,如果第一版第一篇的内容已经入库,那么就直接停止本次采集
flag = self.judge(content_id)
if flag > 0:
continue
# 我这里的break会不会让定时程序都停止了 有没有一个方法可以跳出整体循环
self.con(lists)
driver.close()
def con(self, table):
# 名称 职位 公司名称 entuid
sql = "INSERT INTO sentiment_info (sentiment_id, sentiment_title, sentiment_subtitle, sentiment_source," \
"sentiment_time, sentiment_url,sentiment_website,sentiment_create_time,sentiment_content," \
"sentiment_source_id,sentiment_type) VALUES ( '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s', '%s'," \
" '%s','%s')"
self.cur.execute(sql % table)
self.conn.commit()
# 第一页点击 driver.find_element_by_xpath("//a[@class='preart']").click() 即可到下一页
def judge(self, content_id):
sql = """SELECT COUNT(*) FROM sentiment_info WHERE sentiment_source='海丝商报'
AND sentiment_source_id='%s'""" % content_id
self.cur.execute(sql)
a = self.cur.fetchall()
a = max(max(a))
self.conn.commit()
return a
if __name__ == '__main__':
scheduler = BlockingScheduler()
scheduler.add_job(mainAll, 'cron', second='*/50', hour='*/8')
print('Press Ctrl+{0} to exit'.format('Break' if os.name == 'nt' else 'C'))
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
scheduler.shutdown()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号