
A Node Influence Based Label Propagation Algorithm for Community detection in networks 文章算法实现的疑问
这是我最近看到的一篇论文,思路还是很清晰的,就是改进的LPA算法。改进的地方在两个方面:
(1)结合K-shell算法计算量了节点重重要度NI(node importance),标签更新顺序则按照NI由大到小的顺序更新
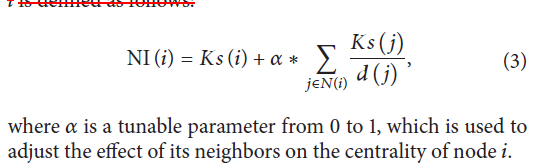
得到ks值后,载计算一下节点邻居ks值和度值d的比值
(2)当出现次数最多的标签不止一个时,再计算一下标签重要度LI(label importance)

其实就是找到节点相同标签的那些令居计算一个合值,看着也不难啊
(3)最后这个算法使用的是异步传播
下面是我实现的代码
function Labelnew=NIBlpa(A,alpha)
% A Node Influence Based Label Propagation Algorithm for
% Community Detection in Networks
% [X,Y,Z] = NIBlpa(A,alpha)
%
% Inputs:
% k - clique size
% A - adjacency matrix
%
% Outputs:
% X - detected communities
% Y - all cliques (i.e. complete subgraphs that are not parts of larger
% complete subgraphs)
% Z - k-clique matrix
%
% Author : Yang Yang
% Email : bethansy@yahoo.com
ks=kshell(A);
n=size(A,1);
D=sum(A,2);
NI=ks;
label = 1:size(A,2);
%%
% calculate NI(node importance)
for i=1:n
Nei=find(A(i,:)==1);
NI(i,2)=ks(i,2)+alpha*sum(ks(Nei,2)./D(Nei));
end
sequence=sortrows(NI,-2);
%%
% Label propagation
Label1 = label;
Labelnew = Label1;
while(1)
for i=1:n
% 找到邻居下标对应的标签
nb_lables = Labelnew(A(sequence(i,1),:)==1);
% 只考虑了每个节点至少有一个邻居,如果有孤立节点程序不运行保持原标签
if size(nb_lables,2)>0
x = HistRate(nb_lables);
max_nb_labels = x(x(:,2)==max(x(:,2)),1);
if size(max_nb_labels)==1
Labelnew(sequence(i,1))= max_nb_labels;
else
LI=zeros(length(max_nb_labels),1);
for ma=1:length(max_nb_labels)
Nei=find(A(sequence(i),:));
index=Labelnew(Nei)==max_nb_labels(ma);
LI(ma)=sum(NI(Nei(index),2)./D(Nei(index)));
end
[~,maxx]=max(LI);
Labelnew(sequence(i,1))=max_nb_labels(maxx);
end
end
end
% 收敛条件,预防跳跃
if Labelnew==Label1
break;
else
Label1 = Labelnew;
end
end
下面是调用K-shell算法的代码
function [kvalue]=kshell(A)
% A :邻接矩阵
% A=load('cdbBA_4000_5_0_.txt');
%
n=size(A,1);
kvalue=zeros(n,2);
kvalue(:,1)=[1:n]';
if find(sum(A,2)==0)
kvalue(sum(A,2)==0,2)=0;
end
a=1;k=1;
% 一层循环主要是叫K-shell中k值,当层层剥掉节点度k的节点后,将这些节点边删除,当网络中不再有小于等于k的节点后,k=k+1
while a
D=sum(A,2);
if sum(D)==0
break;
end
b=1;
% 二层循环主要是找到k层的所有节点
while b
index=find(D<=k&D>0);
if isempty(index)
b=0;continue;
else
A(index,:)=0;
A(:,index)=0;
D=sum(A,2);
kvalue(index,2)=k;
end
end
k=k+1;
end
end
但是后在几个数据集上测试效果都非常不好,例如karate上nmi只有0.2多,但是论文中作者得到的结果却是1,我已经把文章看了几遍还是找不出算法和作者哪里有出入,不过发现改进(2)的公式是错误的源头?抓头???其指教
2017.6.15 更新:用这个代码在人工网络上测试,结果和论文中有是一样的了。但是在实际网络karate、dolphin、football中结果和作者给出的结果相差很大。不知道为什么?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号