
网页字数统计
下载
代码
using System;
using System.ComponentModel;
using System.Globalization;
using System.Text;
using System.Threading;
using System.Windows.Forms;
namespace WillCC
{
public partial class Form1 : Form
{
private static SynchronizationContext _synchronizationContext;
public Form1()
{
_synchronizationContext = SynchronizationContext.Current;
InitializeComponent();
}
private void btnGo_Click(object sender, EventArgs e)
{
var websites = new BindingList<Website>();
dgResult.DataSource = websites;
var topWebsite = new Website(txtUrl.Text);
websites.Add(topWebsite);
topWebsite.LinkParsed += url => _synchronizationContext.Post(d => websites.Add(new Website(url)), null);
}
public class Website : INotifyPropertyChanged
{
public event Action<string> LinkParsed;
private string _网址;
private string _统计;
public string 网址
{
get { return _网址; }
private set
{
_网址 = value;
RefreshProperty("网址");
}
}
public string 统计
{
get { return _统计; }
private set
{
_统计 = value;
RefreshProperty("统计");
}
}
public Website(string url)
{
网址 = url;
统计 = "";
var browser = new WebBrowser { ScriptErrorsSuppressed = true, AllowNavigation = false, AllowWebBrowserDrop = false, IsWebBrowserContextMenuEnabled = false, ScrollBarsEnabled = false, WebBrowserShortcutsEnabled = false, };
new Action(() =>
{
browser.Navigating += (ss, ee) => 统计 = "抓取网页中...";
browser.DocumentCompleted += (ss, ee) =>
{
var text = StripHtml(browser.DocumentText);
var count = Count(text.Replace(" ",""));
统计 = count.ToString(CultureInfo.InvariantCulture);
if (LinkParsed != null)
{
if (browser.Document != null)
{
var firstLevelLinks = browser.Document.GetElementsByTagName("A");
var enume = firstLevelLinks.GetEnumerator();
while (enume.MoveNext())
{
var element = enume.Current as HtmlElement;
if (element != null)
{
var link = element.GetAttribute("href");
LinkParsed(link);
}
}
}
}
browser.Dispose();
};
try
{
browser.Navigate(url);
}
catch (Exception ex)
{
统计 = ex.ToString();
}
}).BeginInvoke(null, null);
}
private void RefreshProperty(string propertyName)
{
_synchronizationContext.Post(d =>
{
if (PropertyChanged != null)
PropertyChanged(this, new PropertyChangedEventArgs(propertyName));
}, null);
}
private static string StripHtml(string source)
{
string result;
// Remove HTML Development formatting
// Replace line breaks with space
// because browsers inserts space
result = source.Replace("\r", " ");
// Replace line breaks with space
// because browsers inserts space
result = result.Replace("\n", " ");
// Remove step-formatting
result = result.Replace("\t", string.Empty);
// Remove repeating spaces because browsers ignore them
result = System.Text.RegularExpressions.Regex.Replace(result,
@"( )+", " ");
// Remove the header (prepare first by clearing attributes)
result = System.Text.RegularExpressions.Regex.Replace(result,
@"<( )*head([^>])*>", "<head>",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
@"(<( )*(/)( )*head( )*>)", "</head>",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
"(<head>).*(</head>)", string.Empty,
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// remove all scripts (prepare first by clearing attributes)
result = System.Text.RegularExpressions.Regex.Replace(result,
@"<( )*script([^>])*>", "<script>",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
@"(<( )*(/)( )*script( )*>)", "</script>",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
//result = System.Text.RegularExpressions.Regex.Replace(result,
// @"(<script>)([^(<script>\.</script>)])*(</script>)",
// string.Empty,
// System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
@"(<script>).*(</script>)", string.Empty,
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// remove all styles (prepare first by clearing attributes)
result = System.Text.RegularExpressions.Regex.Replace(result,
@"<( )*style([^>])*>", "<style>",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
@"(<( )*(/)( )*style( )*>)", "</style>",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
"(<style>).*(</style>)", string.Empty,
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// insert tabs in spaces of <td> tags
result = System.Text.RegularExpressions.Regex.Replace(result,
@"<( )*td([^>])*>", "\t",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// insert line breaks in places of <BR> and <LI> tags
result = System.Text.RegularExpressions.Regex.Replace(result,
@"<( )*br( )*>", "\r",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
@"<( )*li( )*>", "\r",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// insert line paragraphs (double line breaks) in place
// if <P>, <DIV> and <TR> tags
result = System.Text.RegularExpressions.Regex.Replace(result,
@"<( )*div([^>])*>", "\r\r",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
@"<( )*tr([^>])*>", "\r\r",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
@"<( )*p([^>])*>", "\r\r",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// Remove remaining tags like <a>, links, images,
// comments etc - anything that's enclosed inside < >
result = System.Text.RegularExpressions.Regex.Replace(result,
@"<[^>]*>", string.Empty,
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// replace special characters:
result = System.Text.RegularExpressions.Regex.Replace(result,
@" ", " ",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
@"•", " * ",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
@"‹", "<",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
@"›", ">",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
@"™", "(tm)",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
@"⁄", "/",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
@"<", "<",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
@">", ">",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
@"©", "(c)",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
@"®", "(r)",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// Remove all others. More can be added, see
// http://hotwired.lycos.com/webmonkey/reference/special_characters/
result = System.Text.RegularExpressions.Regex.Replace(result,
@"&(.{2,6});", string.Empty,
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// for testing
//System.Text.RegularExpressions.Regex.Replace(result,
// this.txtRegex.Text,string.Empty,
// System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// make line breaking consistent
result = result.Replace("\n", "\r");
// Remove extra line breaks and tabs:
// replace over 2 breaks with 2 and over 4 tabs with 4.
// Prepare first to remove any whitespaces in between
// the escaped characters and remove redundant tabs in between line breaks
result = System.Text.RegularExpressions.Regex.Replace(result,
"(\r)( )+(\r)", "\r\r",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
"(\t)( )+(\t)", "\t\t",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
"(\t)( )+(\r)", "\t\r",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
result = System.Text.RegularExpressions.Regex.Replace(result,
"(\r)( )+(\t)", "\r\t",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// Remove redundant tabs
result = System.Text.RegularExpressions.Regex.Replace(result,
"(\r)(\t)+(\r)", "\r\r",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// Remove multiple tabs following a line break with just one tab
result = System.Text.RegularExpressions.Regex.Replace(result,
"(\r)(\t)+", "\r\t",
System.Text.RegularExpressions.RegexOptions.IgnoreCase);
// Initial replacement target string for line breaks
string breaks = "\r\r\r";
// Initial replacement target string for tabs
string tabs = "\t\t\t\t\t";
for (int index = 0; index < result.Length; index++)
{
result = result.Replace(breaks, "\r\r");
result = result.Replace(tabs, "\t\t\t\t");
breaks = breaks + "\r";
tabs = tabs + "\t";
}
// That's it.
return result;
}
private static int Count(string text)
{
return Encoding.Unicode.GetCharCount(Encoding.Unicode.GetBytes(text));
}
public event PropertyChangedEventHandler PropertyChanged;
}
}
}
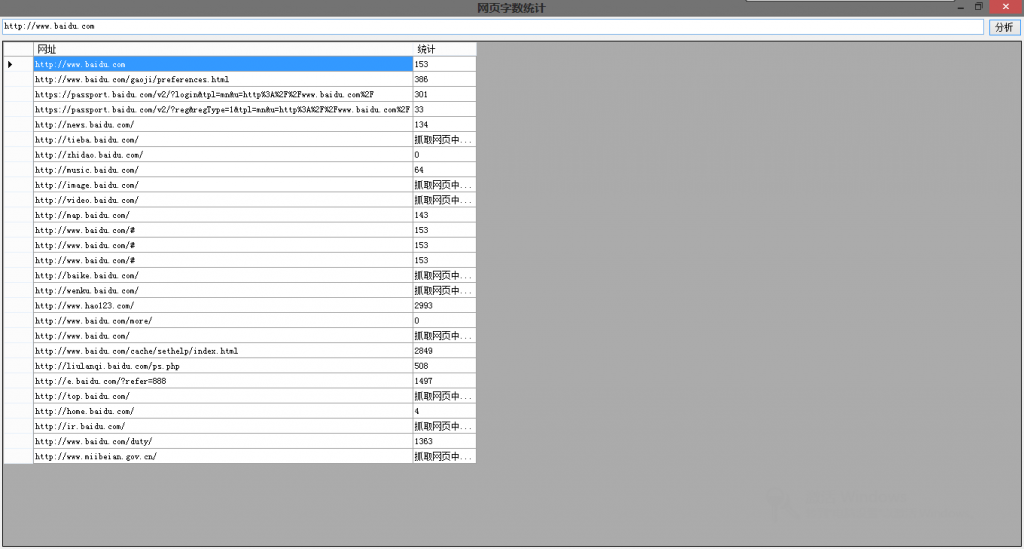
截图
勉強心を持てば、生活は虚しくない!
