
PythonI/O进阶学习笔记_10.python的多线程
content:
1. python的GIL
2. 多线程编程简单示例
3. 线程间的通信
4. 线程池
5. threadpool Future 源码分析
===========================
一. python的GIL
关于python的GIL,有一位博主写的我觉得真的挺好的,清晰明了通俗易懂。http://cenalulu.github.io/python/gil-in-python/
在这里就不赘述了,但是注意文章中的试验结论是基于python2的。python3中已经有所改进所以文中示例未必能得出当时相同的结论。
但是依旧对我们理解GIL很有帮助。
那总结下来什么是GIL呢?
global interpreter lock
python前期为了在多线程编程的时候更为简单,于是诞生了GIL。GIL使得同一时刻只有一个线程在一个cpu上执行字节码,无法将多个线程映射到多个cpu上。也就使得python无法实现真正意义上的多线程。
那是不是有了GIL是不是就绝对安全了?我们编码的时候就不需要考虑线程安全了?
并不是,GIL释放的时间可能那时候进程并没有执行完成。
GIL会在适当的时候释放,比如在字节码某特定行数以及特定时间片被释放,也会在遇到io操作的时候主动释放。
二. 多线程编程简单示例
想要实现开启线程执行任务,有两种方法,直接用Thread进行实例化,或者自己实现继承Thread的子类。
1.通过therad类实例化
这种情况适用于代码量比较少,逻辑比较简单的时候
import time import threading def get_detail_html(url): print("get detail html start") time.sleep(2) print("get detail html stop") def get_detail_url(url): print("url start") time.sleep(2) print("url end") if __name__=="__main__": thread1= threading.Thread(target=get_detail_html,args=("",)) thread2= threading.Thread(target=get_detail_url,args=("",)) start_time=time.time() # thread1.setDaemon() # thread2.setDaemon() thread1.start() thread2.start() thread1.join() thread2.join() print("lasttime :{}".format(time.time()-start_time)) pass
2.通过继承Thread来实现多线程(继承Thread,完成自己的thread子类)
按这种情况来写的话,我们就需要重载我们的run方法。(注意是run方法而不是start)
import time import threading class thread_get_detail_html(threading.Thread): def run(self): print("get detail html start") time.sleep(2) print("get detail html stop") class thread_get_detail_url(threading.Thread): def run(self): print("url start") time.sleep(2) print("url end") if __name__=="__main__": # thread1= threading.Thread(target=get_detail_html,args=("",)) # thread2= threading.Thread(target=get_detail_url,args=("",)) thread1=thread_get_detail_html() thread2=thread_get_detail_url() start_time=time.time() # thread1.setDaemon() # thread2.setDaemon() thread1.start() thread2.start() thread1.join() thread2.join() print("lasttime :{}".format(time.time()-start_time)) pass
以上就能发现,启动了两个线程分别执行了thread_get_detail_url和thread_get_detail_url。
三. 线程间的通信
实际上在二中,是在模拟一个简易爬虫的流程。先获取所有我们要爬取的url,然后再对每个url的html页面内容进行获取。那么这就涉及到一个问题了,thread_get_detail_url和thread_get_detail_html之间,需要thread_get_detail_url来的带一个url列表,而thread_get_detail_html也能获取这个url列表去进行操作。
这就涉及到线程间的通信了。
python中常用的线程间的这种需求的通信方式有:
- 全局变量
- Queue消息队列
假设我们现在继续来完成这个爬虫的正常逻辑。
1. 线程间的变量传递
1.1 全局变量
import time import threading detail_url_list=[] def get_detail_html(): global detail_url_list if len(detail_url_list)==0: return url=detail_url_list.pop() print("get detail html start :{}".format(url)) time.sleep(2) print("get detail html stop :{}".format(url)) def get_detail_url(): global detail_url_list print("url start") for i in range(20): detail_url_list.append("htttp://www.baidu.com/{id}".format(id=i)) time.sleep(2) print("url end") if __name__=="__main__": start_time=time.time() thread1= threading.Thread(target=get_detail_url) thread1.start() for i in range(10): thread_2=threading.Thread(target=get_detail_html) thread_2.start() print("lasttime :{}".format(time.time()-start_time)) pass
实际上,还可以更方便。将变量作为参数传递,在方法中就不需要global了。
import time import threading detail_url_list=[] def get_detail_html(detail_url_list): if len(detail_url_list)==0: return url=detail_url_list.pop() print("get detail html start :{}".format(url)) time.sleep(2) print("get detail html stop :{}".format(url)) def get_detail_url(detail_url_list): print("url start") for i in range(20): detail_url_list.append("htttp://www.baidu.com/{id}".format(id=i)) time.sleep(2) print("url end") if __name__=="__main__": start_time=time.time() thread1= threading.Thread(target=get_detail_url,args=(detail_url_list,)) thread1.start() for i in range(10): thread_2=threading.Thread(target=get_detail_html,args=(detail_url_list,)) thread_2.start() print("lasttime :{}".format(time.time()-start_time)) pass
但是这样是不能应用于多进程的。
还可以生成一个variables.py文件,直接import这个文件,这种情况变量过多的时候,这种方法比较方便。
但是如果我们直接import变量名,是不能看到其他进程对这个变量的修改的。
但是以上的方法都是线程不安全的操作。想要达到我们要的效果,就必须要加锁。所以除非对锁足够了解,知道自己在干嘛,否则并不推荐这种共享变量的方法来进行通信。
1.2 queue消息队列
a.queue实现上述
import time import threading from queue import Queue def get_detail_html(queue): url=queue.get() print("get detail html start :{}".format(url)) time.sleep(2) print("get detail html stop :{}".format(url)) def get_detail_url(queue): print("url start") for i in range(20): queue.put("htttp://www.baidu.com/{id}".format(id=i)) time.sleep(2) print("url end") if __name__=="__main__": start_time=time.time() url_queue=Queue() thread1= threading.Thread(target=get_detail_url,args=(url_queue,)) thread1.start() for i in range(10): thread_2=threading.Thread(target=get_detail_html,args=(url_queue,)) thread_2.start()
b.queue是如何实现线程安全的?
我们并不推荐1.1中直接用全局变量的方法,是因为需要我们自己花精力去维护其中的锁操作才能实现线程安全。而python的Queue是在内部帮我们实现了线程安全的。
queue使用了deque deque是在字节码的程度上就实现了线程安全的

c.queue的其他方法
get_nowait(立即取出一个元素,不等待)(异步)

put_nowait(立即放入一个元素,不等待)(异步)

join: 一直block住,从quque的角度阻塞住线程。调用task_done()函数退出。
2.线程间的同步问题
2.1 线程为什么需要同步?同步到底是个啥意思?
这是在多线程中,必须要面对的问题。
例子:我们有个共享变量total,一个方法对total进行加法,一个方法对加完之后的total进行减法。
如果循环对total进行加减的次数比较大的时候,就会比较明显的发现,每次运行的时候,得到的taotal可能是不一样的。
import threading total=0 def add(): global total for i in range(100000000): total += 1 def desc(): global total for i in range(100000000): total = total - 1 if __name__=="__main__": add_total=threading.Thread(target=add) desc_total=threading.Thread(target=desc) add_total.start() desc_total.start() add_total.join() desc_total.join() print(total)
为什么不会像我们希望的最后的total为0呢?
从字节码的角度上看,我们看看简化后的add和desc的字节码。
#input def add1(a): a += 1 def desc1(a): a -= 1 import dis print(dis.dis(add1)) print(dis.dis(desc1)) #output 22 0 LOAD_FAST 0 (a) 2 LOAD_CONST 1 (1) 4 INPLACE_ADD 6 STORE_FAST 0 (a) 8 LOAD_CONST 0 (None) 10 RETURN_VALUE None 25 0 LOAD_FAST 0 (a) 2 LOAD_CONST 1 (1) 4 INPLACE_SUBTRACT 6 STORE_FAST 0 (a) 8 LOAD_CONST 0 (None) 10 RETURN_VALUE None
从字节码来看流程为:#1.load a #2.load 1 #3.add #4.赋值给a
任何一步字节码都是有可能被切换出去另外一个线程的字节码去操作a,可能在1线程运行到4字节码(a和1相加)的时候,开始运行2线程的6字节码(赋值给a)。
类似的有银行存取钱、商品库存等也会有这个问题。
2.2 线程如何同步?
用锁将这段代码段锁住,锁住时,不进行切换。直接运行完这段代码段。
a.Lock和Rlock
threading中有提供lock。
import threading from threading import Lock total=0 lock=Lock() def add(): global total global lock for i in range(1000000): lock.acquire() total += 1 lock.release() def desc(): global total global lock for i in range(1000000): lock.acquire() total -= 1 lock.release() if __name__=="__main__": add_total=threading.Thread(target=add) desc_total=threading.Thread(target=desc) add_total.start() desc_total.start() add_total.join() desc_total.join() print(total) pass
注意acquire和release成对存在。运行的时候会发现比不加锁的时候慢比较多。所以其实锁的问题也很明显:锁会影响性能,锁会引起死锁。死锁里有个非常常见的问题资源竞争是很容易发生的。
那能不能我锁里套着锁呢?Lock方法是不可以的,但是threading提供了Rlock可重入锁。
Rlock在同一个线程里面,可以连续调用多次acquire,但是注意acquire和release也一定是要成对存在的。
from threading import RLock total=0 lock=RLock() def add(): global total global lock for i in range(1000000): lock.acquire() lock.acquire() total += 1 lock.release() lock.release()
3.condition使用以及源码分析
condition是条件变量,用于复杂的线程间同步。
3.1 condition的使用
例子:现有一个需求,要求 天猫精灵和小爱一人一句进行对话。如果我们现用lock来实现是没办法做到这边说完一句,那边就说一句的。所以有了condition。
在这个例子中,需要用到condition的两个重要方法 notify()和wait()。notify()用于通知这边动作完成,wait()用于阻塞住等待消息。
#input import threading class XiaoAi(threading.Thread): def __init__(self,cond): self.cond=cond super().__init__(name="小爱") def run(self): with self.cond: print("小爱: 天猫在吗 我是小爱") self.cond.notify() #小爱print完了,信号发送 self.cond.wait() #小爱等待接受信号 print("小爱: 我们来背诗吧") self.cond.notify() class TianMao(threading.Thread): def __init__(self,cond): self.cond=cond super().__init__(name="天猫") def run(self): with self.cond: self.cond.wait() print("天猫: 在 我是天猫") self.cond.notify() self.cond.wait() print("天猫: 好啊") self.cond.notify() if __name__=="__main__": condition=threading.Condition() xiaoai=XiaoAi(condition) tianmao=TianMao(condition) tianmao.start() xiaoai.start() #output: 小爱: 天猫在吗 我是小爱 天猫: 在 我是天猫 小爱: 我们来背诗吧 天猫: 好啊
ps:需要注意的是
- condition必须先with 再调用 notify和wait方法
- 这么写的时候,线程的start()顺序很重要
3.2 Condition源码分析
condition其实是有两层锁的。一把底层锁,会在线程调用了wait()的时候释放。
上层锁会在wait()的时候放入双端队列中,在调用notify()的时候被唤醒。
a.condition=threading.Condition()
condition初始化的时候申请了一把锁

b.self.cond.wait()
先释放了condition初始化的时候申请的底层锁,然后又申请了锁放入双端队列。

c. self.cond.notify()

4.信号量 semaphore
是可以用来控制线程执行数量的锁。
4.1 semaphore的使用
需求:现在有个文件,对文件可以进行读和写,但是写是互斥的,读是共享的。并且对读的共享数也是有控制的。
例:爬虫。控制爬虫的并发数。
import threading import time class HtmlSpider(threading.Thread): def __init__(self,url,sem): super().__init__() self.url=url self.sem=sem def run(self): time.sleep(2) print("got html text success") self.sem.release() class UrlProducer(threading.Thread): def __init__(self,sem): super().__init__() self.sem=sem def run(self): for i in range(20): self.sem.acquire() html_test=HtmlSpider("www.baidu.com/{}".format(i),self.sem) html_test.start() if __name__=="__main__": sem=threading.Semaphore(3) #设置控制的数量为3 urlproducer=UrlProducer(sem) urlproducer.start()
ps:
-
每acquire一次,数量就会被减少一,release的时候数量会自动回来。
-
需要注意sem释放的地方,应该是在HtmlSpider运行完之后进行释放。
4.2 semaphore源码
实际上semaphore就是对condition的简单应用。
a.sem=threading.Semaphore(3)

实际上就是在初始化的时候,调用了Condition。
b.self.sem.acquire()
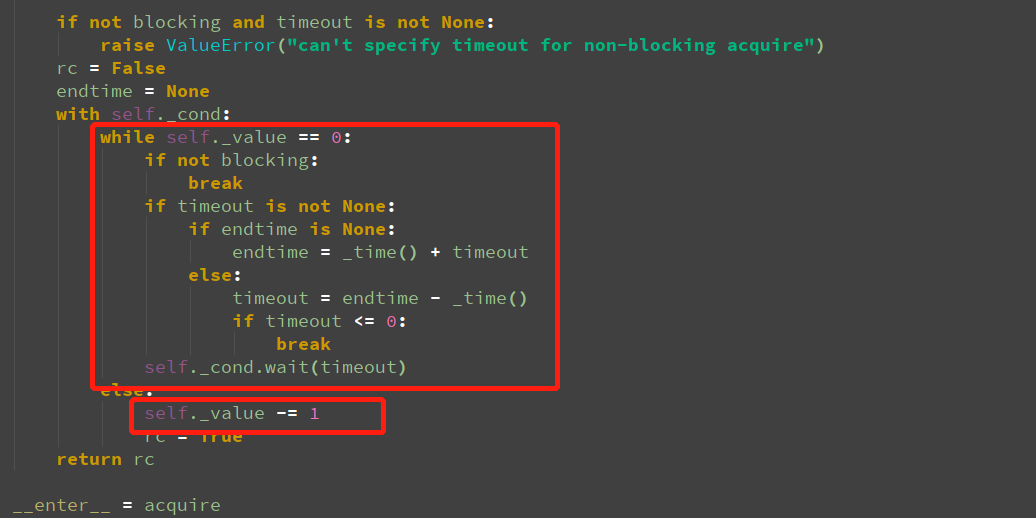
我们简单看这个逻辑就是,如果设置的数用完了,就让condition进入wait状态,否则就把数量减一。
c.self.sem.release()
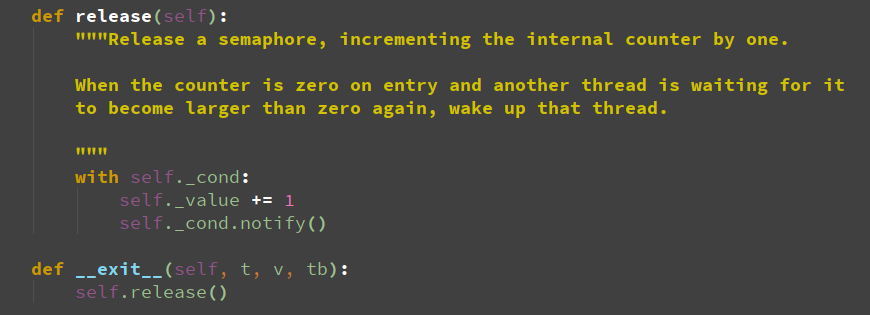
release 也是很简单的数量加一和condition的notify。
5.除了上述的对Condition的应用,queue模块中的Queue也对Condition做了更为复杂的应用。特别是queue中的put。
class Queue: def __init__(self, maxsize=0): self.maxsize = maxsize self._init(maxsize) 。。。 self.mutex = threading.Lock() self.not_empty = threading.Condition(self.mutex) self.not_full = threading.Condition(self.mutex) self.all_tasks_done = threading.Condition(self.mutex) self.unfinished_tasks = 0 def put(self, item, block=True, timeout=None): with self.not_full: if self.maxsize > 0: if not block: if self._qsize() >= self.maxsize: raise Full elif timeout is None: while self._qsize() >= self.maxsize: self.not_full.wait() elif timeout < 0: raise ValueError("'timeout' must be a non-negative number") else: endtime = time() + timeout while self._qsize() >= self.maxsize: remaining = endtime - time() if remaining <= 0.0: raise Full self.not_full.wait(remaining) self._put(item) self.unfinished_tasks += 1 self.not_empty.notify() 。。。。。。
四. 线程池
在前面进行线程间通信的时候,想要多个线程进行并发的时候,需要我们自己去维护锁。
但是我们现在希望有工具来帮我们对想要线程并发数进行管理。于是有了线程池。
那么为什么明明有了信号量 semaphore 还需要线程池呢?
因为线程池不只是控制了线程数量而已。
比如说,现在有需求,在主进程中,我们需要得到某个线程的状态。
并且线程的状态不管是退出还是什么,主进程能立刻知道。
futures让多线程和多进程的接口一致。
1.使用线程池
concurrent.futures中有两个类ThreadPoolExecutor和 ProcessPoolExecutor 分别用于线程池和进程池的创建,基类是futures的Executor类。
使用ThreadPoolExecutor只需要将要执行的函数和要并发的线程数交给它就可以了。
使用线程池来执行线程任务的步骤如下:
a.调用 ThreadPoolExecutor 类的构造器创建一个线程池。
b.定义一个普通函数作为线程任务。
c.调用 ThreadPoolExecutor 对象的 submit() 方法来提交线程任务。submit返回的是Future类(重要)。
d. 当不想提交任何任务时,调用 ThreadPoolExecutor 对象的 shutdown() 方法来关闭线程池。
#例:将之前爬虫模拟的脚本改为线程池用。 from concurrent.futures import ThreadPoolExecutor import time def get_html(times): time.sleep(times) print("get html page {} successed!".format(times)) return times excutor=ThreadPoolExecutor(max_workers=2) #submit 提交到线程池 #submit的返回很重要,返回的对象Future类可以判断这个函数的执行状态等 #submit 是非阻塞的 task1=excutor.submit(get_html,(3)) task2=excutor.submit(get_html,(2)) print(task1.done()) print(task2.done()) #result 是阻塞的,接受函数的返回 print(task1.result()) print(task2.result()) #output: False False get html page 2 successed! get html page 3 successed! 3 2
为什么done()输出的是false呢。因为submit的返回是非阻塞的,没有等task执行完就返回了task done的状态。
如果隔几秒输出done()的返回又是true了。
Future对象常用的其他方法:cancel()
取消该 Future 代表的线程任务。如果该任务正在执行,不可取消,则该方法返回 False;否则,程序会取消该任务,并返回 True。
print(task1.done()) print(task1.cancel()) print(task2.done()) #result 是阻塞的,接受函数的返回 print(task1.result()) print(task2.result()) output: False False False get html page 2 successed! get html page 3 successed! 3 2
cancelled():返回 Future 代表的线程任务是否被成功取消。
2.获取所有完成的future的状态和值as_completed和map
2.1 .as_complete
from concurrent.futures import ThreadPoolExecutor,as_completed import time def get_html(uid): time.sleep(uid) url="www.test.com/{}".format(uid) print("get url successed: \" {} \"".format(url)) return uid excutor=ThreadPoolExecutor(max_workers=2) uids=[5,2,3] future_list=[ excutor.submit(get_html,(uid)) for uid in uids] for future in as_completed(future_list): print(future.result()) #output: get url successed: " www.test.com/2 " 2 get url successed: " www.test.com/5 " 5 get url successed: " www.test.com/3 " 3
as_completed():yield 所有完成的futures的所有返回。
那么as_complete是如何做到收集所有完成的异步方法的状态的呢?
先把所有已经是finish状态的future返回,
再一直while pending,等待timeout范围内的future变成finish,把finish的future yield出来。
from concurrent.futures import ThreadPoolExecutor,as_completed import time def get_html(uid): time.sleep(uid) url="www.test.com/{}".format(uid) print("get url successed: \" {} \"".format(url)) return uid excutor=ThreadPoolExecutor(max_workers=2) uids=[5,2,3] future_list=[ excutor.submit(get_html,(uid)) for uid in uids] for future in as_completed(future_list): print(future.result()) #output: get url successed: " www.test.com/2 " 2 get url successed: " www.test.com/5 " 5 get url successed: " www.test.com/3 " 3
2.2 通过excutor的map方法 获取已经完成的future
excutor的map,和map是差不多的,传递函数和参数列表,就会多多线程运行参数列表数的线程。
与a中不一样的是,map返回的顺序和url中的顺序是一样的,而a的as_completed是谁先finishi谁就先被yield出来。
而且map返回的就是result,而as_completed返回的是Future。
from concurrent.futures import ThreadPoolExecutor,as_completed,wait import time def get_html(uid): time.sleep(uid) url="www.test.com/{}".format(uid) print("get url successed: \" {} \"".format(url)) return uid excutor=ThreadPoolExecutor(max_workers=2) uids=[5,2,3] result_list=excutor.map(get_html,uids) for result in result_list: print(result) #output: get url successed: " www.test.com/2 " get url successed: " www.test.com/5 " 5 2 get url successed: " www.test.com/3 " 3
3.wait()方法
wait方法用于阻塞,指定某一个task或者一些task执行完成再往下执行。
def wait(fs, timeout=None, return_when=ALL_COMPLETED)
例:如果我想在全部task执行完之后打印"task end"字符串
from concurrent.futures import ThreadPoolExecutor,as_completed,wait import time def get_html(uid): time.sleep(uid) url="www.test.com/{}".format(uid) print("get url successed: \" {} \"".format(url)) return uid excutor=ThreadPoolExecutor(max_workers=2) uids=[5,2,3] future_list=[ excutor.submit(get_html,(uid)) for uid in uids] print("task end") #output: task end get url successed: " www.test.com/2 " get url successed: " www.test.com/5 " get url successed: " www.test.com/3 "
#还没有执行完,就输出了 task end。需要加上: wait(future_list) print("task end") #output: get url successed: " www.test.com/2 " get url successed: " www.test.com/5 " get url successed: " www.test.com/3 " task end
wait还可以指定在什么时候执行完后返回。

五. threadpool Future 源码分析
这段源码我是真的很想认真通俗浅显的去分析的。因为在python的多进程和多线程中这个Future的概念是十分常见和重要的。
但是我发现我解释起来太苍白了,还没有直接去看源码来的通俗易懂。就在这放一小段入口的我自己的理解吧。
看完了上面几段笔记,肯定会有这些疑惑:
- submit返回的Future对象到底是啥?
Future是用来表示task的对象的一个类,很多人称为未来对象,就是这个任务未必现在执行完成了,但是未来是会执行完成的。
得到了Future对象,能通过其中的属性和方法得到task的状态,是否执行完成等。
在python的多线程、多进程中,很多地方用到了Future概念。
具体属性可以去看Class Future中的属性和方法。
- 那么Future这个对象是怎么设计的呢?Future怎么知道task的状态改变的呢?
在之前的例子里,我们用ThreadPoolExecutor的submit提交所有的task,返回了Future对象。
那么submit对Future对象的哪些属性进行了哪些处理然后返回,才能让我们得到它的result的呢?
submit的源码:最主要的逻辑是注释了的那几句。
def submit(self, fn, *args, **kwargs): with self._shutdown_lock: if self._broken: raise BrokenThreadPool(self._broken) if self._shutdown: raise RuntimeError('cannot schedule new futures after shutdown') if _shutdown: raise RuntimeError('cannot schedule new futures after' 'interpreter shutdown') f = _base.Future() #初始化一个future对象f w = _WorkItem(f, fn, args, kwargs) #实际上是这个_WorkItem把(future对象,执行函数,函数需要的参数)放进去的,并且完成函数的执行,并且设置future的result self._work_queue.put(w) #将w这个task放入 _work_queue队列,会在下面这个方法中,被起的Thread进行调用。 self._adjust_thread_count() #调整线程数量,并且初始化线程,开启线程。Thread方法的参数是self._work_queue。起来的线程中执行的task是上两步生成的w队列。 return f

 浙公网安备 33010602011771号
浙公网安备 33010602011771号