Flink精确消费一次
在大数据计算里面,计算引擎是处于承上启下的作用,对上承接数据源,对下承接各种各种数据库,比如mysql、oracle。对于任何数据计算来说要想精确消费一次,就需要支持事务或者幂等,我们最常见的支持事务的就是单点的oracle、mysql数据库,那么Flink作为分布式计算引擎,是如何做到精确消费一次的呢?
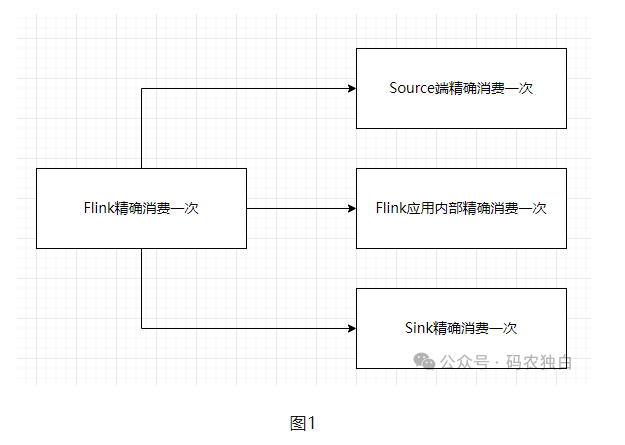
Source端的精确消费一次比较好实现,毕竟Flink是消费者,比如它消费Kafka时,它可以记录下相关的偏移量,恢复时重置偏移量就可以了,Flink应用内部就是通过checkpoint机制来实现精确一次的,难点是sink端如何保证精确消费一次,毕竟数据写到外部系统后,Flink就无法管控了,目前针对sink端是kafka的情况时,是通过两段提交(预提交、正式提交)的方式来实现的,所以理论上提供了必要的协调机制的三方系统,都是可以实现精确一次的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号