kafka数据一致性
kafka作为商业级中间件,它在设计时优先考虑的可靠性、可用性,同时兼顾一致性,这是所有分布式都会遇到的cap理论,kafka也不例外;可靠性通过副本机制解决,可用性通过leader和follower机制来解决。
kafka的可靠性,根据ack的设置不同,可靠性不同,ack=-1可靠性最高,但效率会稍微低一点。
acks=0:生产者不会等待任何来自服务器的响应,直接不断发送数据。 acks=1(默认值):只要集群的Leader节点收到消息,生产者就会收到一个来自服务器的成功响应。 acks=-1:只有当所有参与复制的节点全部都收到消息时,生产者才会收到一个来自服务器的成功响应。
kafka的可用性,通过维护AR,ISR,OSR来确保当leader挂掉后,可以马上从 ISR 列表中选择第一个 follower 作为新的 Leader。
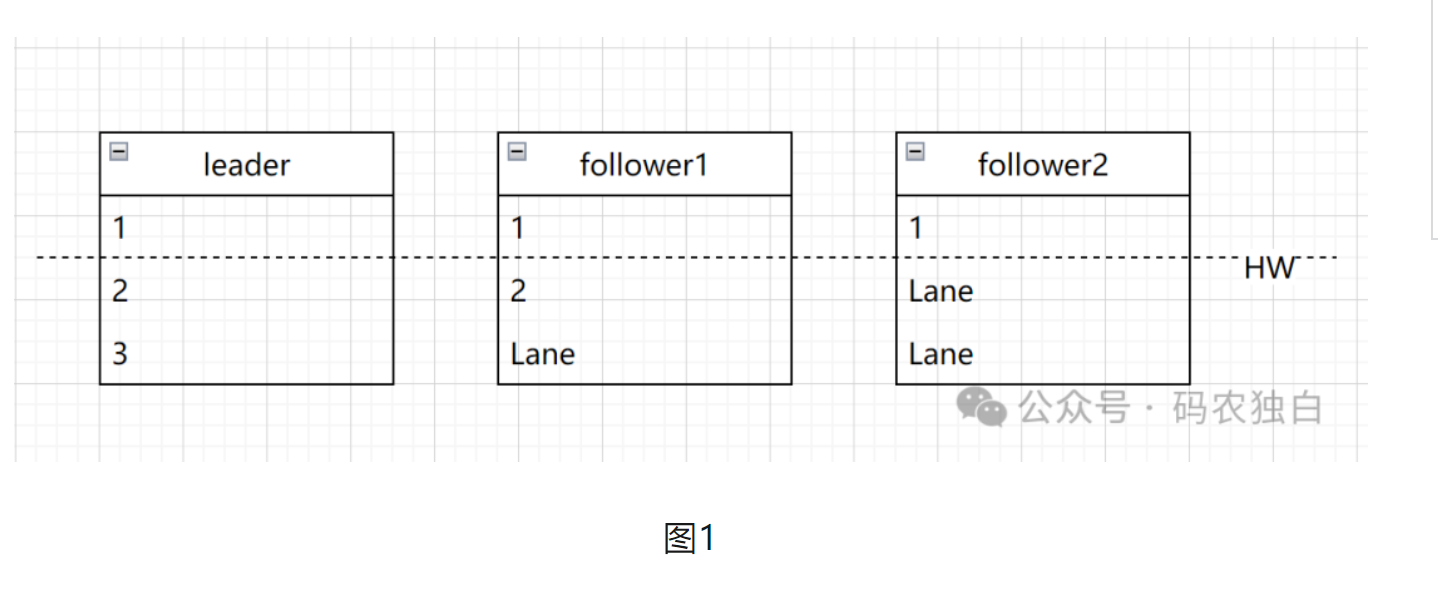
当kafka副本为多副本时,副本是定期从leader同步数据,定期同步必然会导致leader和follower数据不一致的情况出现。为了解决这种不一致,kafka引入了HW(高水位线),高水位线HW = ISR副本中最小LEO(副本的最大消息偏移量+1),如下图1所示的HW=2,因为follower2的消息还是1,所以这个时候消费者只能消费小于2的数据,那就是只能消费1这条数据,这样就能保证消费者所见一致性问题。
由于HW总是要在下一次fetch rpc才会更新,所以HW也有可能出现同步不及时的情况,导致数据丢失,所以这里就又要提到leader epoch。
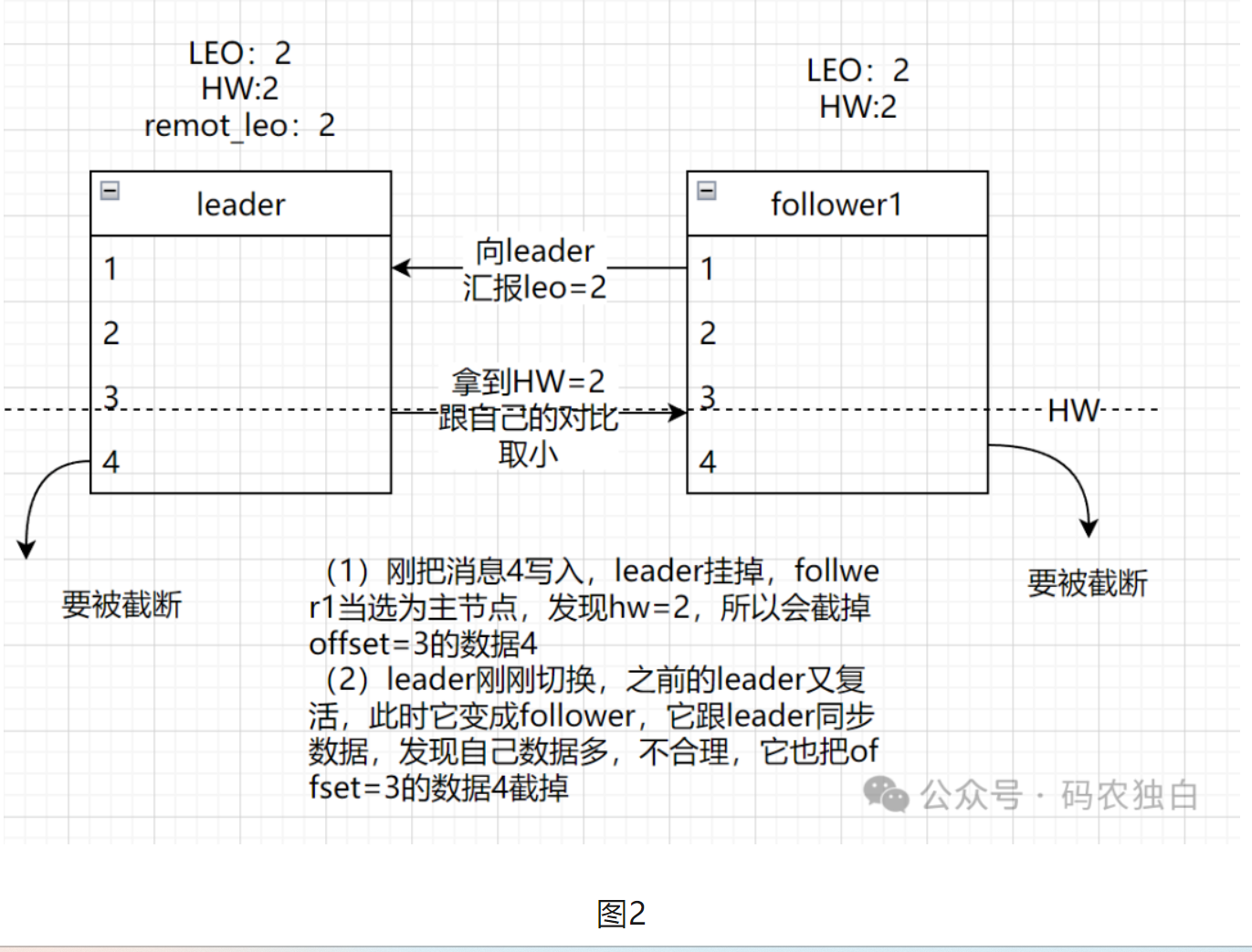
leader epoch会记录leader的生平,他的纪元值,比如图2的leader没有挂掉时,它会记录(0,3),表示第0代leader,目前offset=3,当follower1当选为leader后,此时epoch为1,会跟上一个纪元的offset进行比对,以此判断是否需要截取数据。如下图三就不需要截取数据,从而保证数据一致性。
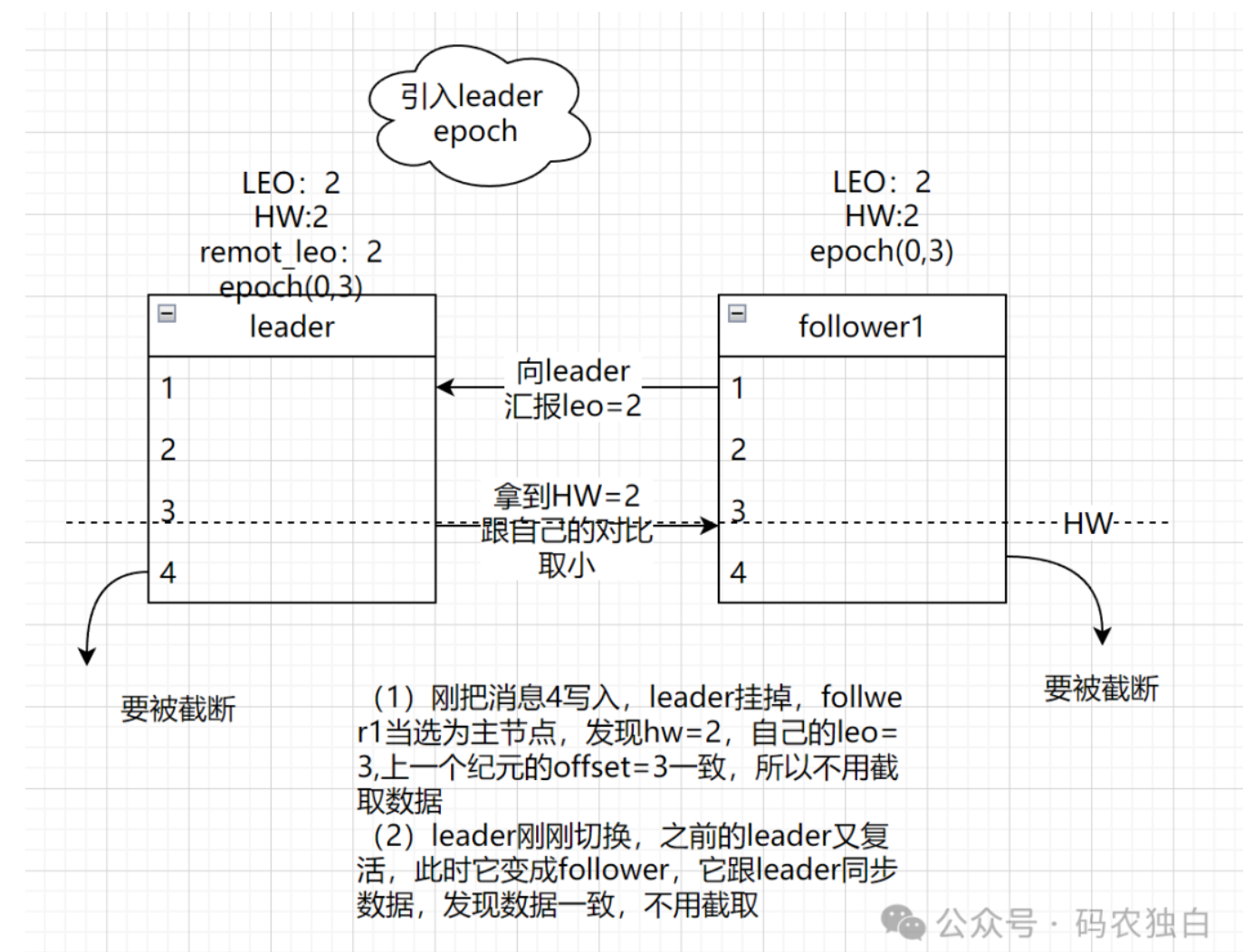
图3


 浙公网安备 33010602011771号
浙公网安备 33010602011771号